[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU
目录:
作业内容与要求:
1.过程推导-了解BP原理
2.数值计算-手动计算,掌握细节
3.代码实现-numpy手推+pytorch自动
1.)对比【numpy】和【pytorch】程序,总结并陈述。
2.)激活函数Sigmoid用PyTorch自带函数torch.sigmoid(),观察、总结并陈述。
3.)激活函数Sigmoid改变为Relu,观察、总结并陈述。
4.)损失函数MSE用PyTorch自带函数 t.nn.MSELoss()替代,观察、总结并陈述。
5.)损失函数MSE改变为交叉熵,观察、总结并陈述。
6.)改变步长,训练次数,观察、总结并陈述。
7.)权值w1-w8初始值换为随机数,对比“指定权值”的结果,观察、总结并陈述。
8.)权值w1-w8初始值换为0,观察、总结并陈述。
9.)全面总结反向传播原理和编码实现,认真写心得体会。
作业内容:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第1张图片](http://img.e-com-net.com/image/info8/15cbd4329fec4147b6dfc65494284646.jpg)
1. 过程推导,了解BP原理
BP算法是一种有监督的模式识别方法,包括学习和识别两部分。它的工作原理由信号的正向传播与误差的反向传播两个过程组成。
在正向传播过程中,输入模式从输入层经过隐含层处理,然后传递到输出层,每一层神经元状态只影响下一层神经元状态。这个过程的目标是计算输出值,这个输出值通常与期望值存在一定的误差。
当误差无法接受时,就会启动误差反向传播过程。这个过程实际上是计算模式的各层神经元权值的变化量,也就是根据输出值与期望值之间的误差,反向更新网络中各种神经元的权值。这个过程不断重复,直至完成对该模式集所有模式的计算,产生这一轮训练值的变化量。
在权值修正后,网络重新按照正向传播方式得到输出。实际输出值与期望值之间的误差可以导致新一轮的权值修正。正向传播与反向传播过程循环往复,直到网络收敛,得到网络收敛后的互联权值和阈值。
以下是推导过程(手写):
模型:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第2张图片](http://img.e-com-net.com/image/info8/b04095b52e1641ac8ff4f15f814b6795.jpg)
参数说明:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第3张图片](http://img.e-com-net.com/image/info8/7c526b1792a34c09a9da7342df1c0e1e.jpg)
前向传播过程:(字写错了 "项"应该改为"向")
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第4张图片](http://img.e-com-net.com/image/info8/69fa1aed02eb40e8afb5936eb7a79919.jpg)
链式求导,反向传播:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第5张图片](http://img.e-com-net.com/image/info8/974e11477ad542a5b1d44a39288af3d8.jpg)
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第6张图片](http://img.e-com-net.com/image/info8/f2269d2dd1cc4af19f39df262424e8c2.jpg)
参数修正:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第7张图片](http://img.e-com-net.com/image/info8/d5429b8b8c214a59be905cf5b64cc6f4.jpg)
2.数值计算-手动计算,掌握细节
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第8张图片](http://img.e-com-net.com/image/info8/f8c325bad5584bd2b699feb1b231881f.jpg)
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第9张图片](http://img.e-com-net.com/image/info8/ee8425a7558847e0b9054133e263b364.jpg)
将所有变量的值对应正确,进行计算,得到w5更新一次后的结果,与numpy代码进行比对,稍有差距,可能是小数点精度和保留小数点位数不同带来的偏差。而对比pytorch代码,则相似度极高,偏差非常非常小。
下面的截图是torch代码更新一次权值后显示出w5的权值:
3. 代码实现 numpy手推+pytorch实现
1.)对比【numpy】和【pytorch】程序,总结并陈述。
numpy代码:
import numpy as np
#根据老师给出的权值,设置八个权重w(weight)的值
w1,w2,w3,w4 = 0.2,-0.4,0.5,0.6
w5,w6,w7,w8 = 0.1,-0.5,-0.3,0.8
#输入值,输出值
x1,x2 = 0.5,0.3
y1,y2 = 0.23,-0.07
print('输入值x1,x2:',x1,x2)
print('输出值y1,y2:',y1,y2)
def sigmoid(z):
return 1/(1+np.exp(-z))
#前向传播算法
def forward_propagate(x1,x2,y1,y2,w1,w2,w3,w4,w5,w6,w7,w8):
#第一层
in_h1 = w1*x1 + w3*x2
out_h1 = sigmoid(in_h1)
in_h2 = w2*x1 + w4*x2
out_h2 = sigmoid(in_h2)
#第二层
in_o1 = w5*out_h1 + w7+out_h2
out_o1 = sigmoid(in_o1)
in_o2 = w6*out_h1 + w8*out_h2
out_o2 = sigmoid(in_o2)
#均方误差error
error = (1/2)*(out_o1 - y1)**2 + (1/2)*(out_o2 - y2)**2
#输出每一层的输出值和均方误差值
print('正向计算,隐藏层h1,h2:',round(out_h1,5),round(out_h2,5))
print('正向计算,预测值o1,o2:',round(out_o1,5),round(out_o2,5))
print('均方误差(损失函数):',round(error,5))
return out_o1,out_o2,out_h1,out_h2
#反向传播
def back_propagate(out_o1,out_o2,out_h1,out_h2):
#均方误差
d_o1 = out_o1 - y1
d_o2 = out_o2 - y2
#权重更新 第二层
d_w5 = d_o1 * out_o1 * (1-out_o1) * out_h1
d_w6 = d_o2 * out_o2 * (1-out_o2) * out_h1
d_w7 = d_o1 * out_o1 * (1-out_o1) * out_h2
d_w8 = d_o2 * out_o2 * (1-out_o2) * out_h2
#权重更新 第一层
d_w1 = (d_o1*out_o1*(1-out_o1)*w5 + d_o2*out_o2*(1-out_o2)*w6)*out_h1*(1-out_h1)*x1
d_w2 = (d_o1*out_o1*(1-out_o1)*w7 + d_o2*out_o2*(1-out_o2)*w8)*out_h2*(1-out_h2)*x1
d_w3 = (d_o1*out_o1*(1-out_o1)*w5 + d_o2*out_o2*(1-out_o2)*w6)*out_h1*(1-out_h1)*x2
d_w4 = (d_o1*out_o1*(1-out_o1)*w7 + d_o2*out_o2*(1-out_o2)*w8)*out_h2*(1-out_h2)*x2
print('w的梯度:',round(d_w1,3),round(d_w2,3),round(d_w3,3),round(d_w4,3),round(d_w5,3)
,round(d_w6,3),round(d_w7,3),round(d_w8,3))
return d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8
#步长
def update_w(w1,w2,w3,w4,w5,w6,w7,w8,d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8):
step = 1
w1 = w1 - step * d_w1
w2 = w2 - step * d_w2
w3 = w3 - step * d_w3
w4 = w4 - step * d_w4
w5 = w5 - step * d_w5
w6 = w6 - step * d_w6
w7 = w7 - step * d_w7
w8 = w8 - step * d_w8
return w1,w2,w3,w4,w5,w6,w7,w8
if __name__=='__main__':
print('权值w1-w8为:',round(w1,3),round(w2,3),round(w3,3),round(w4,3),round(w5,3),
round(w6,3),round(w7,3),round(w8,3))
for i in range(1000):
print('==第'+str(i+1)+'轮==')
#前向传播
out_o1,out_o2,out_h1,out_h2 = forward_propagate(x1,x2,y1,y2,w1,w2,w3,w4,w5,w6,w7,w8)
#反向传播
d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8 =back_propagate(out_o1,out_o2,out_h1,out_h2)
#更新步长
w1,w2,w3,w4,w5,w6,w7,w8 = update_w(w1,w2, w3, w4, w5, w6, w7, w8,
d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8)
print('更新后的权值w:',round(w1,3),round(w2,3),round(w3,3),round(w4,3),round(w5,3),
round(w6,3),round(w7,3),round(w8,3))通过调节步长,训练次数,可以查看w最终的更新值。在这段代码里,我设置反向传播的步长step=1。
训练结果:
第5轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第10张图片](http://img.e-com-net.com/image/info8/a259ccf11c2c43bf9a118c41126a283a.jpg)
第100轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第11张图片](http://img.e-com-net.com/image/info8/2d83e89c4e9b4e8e874dd7d1bdef7120.jpg)
第500轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第12张图片](http://img.e-com-net.com/image/info8/50e2e6a788f145a6a134362c280a1d27.jpg)
第1000轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第13张图片](http://img.e-com-net.com/image/info8/b4499b2065094fbda4ff48f98ca6261e.jpg)
第1194轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第14张图片](http://img.e-com-net.com/image/info8/ac89143ff6ff4a6a889b0215c19c7da3.jpg)
通过不断地微调,我发现在运行到第1194轮时,w的梯度刚好全部达到0,并且损失函数值loss都相等。此时达到最优解。
第1200轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第15张图片](http://img.e-com-net.com/image/info8/180a80e64d664ae4a33840ed80cb9ac6.jpg)
疑问:但是即使在w的梯度全部更新为0且损失函数的值不变后,我又增加了200次训练次数,发现更新后的w竟然还在产生微小的变化?按理论来讲,达到最优解时(w的梯度达到0),权值w应该不再更新,那么为何w还会继续更新下去?和sigmoid函数的性质有关?
pytorch自动实现代码:
import torch
x=[0.5,0.3]
y=[0.23,-0.07]
print('输入值x0,x1:',x[0],x[1])
print('输出值y0,y1:',y[0],y[1])
w=[torch.Tensor([0.2]),torch.Tensor([-0.4]),torch.Tensor([0.5]),torch.Tensor([0.6]),
torch.Tensor([0.1]),torch.Tensor([-0.5]),torch.Tensor([-0.3]),torch.Tensor([0.8])]
for i in range(0,8):
#设置张量的属性为True,意味着这个张量在反向传播时需要计算其梯度
w[i].requires_grad = True
print('权重w0-w7:')
for i in range(0,8):
print(w[i].data,end=' ')
#前向传播
def forward_propagate(x):
in_h1 = w[0] * x[0] + w[2] * x[1]
out_h1 = torch.sigmoid(in_h1)
in_h2 = w[1] * x[0] + w[3] * x[1]
out_h2 = torch.sigmoid(in_h2)
in_o1 = w[4] * out_h1 + w[6] * out_h2
out_o1 = torch.sigmoid(in_o1)
in_o2 = w[5] * out_h1 + w[7] * out_h2
out_o2 = torch.sigmoid(in_o2)
print("正向计算,隐藏层h1 ,h2:", end="")
print(out_h1.data, out_h2.data)
print("正向计算,预测值o1 ,o2:", end="")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
#损失函数
def loss(x,y):
y_pre = forward_propagate(x)
loss_mse = (1/2)*(y_pre[0]-y[0])**2 + (1/2)*(y_pre[1]-y[1])**2
print("损失函数(均方误差):", loss_mse.item())
return loss_mse
if __name__ == "__main__":
for k in range(5):
print("\n==第" + str(k+1) + "轮==")
l = loss(x, y) #求Loss+前向传播
l.backward() # 反向传播,求出计算图中所有梯度存入w中. 自动求梯度,不需要人工编程实现。
print("w的梯度: ", end=" ")
for i in range(0, 8):
print(round(w[i].grad.item(), 2), end=" ") # 查看梯度
step = 1 # 步长
for i in range(0, 8):
w[i].data = w[i].data - step * w[i].grad.data # 更新权值
w[i].grad.data.zero_() # 注意:将w中所有梯度清零
print("\n更新后的权值w:")
for i in range(0, 8):
print(w[i].data, end=" ")结果:
训练5轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第16张图片](http://img.e-com-net.com/image/info8/8b80ea30638b48aeb16c6e8af3bf3466.jpg)
训练100轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第17张图片](http://img.e-com-net.com/image/info8/05f054eb5bfc4860be117ce08ef08940.jpg)
训练1000轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第18张图片](http://img.e-com-net.com/image/info8/b01930372a424c83927707726445a10d.jpg)
训练次数与numpy代码实现的结果做对比,发现两种方式做出的模型结果相差不大。其中pytorch调用了反向传播函数backward(),大大减少了代码的复杂程度。
2) 激活函数Sigmoid用PyTorch自带函数torch.sigmoid(),观察、总结并陈述
主要区别在于:PyTorch版本的sigmoid函数可以处理任意类型的输入(例如,也可以是cuda上的张量),并且它可以直接作用在张量上,而不需要显式地写出循环。此外,如果输入的张量包含多个元素,PyTorch的sigmoid函数会对每个元素单独应用sigmoid函数。
由于浮点数精度的限制,对于非常大的或非常小的输入值,手写版本和PyTorch版本的sigmoid函数可能会产生轻微的差异。但是这种差异通常不会对神经网络的训练产生明显的影响。观察上一小节中的训练结果,torch.sigmoid()的精度会略高一些。
* torch.sigmoid(), torch.nn.Sigmoid, torch.nn.functional.sigmoid()的区别:
torch.nn.Sigmoid() :是一个类。在定义模型的初始化方法中使用,需要在__init__中定义。
torch.nn.functional.sigmoid():是一个方法,可直接在正向传播中使用,不需要初始化;在训练模型的过程中也可以直接使用。
具体细节请查询官方文档:Pytorch官方文档。
3)激活函数Sigmoid改编为Relu,观察、总结并陈述。
Relu函数公式:
![]()
ReLU函数图像:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第19张图片](http://img.e-com-net.com/image/info8/7cd27833179c4cd2902feaf2a8c4c781.jpg)
将sigmoid激活函数修改为ReLU激活函数:
代码:
import torch
import torch.nn as nn
x=[0.5,0.3]
y=[0.23,-0.07]
print('输入值x0,x1:',x[0],x[1])
print('输出值y0,y1:',y[0],y[1])
#创建ReLU对象
relu = nn.ReLU()
w=[torch.Tensor([0.2]),torch.Tensor([-0.4]),torch.Tensor([0.5]),torch.Tensor([0.6]),
torch.Tensor([0.1]),torch.Tensor([-0.5]),torch.Tensor([-0.3]),torch.Tensor([0.8])]
for i in range(0,8):
#设置张量的属性为True,意味着这个张量在反向传播时需要计算其梯度
w[i].requires_grad = True
print('权重w0-w7:')
for i in range(0,8):
print(w[i].data,end=' ')
#前向传播
def forward_propagate(x):
in_h1 = w[0] * x[0] + w[2] * x[1]
#out_h1 = torch.sigmoid(in_h1)
out_h1 = relu(in_h1)
in_h2 = w[1] * x[0] + w[3] * x[1]
out_h2 = relu(in_h2)
in_o1 = w[4] * out_h1 + w[6] * out_h2
#out_o1 = torch.sigmoid(in_o1)
out_o1 = relu(in_o1)
in_o2 = w[5] * out_h1 + w[7] * out_h2
out_o2 = relu(in_o2)
print("正向计算,隐藏层h1 ,h2:", end="")
print(out_h1.data, out_h2.data)
print("正向计算,预测值o1 ,o2:", end="")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
#损失函数
def loss(x,y):
y_pre = forward_propagate(x)
loss_mse = (1/2)*(y_pre[0]-y[0])**2 + (1/2)*(y_pre[1]-y[1])**2
print("损失函数(均方误差):", loss_mse.item())
return loss_mse
if __name__ == "__main__":
for k in range(5):
print("\n==第" + str(k+1) + "轮==")
l = loss(x, y) #求Loss+前向传播
l.backward() # 反向传播,求出计算图中所有梯度存入w中. 自动求梯度,不需要人工编程实现。
print("w的梯度: ", end=" ")
for i in range(0, 8):
print(round(w[i].grad.item(), 2), end=" ") # 查看梯度
step = 1 # 步长
for i in range(0, 8):
w[i].data = w[i].data - step * w[i].grad.data # 更新权值
w[i].grad.data.zero_() # 注意:将w中所有梯度清零
print("\n更新后的权值w:")
for i in range(0, 8):
print(w[i].data, end=" ")步长设置为1。
运行结果:
运行第1轮
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第20张图片](http://img.e-com-net.com/image/info8/39ed45c8f71b4f5dac1f32ed7786519a.jpg)
运行第5轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第21张图片](http://img.e-com-net.com/image/info8/65c5e2485fe04d859fff2813d82cda2c.jpg)
运行第100轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第22张图片](http://img.e-com-net.com/image/info8/567d5eb90d6740bd863859980e9325d2.jpg)
运行第1000轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第23张图片](http://img.e-com-net.com/image/info8/95fc061dfe8f489f918edf990157ebc3.jpg)
对比sigmoid激活函数训练出的模型,在步长相同且训练次数相同的情况下,ReLU函数在经过训练后得到的权重值要小,损失函数的值也要小。
均方误差在进行1轮、5轮训练就能迅速降下来,这很能说明使用Relu激活函数模型收敛速度是要优于使用sigmoid激活函数。并且Relu()函数有一个特性,使一部分神经元(即X轴副半区)的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生,这大概就是Relu()是目前主流激活函数的原因。
sigmoid激活函数涉及到指数运算,计算量大,并且反向传播求误差梯度时,求导涉及除法,所以运算量的不同会导致上述训练收敛速度的不同。
4.损失函数MSE用PyTorch自带函数 t.nn.MSELoss()替代,观察、总结并陈述。
在原有代码的基础上我进行了修改,因为参照学长的博客,所以我解决了损失函数没有backwrad()函数操作的问题(感谢学长的博客,博客链接置于后方):
点击: AttributeError: ‘MSELoss‘ object has no attribute ‘backward‘解决方案
接下来遇到了很棘手的问题,如下图:为什么数据类型为tensor的量都变为了nan(Not a Number),造成这种情况的可能原因通常是因为某些计算结果为无穷大或者无法定义(如0/0或者负数的平方根等),这时PyTorch会返回NaN。数值不稳定、初始化不正确等也会造成NaN的出现如果这种情况发生,需要检查你的计算过程或者模型的初始化。
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第24张图片](http://img.e-com-net.com/image/info8/9eb2a1afa03e4d62ab6f26f8e1120efa.jpg)
解决NaN的方法:
在梯度下降的函数中将每个更新后的w值清零。(具体原因我不清楚,先留下一个疑问)
代码:
import torch
x1, x2 = torch.Tensor([0.5]), torch.Tensor([0.3])
y1, y2 = torch.Tensor([0.23]), torch.Tensor([-0.07])
print("输入值:x1, x2:",x1,x2)
print("真实输出值:y1, y2:",y1,y2)
w1, w2, w3, w4, w5, w6, w7, w8 = torch.Tensor([0.2]), torch.Tensor([-0.4]), torch.Tensor([0.5]), torch.Tensor(
[0.6]), torch.Tensor([0.1]), torch.Tensor([-0.5]), torch.Tensor([-0.3]), torch.Tensor([0.8]) # 权重初始值
w1.requires_grad = True
w2.requires_grad = True
w3.requires_grad = True
w4.requires_grad = True
w5.requires_grad = True
w6.requires_grad = True
w7.requires_grad = True
w8.requires_grad = True
def sigmoid(z):
return 1 / (1 + torch.exp(-z))
def forward_propagate(x1, x2):
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1)
# out_h1 = torch.sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2)
# out_h2 = torch.sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1)
# out_o1 = torch.sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2)
# out_o2 = torch.sigmoid(in_o2)
print("正向计算:o1 ,o2")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
def loss_fuction(x1, x2, y1, y2):
y1_pred, y2_pred = forward_propagate(x1, x2)
t = torch.nn.MSELoss() #调用torch自带的MSE损失函数
loss = t(y1_pred,y1) + t(y2_pred,y2)
print("损失函数(均方误差):", loss.item())
return loss
def update_w(w1, w2, w3, w4, w5, w6, w7, w8):
# 步长
step = 1
w1.data = w1.data - step * w1.grad.data
w2.data = w2.data - step * w2.grad.data
w3.data = w3.data - step * w3.grad.data
w4.data = w4.data - step * w4.grad.data
w5.data = w5.data - step * w5.grad.data
w6.data = w6.data - step * w6.grad.data
w7.data = w7.data - step * w7.grad.data
w8.data = w8.data - step * w8.grad.data
# 注意:将w中所有梯度清零
w1.grad.data.zero_()
w2.grad.data.zero_()
w3.grad.data.zero_()
w4.grad.data.zero_()
w5.grad.data.zero_()
w6.grad.data.zero_()
w7.grad.data.zero_()
w8.grad.data.zero_()
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
print("==更新前的权值:==")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)
for i in range(1):
print("==第" + str(i+1) + "轮==")
L = loss_fuction(x1, x2, y1, y2) # 前向传播,求 Loss,构建计算图
L.backward() # 自动求梯度,不需要人工编程实现。反向传播,求出计算图中所有梯度存入w中
print("\tgrad W: ", round(w1.grad.item(), 2), round(w2.grad.item(), 2), round(w3.grad.item(), 2),
round(w4.grad.item(), 2), round(w5.grad.item(), 2), round(w6.grad.item(), 2), round(w7.grad.item(), 2),
round(w8.grad.item(), 2))
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(w1, w2, w3, w4, w5, w6, w7, w8)
print("更新后的权值:")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)结果:
更新1轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第25张图片](http://img.e-com-net.com/image/info8/f562448ac14e47beb8b6fde28d644299.jpg)
更新10轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第26张图片](http://img.e-com-net.com/image/info8/2af6ab47d44c486a93820ab0d88ee63b.jpg)
更新100轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第27张图片](http://img.e-com-net.com/image/info8/e7dd1e4476394a4d8b4d38cd7b0f2519.jpg)
更新1000轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第28张图片](http://img.e-com-net.com/image/info8/9d0c307df221489f9c0c1e7cb9f67e88.jpg)
对比可见,t.nn.MSELoss()损失函数的收敛性质没有手写损失函数的好。梯度下降速度也一般。
5.损失函数MSE改变为交叉熵,观察、总结并陈述。
损失函数部分修改为:
def loss_fuction(x1, x2, y1, y2):
y1_pred, y2_pred = forward_propagate(x1, x2)
loss_func = torch.nn.CrossEntropyLoss() #使用函数创建交叉熵损失函数
#dim维度设置为1 torch.stack()将张量在特定维度上堆叠
y_pred = torch.stack([y1_pred, y2_pred], dim=1)
y = torch.stack([y1, y2], dim=1)
loss = loss_func(y_pred, y) # 计算
print("损失函数(交叉熵损失):", loss.item())
return loss运行结果:
第1轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第29张图片](http://img.e-com-net.com/image/info8/7e4603f489fd484aa4006e81985c145a.jpg)
第10轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第30张图片](http://img.e-com-net.com/image/info8/b3c4deaf90e149c6a3f9bd07e07e1970.jpg)
第100轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第31张图片](http://img.e-com-net.com/image/info8/96e9de6e8e5245008731752309b74e39.jpg)
第1000轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第32张图片](http://img.e-com-net.com/image/info8/17a389b0f9b3454bbf3f487ad979996b.jpg)
当我训练至1000次时,竟然又出现了NaN的情况,由于上一问出现过此类问题,所以我决定再加上清零w梯度值的代码。再来重新看看生成结果:
更新1轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第33张图片](http://img.e-com-net.com/image/info8/140ebfdf1f094f2f8d61af778dcf344d.jpg)
更新10轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第34张图片](http://img.e-com-net.com/image/info8/5262816bbb22476fb435e4ad8547ba8c.jpg)
更新100轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第35张图片](http://img.e-com-net.com/image/info8/e9072f529dca4681ace05fd7aa253165.jpg)
更新1000轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第36张图片](http://img.e-com-net.com/image/info8/e467064ff12e417cb96a015311940d5b.jpg)
由此可见,交叉熵损失函数用来处理非分类问题的效果是非常差的,损失函数的值不仅大小不定,甚至出现了负数。输出值o1,o2的值相对于之前模型生成的值 结果相差很大。 再次印证了交叉熵损失函数不适合解决非分类问题,均方误差损失函数适合解决回归问题。
原因:交叉熵公式:
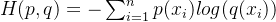
当网络输出的概率为0-1时,表达式得正数;当网络输出大于1,就可能变为负值。
6.改变步长,训练次数,观察、总结并陈述。
对反向传播过程的步长step进行改变。
numpy可视化代码:
import numpy as np
import matplotlib.pyplot as plt
#根据老师给出的权值,设置八个权重w(weight)的值
w1,w2,w3,w4 = 0.2,-0.4,0.5,0.6
w5,w6,w7,w8 = 0.1,-0.5,-0.3,0.8
#输入值,输出值
x1,x2 = 0.5,0.3
y1,y2 = 0.23,-0.07
print('输入值x1,x2:',x1,x2)
print('输出值y1,y2:',y1,y2)
def sigmoid(z):
return 1/(1+np.exp(-z))
def Loss(out_o1,out_o2,y1,y2):
#均方误差error
error = (1/2)*(out_o1 - y1)**2 + (1/2)*(out_o2 - y2)**2
return error
#前向传播算法
def forward_propagate(x1,x2,y1,y2,w1,w2,w3,w4,w5,w6,w7,w8):
#第一层
in_h1 = w1*x1 + w3*x2
out_h1 = sigmoid(in_h1)
in_h2 = w2*x1 + w4*x2
out_h2 = sigmoid(in_h2)
#第二层
in_o1 = w5*out_h1 + w7+out_h2
out_o1 = sigmoid(in_o1)
in_o2 = w6*out_h1 + w8*out_h2
out_o2 = sigmoid(in_o2)
#输出每一层的输出值和均方误差值
print('正向计算,隐藏层h1,h2:',round(out_h1,5),round(out_h2,5))
print('正向计算,预测值o1,o2:',round(out_o1,5),round(out_o2,5))
error = Loss(out_o1,out_o2,y1,y2)
print('均方误差(损失函数):',round(error,5))
return out_o1,out_o2,out_h1,out_h2
#反向传播
def back_propagate(out_o1,out_o2,out_h1,out_h2):
#均方误差
d_o1 = out_o1 - y1
d_o2 = out_o2 - y2
#权重更新 第二层
d_w5 = d_o1 * out_o1 * (1-out_o1) * out_h1
d_w6 = d_o2 * out_o2 * (1-out_o2) * out_h1
d_w7 = d_o1 * out_o1 * (1-out_o1) * out_h2
d_w8 = d_o2 * out_o2 * (1-out_o2) * out_h2
#权重更新 第一层
d_w1 = (d_o1*out_o1*(1-out_o1)*w5 + d_o2*out_o2*(1-out_o2)*w6)*out_h1*(1-out_h1)*x1
d_w2 = (d_o1*out_o1*(1-out_o1)*w7 + d_o2*out_o2*(1-out_o2)*w8)*out_h2*(1-out_h2)*x1
d_w3 = (d_o1*out_o1*(1-out_o1)*w5 + d_o2*out_o2*(1-out_o2)*w6)*out_h1*(1-out_h1)*x2
d_w4 = (d_o1*out_o1*(1-out_o1)*w7 + d_o2*out_o2*(1-out_o2)*w8)*out_h2*(1-out_h2)*x2
print('w的梯度:',round(d_w1,3),round(d_w2,3),round(d_w3,3),round(d_w4,3),round(d_w5,3)
,round(d_w6,3),round(d_w7,3),round(d_w8,3))
return d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8
#步长
def update_w(w1,w2,w3,w4,w5,w6,w7,w8,d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8):
step = 1
w1 = w1 - step * d_w1
w2 = w2 - step * d_w2
w3 = w3 - step * d_w3
w4 = w4 - step * d_w4
w5 = w5 - step * d_w5
w6 = w6 - step * d_w6
w7 = w7 - step * d_w7
w8 = w8 - step * d_w8
return w1,w2,w3,w4,w5,w6,w7,w8
if __name__=='__main__':
print('权值w1-w8为:',round(w1,3),round(w2,3),round(w3,3),round(w4,3),round(w5,3),
round(w6,3),round(w7,3),round(w8,3))
# 创建空列表,用来存储损失函数的值
E = []
for i in range(10):
print('==第'+str(i+1)+'轮==')
#前向传播
out_o1,out_o2,out_h1,out_h2 = forward_propagate(x1,x2,y1,y2,w1,w2,w3,w4,w5,w6,w7,w8)
#反向传播
d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8 =back_propagate(out_o1,out_o2,out_h1,out_h2)
#更新步长
w1,w2,w3,w4,w5,w6,w7,w8 = update_w(w1,w2, w3, w4, w5, w6, w7, w8,
d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8)
print('更新后的权值w:',round(w1,3),round(w2,3),round(w3,3),round(w4,3),round(w5,3),
round(w6,3),round(w7,3),round(w8,3))
E.append(Loss(out_o1, out_o2, y1, y2))
print('E= ',E)
plt.figure()
plt.xlabel('count')
plt.ylabel('Loss')
plt.title('step = 1')
plt.plot(range(10), E)
plt.show()结果:
step = 1 ,迭代10次
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第37张图片](http://img.e-com-net.com/image/info8/f82eeb2a9623487db9d1292a1fa32040.jpg)
step = 1,迭代100次
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第38张图片](http://img.e-com-net.com/image/info8/e7b7b8cda3cd4810a1334763f76f8ba9.jpg)
step = 1,迭代1000次
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第39张图片](http://img.e-com-net.com/image/info8/994986477f5c45f1bbccac415a12759e.jpg)
现在改变步长,由step=1改变为step=0.1
step = 0.1,迭代5次
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第40张图片](http://img.e-com-net.com/image/info8/d2c8f4ad882443c1bf151d2f65e8fe39.jpg)
step =0.1 ,迭代100次
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第41张图片](http://img.e-com-net.com/image/info8/ca421617e42b484d8cf59797bcdd0c11.jpg)
step = 0.1,迭代1000次
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第42张图片](http://img.e-com-net.com/image/info8/2fef5213a4c74e5fab2e2fa845e1ba53.jpg)
step = 0.1 ,训练10000次:(辛苦我的电脑了哈哈哈哈哈)
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第43张图片](http://img.e-com-net.com/image/info8/84eff449ccc74a11a7011b505ae7b95b.jpg)
可见step越小,损失函数的值下降的越慢。step = 0.1时训练1000次 仅仅相当于step=1时,训练100次的效果。当step = 0.1时,需要训练一万次 才能达到step = 1训练1000次的效果。
再尝试一下step = 20 训练1000次的效果:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第44张图片](http://img.e-com-net.com/image/info8/54de5dbe083f4b678197a281afe502c6.jpg)
step = 50,训练1000次的效果:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第45张图片](http://img.e-com-net.com/image/info8/ff5b3657d10b486483e94296d22fe8f7.jpg)
可以看出,步数越大,损失函数下降的越快,到达最优质的速度越快,图片中的曲线已经接近直角。不过step也不可以设置的过大,否则会出现跳过局部最小值的情况,使损失函数无法达到最优。并且观察step=50的图像,发现曲线在接近最小值时产生了震荡,容易导致无法收敛到最优解。
7.权值w1-w8初始值换为随机数,对比“指定权值”的结果,观察、总结并陈述。
numpy代码中,随机初始w的权值,w是形状为[1,]的numpy数组,注意numpy数组没有round()方法。以下是代码:
import numpy as np
#随机生成八个w的权值
#返回形状为(1, )的一维NumPy数组,数组中的元素是从[0, 1)之间的均匀分布中随机采样的随机数。
w1,w2,w3,w4,w5,w6,w7,w8 = np.random.rand(1),np.random.rand(1),np.random.rand(1),np.random.rand(1)\
,np.random.rand(1),np.random.rand(1),np.random.rand(1),np.random.rand(1),
#输入值,输出值
x1,x2 = 0.5,0.3
y1,y2 = 0.23,-0.07
print('输入值x1,x2:',x1,x2)
print('输出值y1,y2:',y1,y2)
def sigmoid(z):
return 1/(1+np.exp(-z))
#前向传播算法
def forward_propagate(x1,x2,y1,y2,w1,w2,w3,w4,w5,w6,w7,w8):
#第一层
in_h1 = w1*x1 + w3*x2
out_h1 = sigmoid(in_h1)
in_h2 = w2*x1 + w4*x2
out_h2 = sigmoid(in_h2)
#第二层
in_o1 = w5*out_h1 + w7+out_h2
out_o1 = sigmoid(in_o1)
in_o2 = w6*out_h1 + w8*out_h2
out_o2 = sigmoid(in_o2)
#均方误差error
error = (1/2)*(out_o1 - y1)**2 + (1/2)*(out_o2 - y2)**2
#输出每一层的输出值和均方误差值
print('正向计算,隐藏层h1,h2:',out_h1,5,out_h2,5)
print('正向计算,预测值o1,o2:',out_o1,5,out_o2,5)
print('均方误差(损失函数):',error)
return out_o1,out_o2,out_h1,out_h2
#反向传播
def back_propagate(out_o1,out_o2,out_h1,out_h2):
#均方误差
d_o1 = out_o1 - y1
d_o2 = out_o2 - y2
#权重更新 第二层
d_w5 = d_o1 * out_o1 * (1-out_o1) * out_h1
d_w6 = d_o2 * out_o2 * (1-out_o2) * out_h1
d_w7 = d_o1 * out_o1 * (1-out_o1) * out_h2
d_w8 = d_o2 * out_o2 * (1-out_o2) * out_h2
#权重更新 第一层
d_w1 = (d_o1*out_o1*(1-out_o1)*w5 + d_o2*out_o2*(1-out_o2)*w6)*out_h1*(1-out_h1)*x1
d_w2 = (d_o1*out_o1*(1-out_o1)*w7 + d_o2*out_o2*(1-out_o2)*w8)*out_h2*(1-out_h2)*x1
d_w3 = (d_o1*out_o1*(1-out_o1)*w5 + d_o2*out_o2*(1-out_o2)*w6)*out_h1*(1-out_h1)*x2
d_w4 = (d_o1*out_o1*(1-out_o1)*w7 + d_o2*out_o2*(1-out_o2)*w8)*out_h2*(1-out_h2)*x2
print('w的梯度:',w1,w2,w3,w4,w5,w6,w7,w8)
return d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8
#步长
def update_w(w1,w2,w3,w4,w5,w6,w7,w8,d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8):
step = 1
w1 = w1 - step * d_w1
w2 = w2 - step * d_w2
w3 = w3 - step * d_w3
w4 = w4 - step * d_w4
w5 = w5 - step * d_w5
w6 = w6 - step * d_w6
w7 = w7 - step * d_w7
w8 = w8 - step * d_w8
return w1,w2,w3,w4,w5,w6,w7,w8
if __name__=='__main__':
print('权值w1-w8为:',w1,w2,w3,w4,w5,w6,w7,w8)
for i in range(10):
print('==第'+str(i+1)+'轮==')
#前向传播
out_o1,out_o2,out_h1,out_h2 = forward_propagate(x1,x2,y1,y2,w1,w2,w3,w4,w5,w6,w7,w8)
#反向传播
d_w1,d_w2,d_w3,d_w4,d_w5,d_w6,d_w7,d_w8 =back_propagate(out_o1,out_o2,out_h1,out_h2)
#更新步长
w1,w2,w3,w4,w5,w6,w7,w8 = update_w(w1,w2, w3, w4, w5, w6, w7, w8,
d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8)
print('更新后的权值w:',w1,w2,w3,w4,w5,w6,w7,w8)结果:
随机生成的初始值:(注: 这个多余的5是我不小心打上去的,没有任何实际意义。对不起 请见谅)

训练1轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第46张图片](http://img.e-com-net.com/image/info8/89b16e034cce4ab3a79aa67e1fbcff38.jpg)
训练10轮:
训练100轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第47张图片](http://img.e-com-net.com/image/info8/10e4c790fc6e458cbfcc5d2d7e429a1e.jpg)
训练1000轮:
![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第48张图片](http://img.e-com-net.com/image/info8/acaea7edde734a28842a2ee6b2b7723d.jpg)
训练5000轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第49张图片](http://img.e-com-net.com/image/info8/70e432e8e0e04648a2008384dc23ada7.jpg)
对比可得,随机生成的权重进行训练 和使用特定权重数值训练的效果类似,在相同的训练次数和步数下得到的均方误差值和输出值o1,o2的结果几乎一样。
8.权值w1-w8初始值换为0,观察、总结并陈述。
pytorch代码:
import torch
x=[0.5,0.3]
y=[0.23,-0.07]
print('输入值x0,x1:',x[0],x[1])
print('输出值y0,y1:',y[0],y[1])
w=[torch.Tensor([0.0]),torch.Tensor([-0.0]),torch.Tensor([0.0]),torch.Tensor([0.0]),
torch.Tensor([0.0]),torch.Tensor([-0.0]),torch.Tensor([-0.0]),torch.Tensor([0.0])]
for i in range(0,8):
#设置张量的属性为True,意味着这个张量在反向传播时需要计算其梯度
w[i].requires_grad = True
print('权重w0-w7:')
for i in range(0,8):
print(w[i].data,end=' ')
#前向传播
def forward_propagate(x):
in_h1 = w[0] * x[0] + w[2] * x[1]
out_h1 = torch.sigmoid(in_h1)
in_h2 = w[1] * x[0] + w[3] * x[1]
out_h2 = torch.sigmoid(in_h2)
in_o1 = w[4] * out_h1 + w[6] * out_h2
out_o1 = torch.sigmoid(in_o1)
in_o2 = w[5] * out_h1 + w[7] * out_h2
out_o2 = torch.sigmoid(in_o2)
print("正向计算,隐藏层h1 ,h2:", end="")
print(out_h1.data, out_h2.data)
print("正向计算,预测值o1 ,o2:", end="")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
#损失函数
def loss(x,y):
y_pre = forward_propagate(x)
loss_mse = (1/2)*(y_pre[0]-y[0])**2 + (1/2)*(y_pre[1]-y[1])**2
print("损失函数(均方误差):", loss_mse.item())
return loss_mse
if __name__ == "__main__":
for k in range(5):
print("\n==第" + str(k+1) + "轮==")
l = loss(x, y) #求Loss+前向传播
l.backward() # 反向传播,求出计算图中所有梯度存入w中. 自动求梯度,不需要人工编程实现。
print("w的梯度: ", end=" ")
for i in range(0, 8):
print(round(w[i].grad.item(), 2), end=" ") # 查看梯度
step = 1 # 步长
for i in range(0, 8):
w[i].data = w[i].data - step * w[i].grad.data # 更新权值
w[i].grad.data.zero_() # 注意:将w中所有梯度清零
print("\n更新后的权值w:")
for i in range(0, 8):
print(w[i].data, end=" ")运行结果:
训练第1轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第50张图片](http://img.e-com-net.com/image/info8/4ebcb4f59d1e4f2d98474adf4f9b3c14.jpg)
第5轮:
第100轮:
第1000轮:![[23-24 秋学期] NNDL 作业4 前馈神经网络 HBU_第51张图片](http://img.e-com-net.com/image/info8/a288a03558f0403e9ffca31c9d5009c5.jpg)
观察结果,并与之前的结果进行对比,发现最初的几轮开始,损失函数的值下降的比较快,到了1000轮时和之前的结果几乎相似,只有微微微小的差别。这说明w的初始值对于前馈神经网络模型训练结果的影响不大,仅仅对收敛速度有些影响。
9.全面总结反向传播原理和编码实现,认真写心得体会。
.在机器学习中就学习了前向传播和反向传播的理论,手推公式和过程理解还是比较好理解的。我的薄弱项就是上机敲代码实现。通过这次的博客,我遇到了各种各样的问题,最后都是通过参照学长博客、文心一言、询问同学、看老师博客、在jupyter调试代码解决的,虽然有的问题还是模模糊糊,没有弄懂。但是对于前向传播和反向传播的大体代码也有了思路,自己花费了一定的时间去手敲代码,痛苦又难熬,但是真正运行成功后,会产生很大的满足感。
.代码的整体思路都了解了。但是敲写代码框架不是最耗时耗精力的,修改bug,调试代码才是最困难最折磨人的环节!!尤其是我对pytorch框架不熟悉,对pytorch中的张量Tensor认知不透彻,导致我在数据类型为张量的设置和运行上遇到了很多error。改来改去,最后莫名其妙的可以运行成功了(哭笑不得) 今后还是要加强pytorch框架的练习!!
.numpy方法我也没有掌握得太好,遇到了一些问题,又修修改改、缝缝补补的写好了,里面的方法太多,需要随时打开python官方文档和CSDN博客查询。具体遇到的报错类型和信息我也融合的写在前文中了。
.还有一个我未解决的问题(询问了上届人工智能专业的大佬学长,他也没有弄懂):在pytorch框架的代码中,为何会出现Tensor的值变为NaN(Not a Number)?为什么需要在梯度下降的函数中将更新后的权重w进行清零?
.真实值y2的值为-0.07,但是我用numpy和pytorch代码做完反向传播训练后,发现o2(输出值)为正数,并且数值上比0.07还要小一位。问了问其他的几个同学,同学说她们求出来的o2值也是正数。这说明我的代码还是存在问题的,也或者是因为现在我们接触到的激活函数类型不多,sigmoid函数对于负数的处理特性存在缺陷。
.遇到的很多问题我都写进了前文,需要自己多回顾过程。在学习完深度学习后,希望自己可以给出合理的解决方案,使我的博客更加完善。
在此鸣谢:
【人工智能导论:模型与算法】MOOC 8.3 误差后向传播(BP) 例题 编程验证 - HBU_DAVID - 博客园 (cnblogs.com)
【人工智能导论:模型与算法】MOOC 8.3 误差后向传播(BP) 例题 编程验证 Pytorch版本 - HBU_DAVID - 博客园 (cnblogs.com)
【人工智能导论:模型与算法】MOOC 8.3 误差后向传播(BP) 例题 【第三版】 - HBU_DAVID - 博客园 (cnblogs.com)
深入理解ReLU函数(ReLU函数的可解释性)-CSDN博客
NNDL 作业3:分别使用numpy和pytorch实现FNN例题_。没有用n,nly,kkn3_笼子里的薛定谔的博客-CSDN博客
DL Homework 4_熬夜患者的博客-CSDN博客