机器学习(二) -- 数据预处理(2)
系列文章目录
机器学习(一) -- 概述
机器学习(二) -- 数据预处理(1-3)
未完待续……
目录
系列文章目录
前言
三、【数据清洗】
1、缺失数据的检测与处理
1.1、检测与统计
1.2、处理
1.1.1、删除缺失值(慎用)
1.1.1、填充缺失值
2、异常数据的检测与处理
1.2、检测
1.1.1、散点图方法
1.1.1、箱线图分析
1.1.1、3σ法则
1.2、处理
1.1.1、不处理
1.1.1、删除
1.1.1、修改
1.1.1、转换
3、重复数据的检测与处理
1.2、记录重复
1.2、特征重复
机器学习(二) -- 数据预处理(1)
机器学习(二) -- 数据预处理(3)
前言
tips:这里只是总结,不是教程哈。本章开始会用到numpy,pandas以及matplotlib,这些就不在这讲了哈。
“***”开头的是给好奇心重的宝宝看的,其实不太重要可以跳过。
此处以下所有内容均为暂定,因为我还没找到一个好的,让小白(我自己)也能容易理解(更系统、嗯应该是宏观)的讲解顺序与方式。
第一文主要简述了一下机器学习大致有哪些东西(当然远远不止这些),对大体框架有了一定了解。接着我们根据机器学习的流程一步步来学习吧,掐掉其他不太用得上我们的步骤,精练起来就4步(数据预处理,特征工程,训练模型,模型评估),其中训练模型则是我们的重头戏,基本上所有算法也都是这一步,so,这个最后写,先把其他三个讲了,然后,在结合这三步来进行算法的学习,兴许会好点(个人拙见)。
三、【数据清洗】
数据异常大致分为三种情况,缺失数据、异常数据(噪声数据)、重复数据。
通过填写缺失的值、光滑噪声数据、识别或删除离群点并解决不一致性来“清理”数据。主要是达到如下目标:格式标准化,异常数据清除,错误纠正,重复数据的清除。
1、缺失数据的检测与处理
1.1、检测与统计
1.1.1、利用isnull()函数
(只是想查看每列的缺失值情况,info()更方便)
测试数据:
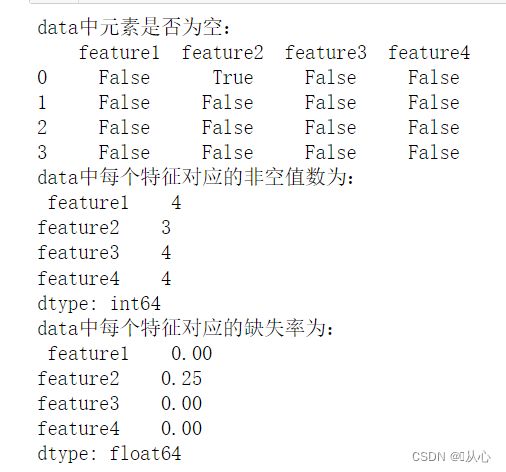
# 检测
print('data中元素是否为空:\n', data.isnull())
# print('data中元素是否为非空:\n', data.notnull())
# 统计
print('data中每个特征对应的非空值数为:\n', data.count())
# print('data中每个特征对应的非空值数为:\n', data.notnull().sum())
print('data中每个特征对应的缺失率为:\n', 1-data.count()/len(data))
# print('data中总非空值数为:\n', data.count().sum())
# # print('data中为空值的总个数:\n',data.isnull().sum().sum())
# print('data中总缺失率为:\n', 1-data.count().sum()/(len(data)*len(data.columns)))结果:isnill()和notnull()对每个值进行判断,并给出结果(备注掉的有些结果是一样的,就是写法不同,可以参考一下,发散一下思维。)
1.1.1、利用info()函数
# 缺失值的统计
# 利用info()方法查看DataFrame的缺失值
print(data.info())info()就比较直接了,
第一行,告诉我们“data”是一个DataFrame对象
第二行,告诉我们样本范围有4个,从0到3
第三行以及表格,告诉我们有4列(每列一个特征),每个特征的非缺失值情况,如feature2有3个非缺失值
(其他的···请字面理解,也不重要)

1.2、处理
1.1.1、删除缺失值(慎用)
# 删除缺失值
data1=data.dropna()
print(data1)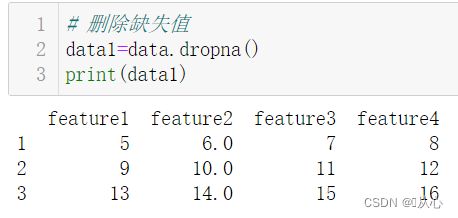
dropna()函数:删除具有缺失值的行。
how:确定缺失值个数,默认how='any’表明,只要某行有缺失值就将该行丢弃;
how='all’表明某行全部为缺失值才将其丢弃。
.dropna(axis = 0,how = 'any', thresh = None, subset = None, inplace = False)
1.1.1、填充缺失值
一般用该列平均值填充(当然还有其他很多方法,用0、最大值、中位数等填充)
# 填充缺失值
data2=data.fillna(1)
# data2=data.replace(np.nan,1)
print(data2)
data2=data.fillna(data.mean())
print(data2)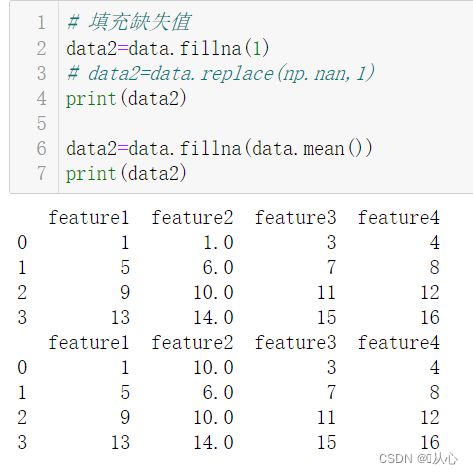
fillna():缺失值替换。
value:用于填充缺失值的标量值或字典对象
method:插值方式,ffill向前填充(向下,front fill),bfill向后填充(向上,back fill)
.fillna(value=None,method=None,axsi=None,inplace=False,limit=None)
# 填充缺失值
# 向后填充
data3=data.fillna(method='bfill')
print(data3)
data3.iloc[2,2]=None
print(data3)
# 向前填充
data4=data3.fillna(method='ffill')
print(data4)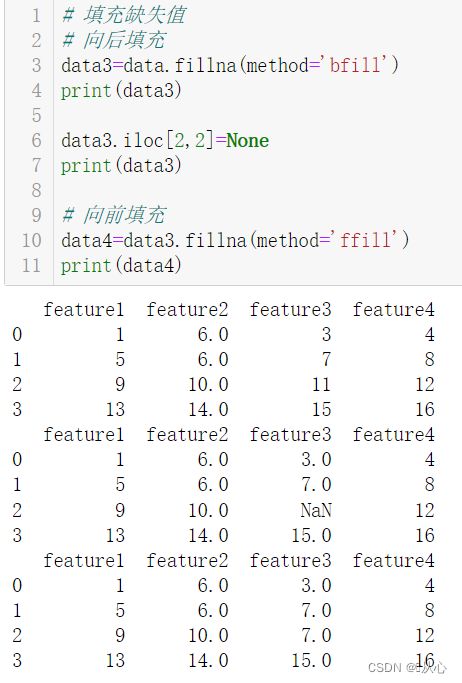
2、异常数据的检测与处理
1.2、检测
1.1.1、散点图方法
# 测试数据制作
data=pd.DataFrame(np.arange(12),columns=['x'])
data['y']=data['x']*1.2+1.2
data.iloc[1,1]=134
data.iloc[6,1]=143
print(data)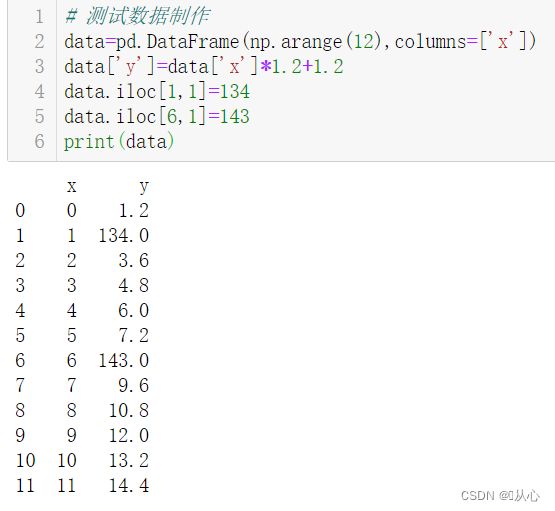
一目了然,有没有。
# 绘图法
plt.scatter(data['x'],data['y'],c='k',marker='.')
# plt.scatter(data.iloc[:,0],data.iloc[:,1],c='k',marker='.')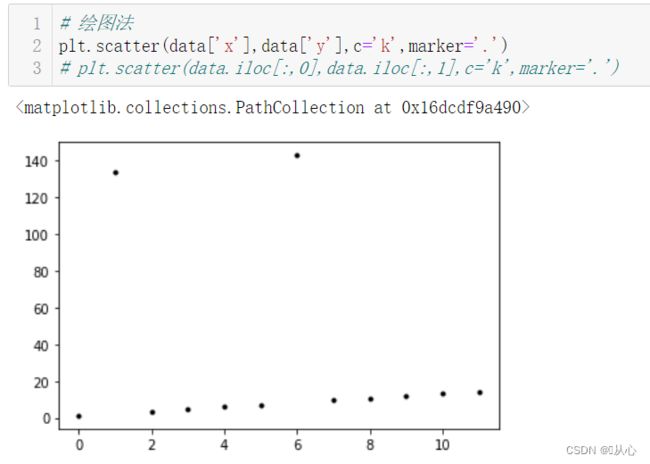
1.1.1、箱线图分析
原理与概念:
5个四分位点:数值大小从小到大排序,分别在开头(最小),25%位置的数(下四分位),中位数,75%位置的值(上四分位),结尾(最大值)的值,分别为Q0,Q1,Q2,Q3,Q4
四分位距(IQR):Q3-Q1得到的数
然后将最大、最小值设置为min=Q1-1.5IQR,max=Q3+1.5IQR,不在[min,max]的值被认为是异常值。
# 利用箱型图的四分位距(IQR)对异常值进行检测
Percentile = np.percentile(data['y'], [0, 25, 50, 75, 100]) # 计算百分位数
IQR = Percentile[3] - Percentile[1] # 计算箱型图四分位距
UpLimit = Percentile[3]+IQR*1.5 # 计算临界值上界
DownLimit = Percentile[1]-IQR*1.5 # 计算临界值下界
# 判断异常值,大于上界或小于下界的值即为异常值
abnormal = [i for i in data['y'] if i >UpLimit or i < DownLimit]
print('IQR检测出的y中异常值为:\n', abnormal)
print('IQR检测出的异常值比例为:\n', len(abnormal)/len(data['y']))
1.1.1、3σ法则
这玩意就和数学的正态分布有关了,
简单来讲,超出的【μ±3σ】的值就为异常值。(μ是均值,σ是标准差)
data.iloc[1,1]=2.4
# 利用3sigma原则对异常值进行检测
y_mean = data['y'].mean() # 计算均值
y_std = data['y'].std() # 计算标准差
UpLimit = y_mean+y_std*3 # 计算临界值上界
DownLimit = y_mean-y_std*3 # 计算临界值下界
y_cha = data['y'] - y_mean # 计算元素与平均值之差
# 返回异常值所在位置
ind = [i for i in range(len(y_cha)) if np.abs(y_cha[i])>y_std*3]
abnormal = [data['y'][i] for i in ind] # 返回异常值
print('3sigma原则检测出的y中异常值为:\n', abnormal)
print('3sigma原则检测出的异常值比例为:\n', len(abnormal)/len(data['y']))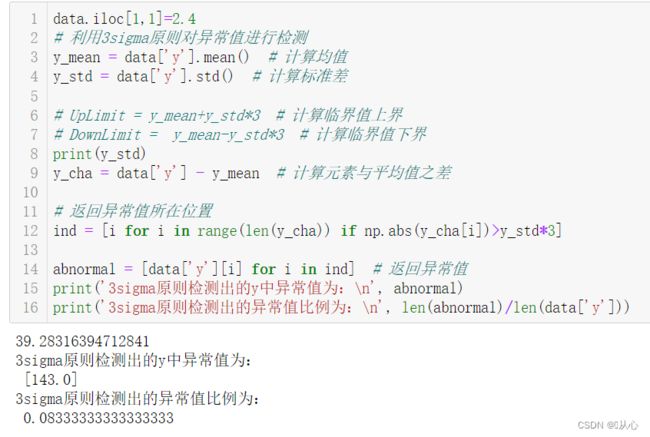
之所以我要修改上面,有一个异常值的数据,是因为我这里数据量太少,异常值又大占比也偏高,出现了设置成3σ不判定为异常值的情况。所以,使他只有一个异常值,来检测异常效果。(实际操作中异常值比例应该没有这么大,我这2/12了都,直接两个大异常值,把标准差拉到了50+,笑不活了QwQ)
这也可以用计算临界值的方法,大同小异哈。
1.2、处理
1.1.1、不处理
身为一条咸鱼,是躺床上起床上厕所都觉得累的!咱就啥都不干!!!

1.1.1、删除
这是pandas里面的操作方法哈
# 删除异常值
# print(data)
data1=data[~(np.abs(y_cha)>y_std*3)]# 删的是有异常值的一行哈
print(data1)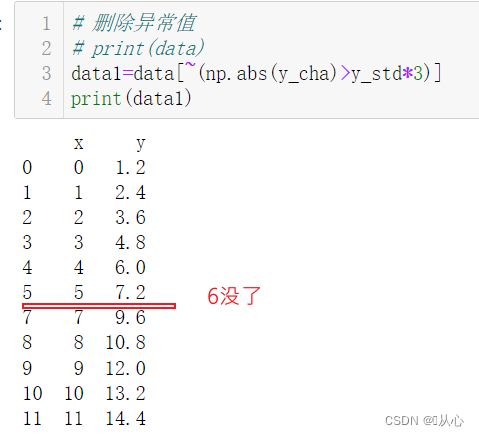
1.1.1、修改
一般修改为阈值或中值。(当然,也可以是其他的视情况而定。这里复制一个data2是防止吧data里面的数据修改了,后面还要用呢,节约是中华民族的传统美德)
# 修改异常值
data2=data.iloc[:,:]
for i in ind:
if data2.iloc[i,1]>UpLimit:
data2.iloc[i,1]=UpLimit
if data2.iloc[i,1]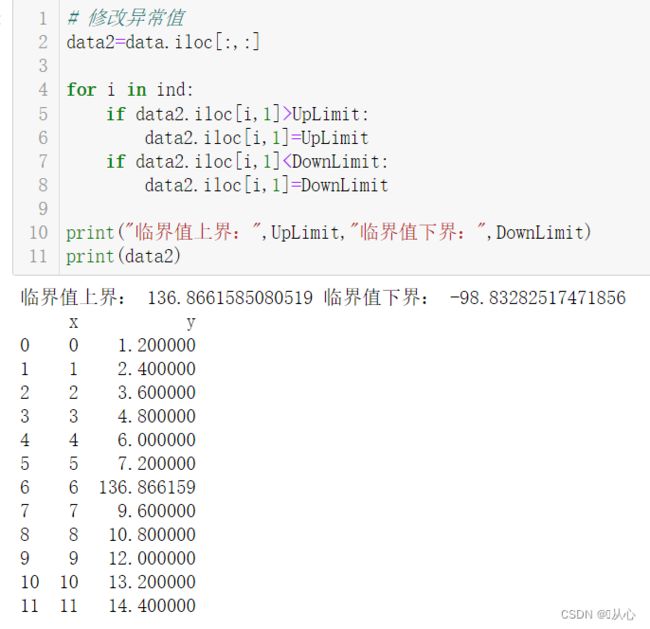
1.1.1、转换
当当当当,看异常值得差异是不是小了很多。但这种使用情况极少,慎用。
# 异常值的对数转换
log_y=np.log(data['y'])
print(log_y)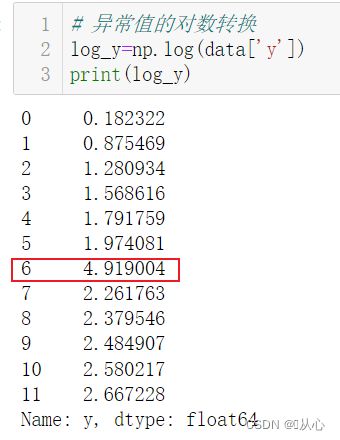
3、重复数据的检测与处理
重复数据有两种情况,一种是记录重复(整行重复),一种是特征重复(某个值重复)
1.2、记录重复
一个或多个特征列的几条记录完全一致,对于记录重复数据。一般采用直接删除方式
1.1.1、检测
# 制作数据
data=pd.DataFrame([[1,'gxy',88,70,'B'],
[2,'zqx',59,90,'B'],
[3,'ysy',91,95,'A'],
[2,'zqx',59,90,'B'],
[4,'xyyz',44,64,'C']],
columns=['num','name','English','Python','level'])
print(data)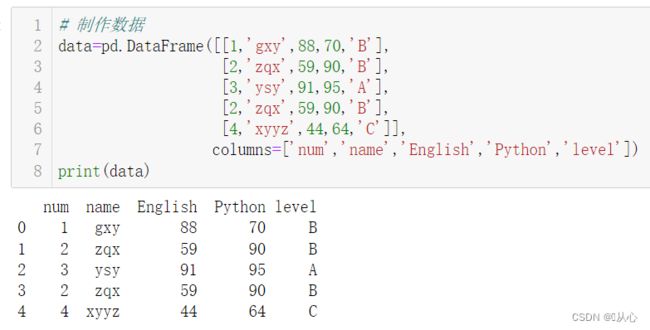
# 检测
result=data.duplicated()
print(result)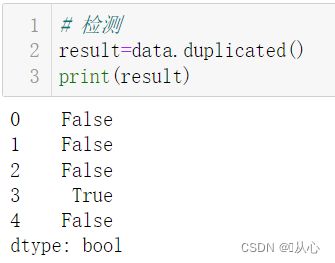
1.1.1、处理
# 处理
data1=data.drop_duplicates()
print(data1)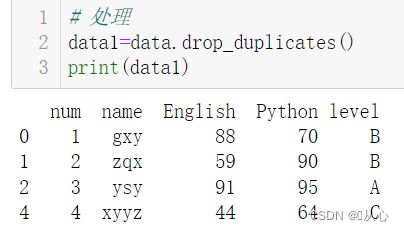
1.2、特征重复
一个或多个特征名不同,但是数据完全一样。
1.1.1、检测
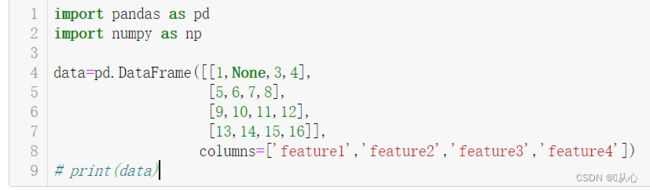
# 制作数据
data=pd.DataFrame([[1,'gxy',88,70,1,'B'],
[2,'zqx',59,90,2,'B'],
[3,'ysy',91,95,3,'A'],
[4,'xyyz',44,64,4,'C']],
columns=['num','name','English','Python','idCard','level'])
print(data)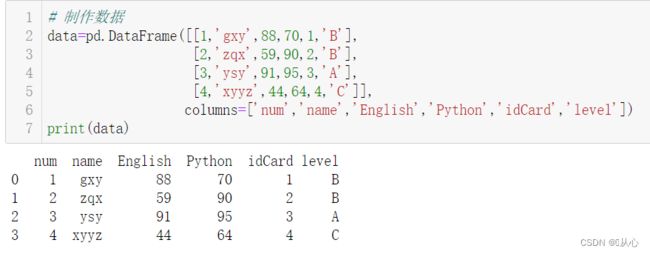
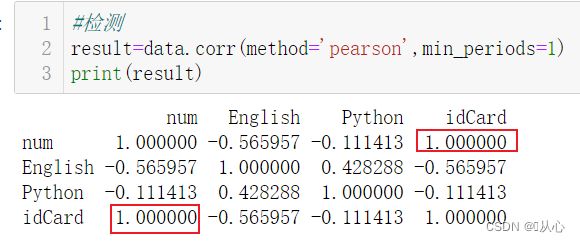
#检测
result=data.corr(method='pearson',min_periods=1)
print(result)corr函数检测相似度,相似度为1,表示两列数据一模一样
1.1.1、处理
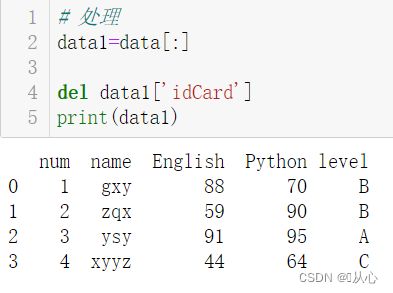
# 处理
data1=data[:]
del data1['idCard']
print(data1)
# 2
data1=data.iloc[:,[0,1,2,3,5]]
print(data1)