【论文简述】Rethinking Cross-Entropy Loss for Stereo Matching Networks(arxiv 2023)
一、论文简述
1. 第一作者:Peng Xu
2. 发表年份:2023
3. 发表期刊:arxiv
4. 关键词:立体匹配,交叉熵损失,过渡平滑和不对准问题,跨域泛化
5. 探索动机:立体匹配通常被认为是深度学习中的一个回归任务,通常采用平滑L1损失结合Soft-Argmax估计器来训练网络,达到亚像素级的视差精度。然而,平滑L1损失缺乏对代价体的直接约束,在训练过程中容易出现过拟合。Soft-Argmax是基于网络输出以ground-truth为中心的单模态视差分布的假设,这并不总是正确的,特别是对于具有模糊深度的边缘像素。在这种非单峰分布上应用SoftArgmax会导致严重的过度平滑问题,在边缘产生出伪影。
另一种研究将立体匹配作为分类任务,并采用交叉熵作为损失函数。它提供了对代价体的直接监督,通常比回归方法能取得更好的结果。结合基于单峰加权平均的视差估计器,可以有效地缓解过平滑问题。然而,交叉熵损失的主要问题是无法获得立体匹配的真值分布。现有方法采用以拉普拉斯分布或高斯分布为模型,在标量真值附近拟合单峰分布。然而这些单模态交叉熵损失仍然倾向于在边缘像素上产生类似的多模态分布,这使得很难选择出正确的峰值进行进一步处理。在这种不明确的分布上执行单模态视差估计可能会在物体边界上产生不对齐的结果。
6. 工作目标:工作旨在为交叉熵损失建立一个更好的真值分布模型,并改进视差估计。首先通过实验证明,正确的边缘监督是具有挑战性的,但也很重要,因为它不仅影响边缘像素的性能,也影响非边缘像素的性能。实际上,由于边缘像素的强度变化可以建模为斜率,因此很难武断地说它们属于前景还是背景。因此,认为双峰分布更适合于拟合边缘处的真值。此外,还应该考虑到模态的相对高度,这反映了在输出分布中选择正确峰值的困难程度。
7. 核心思想:提出了一种自适应多模态分布来拟合交叉熵损失中的真值。
- We experimentally demonstrate the importance of correct edge supervision to the stereo matching problem;
- We propose an adaptive multi-modal cross-entropy loss for network training. It can effectively reduce the ambiguous output distributions;
- We optimize the disparity estimator to obtain more robust disparity results during inference;
- Classic models trained with our method can regain highly competitive performance;
- Without any additional design on domain generalization, our method exhibits excellent synthetic-to-realistic crossdomain generalization.
8. 实验结果:
- Since November 2022, GANet trained with our method achieves state-of-the-art performance on SceneFlow test set and ranks 1st on both the KITTI 2015 and KITTI 2012 benchmarks, as shown in Fig. 2. Meanwhile, our method shows excellent cross-domain generalization ability and surpasses existing methods that specialize in generalization.
- We also conduct experiments on the impact of ground-truth density to the model performance, which is important for realworld outdoor stereo applications since only sparse LiDAR can be used as the ground-truth. Our model shows superior robustness than the baseline methods.
9.论文下载:
https://arxiv.org/abs/2306.15612
https://github.com/xxxupeng/Adaptive-Multi-Modal-Cross-Entropy-Loss
二、实现过程
1. 基本原理和问题陈述
给定一个校准过的立体图像对,目标是左边图像中的每个像素找到右边图像中对应的像素。根据聚合阶段使用的卷积方法,可分为2D-Conv模型和3D-Conv模型两类。后者通常可以获得比前者更好的结果,但代价是更高的计算复杂度。3D-Conv模型共用一条管道,如图所示。

首先,通过权重共享的2D CNN模块分别提取左右图像的特征。然后在得到的两个特征块上构造4D代价体。代价聚合模块将这个4D体作为输入,输出一个D×H×W体,其中D为视差搜索的最大范围,H和W分别是输入图像的高度和宽度。然后对D维进行Softmax运算,得到视差分布p(·)。最后,通过加权平均运算估计亚像素精度的视差d,也称为Soft-Argmax:

对于训练,通常采用基于回归的光滑L1损失,如:
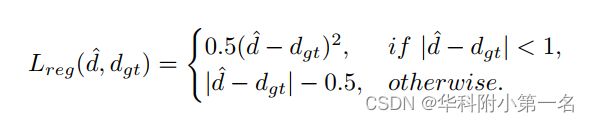
其中Dgt是真实视差。
如图所示,平滑L1损失的问题是分布体不受ground-truth的直接监督,这可能导致训练过程中出现一定程度的过拟合。因此,探索对分布体进行更直接的监督来缓解这一问题是很自然的。将立体匹配作为一个分类任务,交叉熵损失如式所示,是直接监督分布体的一个很好的选择:

与交叉熵损失相关的新问题是,基真差不是整数,且其在式中的分布pgt(·)不可用。一些工作采用高斯或拉普拉斯模型将标量的真值视差变换为离散分布。它们直接在groundtruth周围生成所有像素的单模态分布,以满足pgt(·)的要求。然而,这个简单的模型似乎不能对图像上的像素施加平等的监督。在SceneFlow上分别记录了边缘和非边缘像素的训练损失,并绘制在图中。

可以看到,边缘像素的损失下降得更慢,并且仍然比非边缘像素的损失大得多,这意味着边缘像素的学习要比其他像素困难得多。将其归因于边缘的不当监管。实际上,由于边缘像素的强度变化通常可以建模为斜率,因此很难武断地说是否它们属于前景或背景。简单的单模态假设会在ground-truth上产生额外的噪声,导致比纯样本更大的训练损失。为了检验噪声边缘真值对最终精度的影响程度,将边缘真值视差替换为在整个视差范围内均匀分布产生的随机噪声,并将其与其他配置进行比较。

如表所示,在训练过程中去除边缘监督只会导致边缘和所有区域的性能略有下降。然而,向网络中添加错误的边缘监督会导致边缘和非边缘像素的性能急剧下降,所有像素的EPE分别从0.84像素到1.14像素,1px误差从6.65%到8.03%。然而,如果在整个图像上分配相同百分比的噪声标签,则可以大大减少负面影响。这个实验清楚地表明了正确的边缘监督对最终精度的重要性。它不仅影响边缘像素的精度,而且影响非边缘像素的精度。这一惊人的发现激发去探索更好地模拟边缘的真值分布。
2. 自适应多模态交叉熵损失
Arpit等人指出,神经网络倾向于优先学习简单清晰的模式。对于立体匹配,很难直观地区分像素是否在边缘属于前景或背景。一方面,由于光敏元件同时接收来自前景和背景的混合光,边缘像素在一定程度上模糊。另一方面,在立体网络的特征提取阶段通常会降低空间分辨率,从而进一步模糊边缘像素的特征。因此,有理由相信边缘像素的实际分布应该至少有两个峰值,而不是一个,每个峰值分别以前景和背景差为中心。
为此,提出了一种从真值视差图中自适应生成多模态真值分布的方法。从每个像素的邻域中提取边缘和结构信息。前者决定分布中模态的数量,后者决定每个模态之间的相对高度。下图显示了交叉熵损失的自适应多模态真值分布的生成过程。左列显示输入图像,下面是部分放大图像。以非边缘像素(橙色)和边缘像素(绿色)为中心的两个大小为3 × 3的邻域为例。右列显示了基于邻域内像素的统计数据生成的不同模态。对于非边缘像素,生成单模态拉普拉斯分布。而对于边缘像素,邻域内的9个差异被聚为两类(背景和前景),随后用于生成双峰拉普拉斯分布。

具体来说,选择以ground-truth视差图中每个像素为中心的大小为m×n的邻域。然后,计算这mn个像素的平均视差。如果平均值和中心时差之间的差值在阈值λ内,则认为该像素位于非边缘区域,否则视为边缘像素。对于非边缘像素,认为真值分布是单模态的,并将其与softmax形成的拉普拉斯分布拟合,如下:

其中,位置参数µ设为视差groundtruth, b为尺度参数。
对于边缘像素,认为真值分布是双峰的。使用两个以上的峰对最终结果影响不大,后面的实验部分中已证明。对于边缘像素,由于前景和背景之间存在明显的视差差距,邻域内的视差很容易被划分为两个簇。假设聚类P1包含中心像素,P2为剩余聚类,将这些聚类拟合为双峰拉普拉斯分布,为:

在式中,µ1,µ2是P1、P2中视差的均值,b1、b2分别是控制模态锐度的尺度参数。为了确保主模态的准确性,µ1被中心地真实视差取代。权重参数w负责根据结构统计调整两模态的相对高度。将P1中的像素数作为局部结构的指示器。例如,P1中像素量越小,对应的结构越薄,这意味着应该相应降低ground-truth的置信度。最后,确定式中的w为:
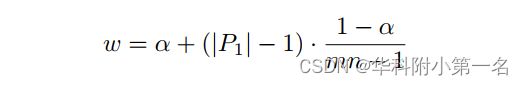
其中|P1|表示P1中的像素个数,α为中心像素的固定权值,其余(1−α)权值均匀分布到相邻像素。对于非边缘像素的式可以当|P1| = mn且P2为空时,可视为上式中的特例。
3. 主模态视差估计
推断出的视差分布趋向于与真值分布一致,这是工作中的自适应多模态。给定推断的分布,需要对它们进行后处理以获得最终的视差结果。通过对主导模态内的视差候选进行加权平均操作来估计结果。然而,在确定主态范围方面与Chen等人有所不同。Chen等人首先以最大概率找到候选差值,然后分别向左和向右遍历,直到概率不再减小,从而确定主模态的范围[dl, dr]。然而,在如下图所示的多模态分布不明确的情况下,应用该方法容易错误地定位主导峰,产生视差异常值。下图所示网络的三个典型输出。从上到下:单峰分布,易分辨的双峰分布,峰高相近的模糊双峰分布。对于第三种方法,单模态视差估计器提取候选概率最大的模态,而我们的主模态估计器提取累积概率更大的模态。
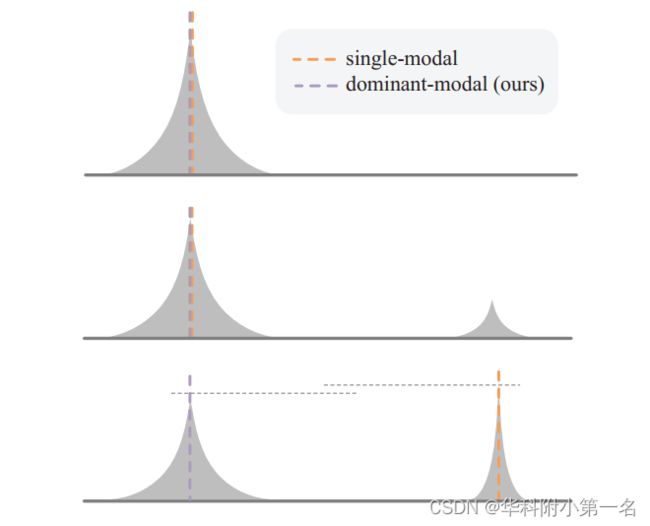
为了避免这个问题,提出了一种基于累积概率的模态选择方法。具体来说,首先采用均值滤波器平滑推断后的视差分布。然后比较峰值的累积概率,找出最大的峰值作为主导峰。接下来,将主导峰的分布归一化为:

请注意,归一化是在原始输出分布p(·)的峰值上进行的,而不是在平滑的峰值上进行的,以保持视差估计的准确性。最后,对选择的主模态进行加权平均运算,得到p(·)的最终差值。