北京交通大学高性能作业——CPU SIMD + GPU SIMD
高性能 CPU SIMD + GPU SIMD
- 1. CPU SIMD
-
- Intel SIMD
-
- 运行代码和截图
- 结果分析
- Kunpeng SIMD (ARM NENO)
-
- 运行代码与截图
- 结果分析
- 2.GPU SIMD
-
- CUDA installation information
- deviceQuery in CUDA
- Vector calculation in CUDA
-
- 运行代码及截图
- 结果分析
- PI calculation in CUDA
-
- 运行代码及截图
- 结果分析
1. CPU SIMD
Intel SIMD
运行代码和截图
#include 
图1-1 PC上的CPU SIMD性能比较
结果分析
这段程序比较了SIMD使用SSE指令集和不使用SIMD两种方式的计算速度差距,程序计算的是√x/x,发现SIMD使用SSE指令集可以并行四个浮点数进行计算,结果确实会比不使用SIMD更快。
Kunpeng SIMD (ARM NENO)
运行代码与截图
#include 
图1-2 TaiShan服务器运行ARM NENO文件
结果分析
程序使用了ARM NEON指令集提供的函数实现了对16个uint8_t类型的数据进行并行计算。add3函数是使16个unit8_t元素的向量每个元素加3。其中vmovq_n_u8函数创建了一个有16个uint8_t 类型元素的向量three,每个元素值都是3。vaddq_u8函数将three和data中每个对应元素相加,将结果写回data。print_uint8函数,用于打印uint8x16_t类型的向量,方法是先把向量元素的值存储到数组再打印。主函数中定义了一个uint8_data数组,包含了16个 uint8_t类型的数据再转化为16个元素的向量data。print_uint8函数打印出data最初的值,再调用add3函数操作data,最后调用print_uint8函数打印出计算后的值。
2.GPU SIMD
CUDA installation information
通过win + r输入cmd打开命令行,用nvcc -V查看cuda的安装信息,我安装的版本是11.6
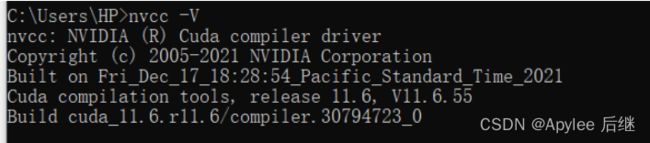
图2-1-1 CUDA installation information
deviceQuery in CUDA
进入我安装CUDA的位置,并运行deviceQuery,可以看到给出了详细的设备信息,里面有我的显卡型号和最大的计算能力,以及运行内存和主频等。

图2-2-1deviceQuery in CUDA
Vector calculation in CUDA
运行代码及截图
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 
图2-3-1 Vector calculation in CUDA
结果分析
程序创建了一个包含10个元素的浮点数数组。把数组从主机内存复制到显卡的内存中。计算了该数组每个元素的平方,并将结果存到显卡的内存中。最后,它从显卡内存中将计算结果复制回主机内存,打印出内阁元素的索引以及对应的平方值。计算过程采用了并行计算,这里设置了每个线程块包含32个线程,每个线程计算一个数组元素的平方。由于数组大小为10,因此只需要启动1个线程块
PI calculation in CUDA
运行代码及截图
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 
图2-4-1 只调用1个线程块算出pi所花费的时间
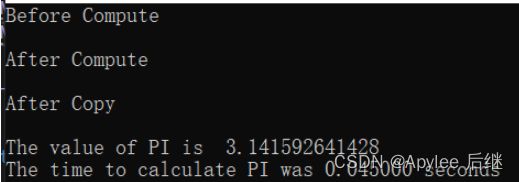
图2-4-2 根据显卡的线程块上限调整代码后,速度快了十倍之多
结果分析
使用CUDA计算圆周率的程序。程序中sumHost和sumDev两个数组分别在主机和显卡内存中存储计算结果,cudaMalloc函数和cudaMemset函数在显卡开辟空间以及清零,然后执行cal_pi函数对圆周率进行计算。计算是在显卡上并行地运行的,它会根据输入的参数计算圆周率,并将结果存储在传入的sum数组中。每个线程计算一部分区域的和,即计算左端点为 (i+0.5)*step,右端点为 (i+1.5)*step 的小矩形面积,并加到sum[idx]中,最后程序输出圆周率的值以及所花费的时间。计算前用numBlocks和threadPerBlock来分别指定线程块数量和线程数。用<<