目标检测COCO数据集与评价体系mAP
1.mAP

2.IoU
IoU也就是交并比,也称为 Jaccard 指数,用于计算真实边界框与预测边界框之间的重叠程度。它是真值框与预测边界框的交集和并集之间的比值。Ground Truth边界框是测试集中手工标记的边界框,用于指定对象图像的位置以及预测的边界框来自模型的位置。
下图是真实值边界框与预测边界框的直观示例,其目标是计算这两个边界框之间的交并比。
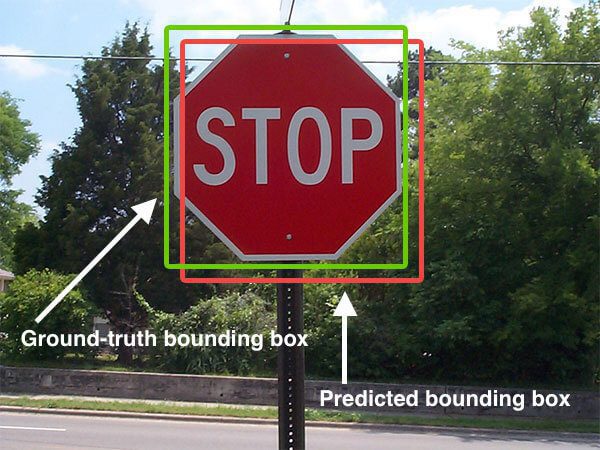
图1 检测停车标志,预测的边界框以红色绘制,而真实边界框以绿色绘制。
交并比的计算非常简单,只需将边界框之间的重叠区域除以并集面积即可。

IoU 分数是标准化的(因为分母是并集区域面积),范围从 0.0 到 1.0。此处,0.0 表示预测边界框和真值边界框之间没有重叠,而 1.0 是最优值,这意味着预测的边界框与真值边界框完全重叠。
IoU> 0.5 通常被认为是“良好”的预测。反之, IoU < 0.5 视为预测不合格,予以舍弃。
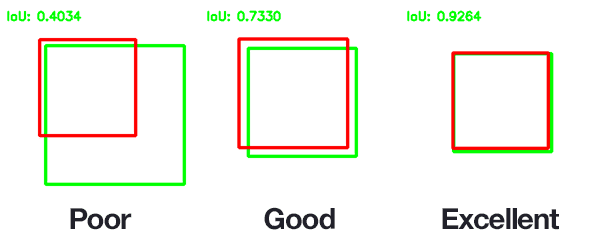
通常我们并不关心边界框的 (x, y) 坐标与Ground Truth边界框的 (x, y) 坐标的精确匹配,但我们希望确保预测的边界框尽可能接近 — 也就是交集可以考虑这一点。
上图中,与真实边界框严重重叠的预测边界框比重叠较少的边界框具有更高的IoU分数。这使得交并比成为评估自定义对象检测器的绝佳指标。尽管如此,IoU的简单计算还是会存在各种各样的局限,具体需进一步查阅IoU的各种扩展,本文不涉及这方面的讨论。
3.精确率和召回率
要了解 mAP,我们先来看看精确率与召回率。召回率是真正率,即在所有实际正例中,有多少是真正例的预测结果。精确率是预测正率,即在所有预测正类结果中,有多少是真正例的预测结果。
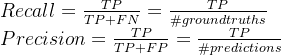
对于mAP的计算,主要针对两种数据集展开具体讨论。
Pascal VOC
Pascal(VOC2012) 是一项挑战赛,即在现实场景中识别来自各种视觉目标类的对象。这是一项监督学习比赛,其中提供了标记的Ground Truth图像。该数据集有 20 个目标类,如人、鸟、猫、狗、自行车、汽车、椅子、沙发、电视、瓶子等。
PASCAL VOC 的历史可以追溯到 2005 年,当时数据集仅包含四类:自行车、汽车、摩托车和人。它共有 1578 张图像,包含 2209 个带标注的目标。
下图显示了 20 个类中每个类的示例图像,正如我们所看到的,第一行倒数第二张图像中有几把(三)把椅子。

PASCAL VOC 数据集中描述所有 20 个类别的示例图像
VOC2012 数据集由 11,530 张图像和 27,450 个感兴趣区域 (ROI)标注目标组成,并带有 train/val 拆分。27,450 ROI 是指整个数据集中的边界框,因为每个图像可以有多个目标区域或 ROI。因此,与图像相比,ROI数量是图像数量的2 倍以上。
为了计算 mAP,首先需要计算每个类的 AP。
考虑以下图像,其中包含特定类的ground truths(绿色)和 bbox 预测(红色)。

bbox的详细信息如下:
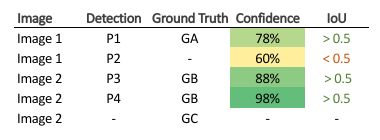
在此示例中,如果 IoU > 0.5 视为TP,否则 FP。现在,根据置信度分数对图像检测结果排序。注意,如果单个object有多个检测,则具有最高 IoU 的检测被视为 TP,其余为 FP,如下图所示。

在 VOC 指标中,召回率定义为排名高于给定排名的所有正例的比例。精确率是该排名以上所有示例中来自正类的比例。
因此,在 Acc (accumulated) TP 列中,从顶部写下遇到的 TP 总数,并对 Acc FP 执行相同的操作。现在,对于P4计算精确率与召回率:Precision = 1/(1+0) = 1Recall = 1/3 = 0.33
然后绘制这些精确率和召回率值,以获得 PR(精确召回率)曲线。PR 曲线下的面积称为平均精度 (AP)。PR 曲线遵循一种锯齿形模式,因为召回率绝对增加,而精确率总体上随着零星上升而降低。
AP 总结了精确召回率曲线的形状,在 VOC 2007 中,它被定义为一组 11 个等距召回水平 [0,0.1,...,1](0 到 1,步长为 0.1)的精确值的平均值,而不是 AUC。
![]()
每个召回率水平 r 的精度是通过取相应召回率超过 r 的方法测量的最大精度来插值的。
![]()

即在 11 个等距召回点 [0:0.1:1] 处取右边的最大精度值,并取它们的平均值得到 AP。
然而,从 VOC 2010 开始,AP 的计算发生了变化。
通过将召回率 r 的精度设置为任何召回率获得的最大精度,计算精确率单调递减的测量精度-召回率曲线的版本
然后通过数值积分将 AP 计算为该曲线下的面积。
即,给定橙色的 PR 曲线,计算所有召回点右侧的最大精度,从而获得绿色的新曲线。现在,在绿色曲线下使用积分进行 AUC,这就得到AP。与 VOC 2007 的唯一区别是,我们不仅考虑了 11 点,还考虑了所有要点。
现在,我们有每个类(对象类别)的 AP,平均精度 (mAP) 是所有对象类别的平均 AP。
![]()
对于VOC中的分割挑战,以分割精度(使用IoU计算的每像素精度)作为评价标准,其定义如下:
![]()
COCO
Microsoft Common Objects in Context (MS COCO) 是 2014 年推出的大规模目标检测、分割和字幕数据集,借助使用新颖用户界面的广泛众包数据。该数据集包含 80 个对象类别的图像,在 328k 图像中具有 250 万个标记实例。
下图显示了 COCO 数据集中标有实例分割的示例图像。
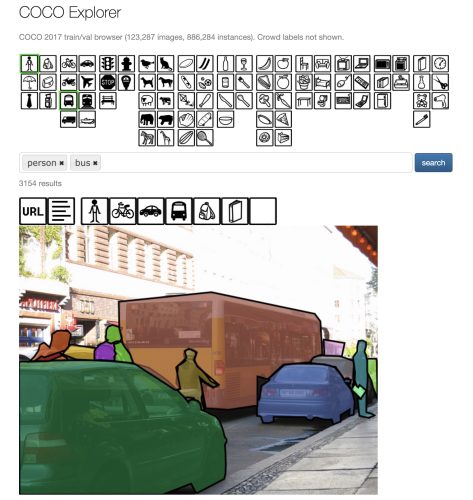
COCO 还具有出色的用户界面,可以探索数据集中的图像。例如,您可以从 80 个类中选择缩略图;它会将它们作为标签放在搜索栏中,当您搜索时,它将显示数据集中带有这些标签(类)的所有图像,如下图所示。
此外,当显示生成的图像时,所有类(超过搜索的类)都显示为缩略图。也就是可以通过进一步单击这些缩略图来可视化与这些类相关的分割掩码来使用它。

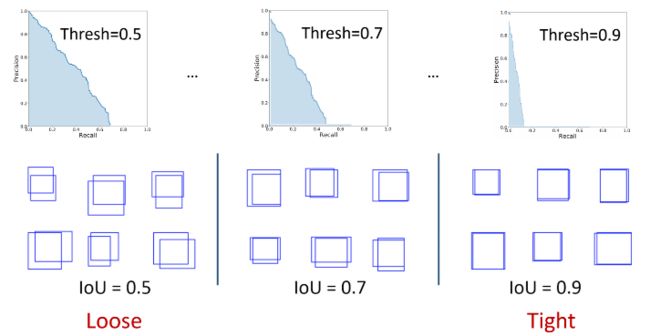
通常,与 VOC 一样,IoU > 0.5 的预测被视为真正例预测。这意味着 IoU 0.6 和 0.9 的两个预测将具有相等的权重。因此,某个阈值会在评估指标中引入偏差。解决此问题的一种方法是使用一系列 IoU 阈值,并计算每个 IoU 的 mAP,并取它们的平均值来获得最终的 mAP。
请注意,COCO 使用 [0:.01:1] R=101 召回阈值进行评估。
在 COCO 评估中,IoU 阈值范围为 0.5 至 0.95,步长为 0.05 表示为 AP@[.5:.05:.95]。
IoU=0.5 和 IoU=0.75 等固定 IoU 的 AP 分别写为 AP50 和 AP75。
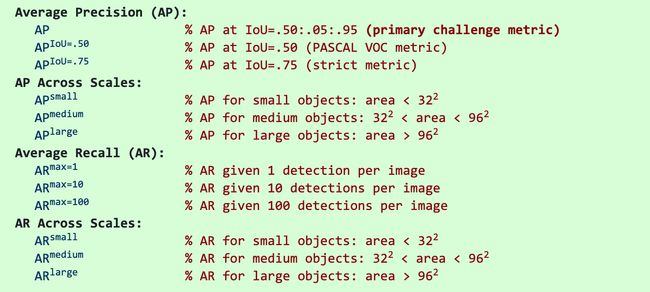
除非另有说明,否则 AP 和 AR 在多个并集交集 (IoU) 值上取平均值。具体来说,我们使用 10 个 IoU 阈值 .50:.05:.95。这与传统不同,在传统中,AP 以 .50 的单个 IoU 计算(对应于我们的指标一个
).对 IoUs 进行平均会奖励具有更好定位的检测器。
![]()
AP 是所有类别的平均值。传统上,这被称为“平均精度”(mAP)。我们没有区分 AP 和 mAP(以及 AR 和 mAR),并假设从上下文中可以清楚地看出区别。
两分钟的补充:通常,平均值以不同的顺序进行(最终结果是相同的),在 COCO 中,mAP 也称为 AP,即
- 步骤1:对于每个类,计算不同 IoU 阈值下的 AP,并取其平均值以获得该类的 AP。
![]()
- 步骤2:通过对不同类的 AP 求平均值来计算最终 AP。
![]()
AP 实际上是一个平均、平均、平均的精度。
4.结论
- PascalVOC2007 在 PR 曲线上使用 11 个召回点。
- PascalVOC2010–2012 在 PR 曲线上使用(所有点)曲线下面积 (AUC)。
- MS COCO 在 PR 曲线上使用 101 个召回点以及不同的 IoU 阈值。
5.参考资料
- COCO evaluation metrics
- VOC2007 metrics
- VOC2012 metrics
- Object detection metrics
- mAP (mean Average Precision) for Object Detection
- Evaluation metrics for object detection and segmentation: mAP (kharshit.github.io)