计算机视觉技术-锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。 不同的模型使用的区域采样方法可能不同。 这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。
首先,让我们修改输出精度,以获得更简洁的输出。
%matplotlib inline
import torch
from d2l import torch as d2l
torch.set_printoptions(2) # 精简输出精度生成多个锚框
假设输入图像的高度为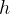 ,宽度为
,宽度为 。 我们以图像的每个像素为中心生成不同形状的锚框:缩放比为
。 我们以图像的每个像素为中心生成不同形状的锚框:缩放比为 ∈(0,1],宽高比为
∈(0,1],宽高比为 >0。 那么锚框的宽度和高度分别是
>0。 那么锚框的宽度和高度分别是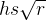 和
和![]() 。 请注意,当中心位置给定时,已知宽和高的锚框是确定的。
。 请注意,当中心位置给定时,已知宽和高的锚框是确定的。
也就是说,以同一像素为中心的锚框的数量是![]() 。 对于整个输入图像,将共生成
。 对于整个输入图像,将共生成![]() 个锚框。
个锚框。
上述生成锚框的方法在下面的multibox_prior函数中实现。 我们指定输入图像、尺寸列表和宽高比列表,然后此函数将返回所有的锚框。
#@save
def multibox_prior(data, sizes, ratios):
"""生成以每个像素为中心具有不同形状的锚框"""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # 处理矩形输入
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)可以看到返回的锚框变量Y的形状是(批量大小,锚框的数量,4)。
img = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[:2]
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape561 728
torch.Size([1, 2042040, 4])
tensor([0.06, 0.07, 0.63, 0.82])
为了显示以图像中以某个像素为中心的所有锚框,定义下面的show_bboxes函数来在图像上绘制多个边界框。
#@save
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""显示所有边界框"""
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))正如从上面代码中所看到的,变量boxes中 轴和
轴和 轴的坐标值已分别除以图像的宽度和高度。 绘制锚框时,我们需要恢复它们原始的坐标值。 因此,在下面定义了变量
轴的坐标值已分别除以图像的宽度和高度。 绘制锚框时,我们需要恢复它们原始的坐标值。 因此,在下面定义了变量bbox_scale。 现在可以绘制出图像中所有以(250,250)为中心的锚框了。 如下所示,缩放比为0.75且宽高比为1的蓝色锚框很好地围绕着图像中的狗。
d2l.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5'])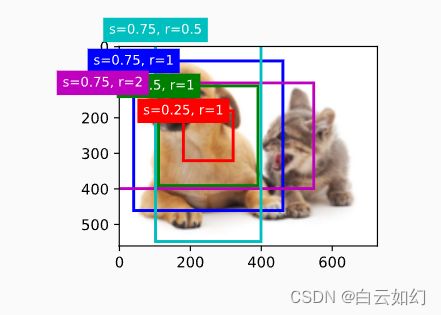
交并比(IoU)
我们刚刚提到某个锚框“较好地”覆盖了图像中的狗。 如果已知目标的真实边界框,那么这里的“好”该如何如何量化呢? 直观地说,可以衡量锚框和真实边界框之间的相似性。 杰卡德系数(Jaccard)可以衡量两组之间的相似性。 给定集合 和
和 ,他们的杰卡德系数是他们交集的大小除以他们并集的大小。
,他们的杰卡德系数是他们交集的大小除以他们并集的大小。
事实上,我们可以将任何边界框的像素区域视为一组像素。通 过这种方式,我们可以通过其像素集的杰卡德系数来测量两个边界框的相似性。 对于两个边界框,它们的杰卡德系数通常称为交并比(intersection over union,IoU),即两个边界框相交面积与相并面积之比,如下图所示。 交并比的取值范围在0和1之间:0表示两个边界框无重合像素,1表示两个边界框完全重合。
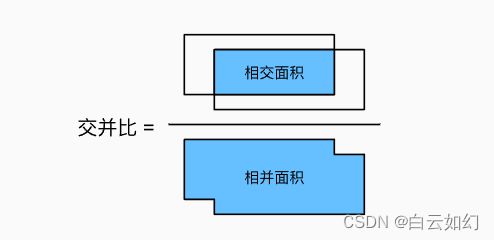
接下来部分将使用交并比来衡量锚框和真实边界框之间、以及不同锚框之间的相似度。 给定两个锚框或边界框的列表,以下box_iou函数将在这两个列表中计算它们成对的交并比。
#@save
def box_iou(boxes1, boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# boxes1,boxes2,areas1,areas2的形状:
# boxes1:(boxes1的数量,4),
# boxes2:(boxes2的数量,4),
# areas1:(boxes1的数量,),
# areas2:(boxes2的数量,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# inter_upperlefts,inter_lowerrights,inters的形状:
# (boxes1的数量,boxes2的数量,2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasandunion_areas的形状:(boxes1的数量,boxes2的数量)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas