经典卷积网络进阶--GoolgleNet详解
一.GoolgleNet概述
GoogLeNet是google推出的基于Inception模块的深度神经网络模型,在2014年的ImageNet竞赛中夺得了冠军。其性能比vgg网络更好。通常来说提高网路性能最直接的方法就是增加网络结构的深度和宽度,但这种方法往往伴随着参数计算量的增加,而且更容易出现过拟合现象。GoogLeNet提出将全连接层甚至一般的卷积都转化为稀疏连接。不同于vgg网络,提出了inception模块结构,这个创新点使得googlenet可以拥有更深,更宽的网络结构。
什么是Inception
Inception就是把多个卷积或池化操作,放在一起组装成一个网络模块,设计神经网络时以模块为单位去组装整个网络结构。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
不同大小的卷积核意味着不同大小的局部感受野,将不同卷积核的输出进行拼接意味着不同特征信息的融合。为了使各个卷积层输出的特征直接进行拼接,需要这些特征的输出具有相同的维度,因此设置卷积层相关参数时,步长固定为1,当卷积核大小分别为1*1,3*3,5*5时,像素填充padding分别取0,1,2。池化层的加入会是网络性能更好;为了减少大小为3*3和5*5的卷积核直接卷积带来的参数过大的问题,可采用1*1的卷积核先进性降维。
模块如下图所示
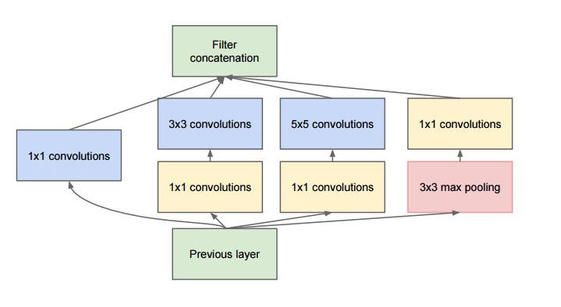
1x1卷积的作用
作用1:在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征(在相同的感受野范围能提取更强的非线性)。
作用2:使用1x1卷积进行降维,降低了计算复杂度。上图中间3x3卷积和5x5卷积前的1x1卷积都起到了这个作用。当某个卷积层输入的特征数较多,对这个输入进行卷积运算将产生巨大的计算量;如果对输入先进行降维,减少特征数后再做卷积计算量就会显著减少。图1是优化前后两种方案的乘法次数比较,同样是输入一组有192个特征、32x32大小,输出256组特征的数据,图1第一张图直接用3x3卷积实现,需要192x256x3x3x32x32=452984832次乘法;图1第二张图先用1x1的卷积降到96个特征,再用3x3卷积恢复出256组特征,需要192x96x1x1x32x32+96x256x3x3x32x32=245366784次乘法,使用1x1卷积降维的方法节省了一半的计算量。有人会问,用1x1卷积降到96个特征后特征数不就减少了么,会影响最后训练的效果么?答案是否定的,只要最后输出的特征数不变(256组),中间的降维类似于压缩的效果,并不影响最终训练的结果

图1
GoogLeNet的整体结构
GoogLeNet网络由输入层,输出层,卷积层和大量Inception层组成,如下图:

二.GoogLeNet实现MNIST分类
基于keras框架
代码:
#从keras.model中导入model模块,为函数api搭建网络做准备
from keras.models import Model
from keras.layers import Flatten,Dense,Dropout,BatchNormalization,Input,ZeroPadding2D,concatenate
from keras.layers.convolutional import Conv2D, MaxPooling2D, AveragePooling2D
from keras import regularizers #正则化
from keras.optimizers import RMSprop #优化选择器
from keras.layers import AveragePooling2D
from keras.datasets import mnist
from keras.utils import np_utils
#数据处理
(X_train,Y_train),(X_test,Y_test)=mnist.load_data()
X_test1=X_test
Y_test1=Y_test
X_train=X_train.reshape(-1,28,28,1).astype("float32")/255.0
X_test=X_test.reshape(-1,28,28,1).astype("float32")/255.0
Y_train=np_utils.to_categorical(Y_train,10)
Y_test=np_utils.to_categorical(Y_test,10)
print(X_train.shape)
print(Y_train.shape)
print(X_train.shape)
DATA_FORMAT="channels_last" #通道在前或在后的方式
#定义COV2D_lrn()函数,为方便建立googlenet网络
#这是个卷积层与局部反应归一化联合的函数
def cov2d_lrn(x,filters,kernel_size,strides=1,padding="same",activation="relu",use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',kernel_regularizer=None,
biass_regularizer=None,lrn_norm=True,weight_decay=0.0005):
#处理权重核偏置的正则化
if weight_decay:
kernel_regularizer=regularizers.l2(weight_decay)
biass_regularizer=regularizers.l2(weight_decay)
else:
kernel_regularizer=None
biass_regularizer=None
#搭建卷积层
x=Conv2D(
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding=padding,
activation=activation,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=biass_regularizer
)(x)
if lrn_norm: #是否需要添加lrn层进行归一化
x=BatchNormalization()(x)
return x
#建立inception函数
def inception_model(x,param,concat_axis,padding="same",active="relu",use_bias=True,kernel_initializer='glorot_uniform',
bias_initializer='zeros',kernel_regularizer=None,biass_regularizer=None,lrn=True,weight_decay=None):
#param是inception里面各个卷积层的核的个数的列表,比如[(2,),(3,4),(8,9)],类似(branch1,branch2,branch3,branch4)=param
(branch1,branch2,branch3,branch4)=param #各个路径的各层卷积核的个数由用户决定的,核的大小,步长都是固定的
if weight_decay: #处理正则化
kernel_regularizer=regularizers.l2(weight_decay)
biass_regularizer=regularizers.l2(weight_decay)
else:
kernel_regularizer=None
biass_regularizer=None
#inception里第一条路径
path1=Conv2D(
filters=branch1[0],
kernel_size=(1,1),
strides=1,
padding=padding,
activation=active,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer, #权重的正则化
bias_regularizer=biass_regularizer#偏置的正则化
)(x)
#第二条路径
path2=Conv2D(
filters=branch2[0],
kernel_size=(1,1),
strides=1,
padding=padding,
activation=active,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=biass_regularizer
)(x)
path2=Conv2D(
filters=branch2[1],
kernel_size=(3,3),
strides=1,
padding=padding,
activation=active,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=biass_regularizer
)(path2)
#第三条路径
path3=Conv2D(
filters=branch3[0],
kernel_size=(1,1),
strides=1,
padding=padding,
activation=active,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=biass_regularizer
)(x)
path3=Conv2D(
filters=branch3[1],
kernel_size=(5,5),
strides=1,
padding=padding,
activation=active,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=biass_regularizer
)(path3)
#第四条路径
path4=MaxPooling2D(
pool_size=(3,3),
strides=1,
padding=padding,
data_format=DATA_FORMAT
)(x)
path4=Conv2D(
filters=branch4[0],
kernel_size=(1,1),
strides=1,
padding=padding,
activation=active,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=biass_regularizer
)(path4)
#接下来返回所有路径的拼接,concat_axis是拼接的维度
#path=Concatenate(axis=concat_axis)([path1,path2,path3,path4])
path=concatenate([path1, path2, path3, path4], axis=concat_axis)
return path
#搭建Googlenet网络
def googlenet():
CONCAT_AXIS =3
x_input = Input((28, 28, 1)) # 输入数据形状28*28*1
#x_input=Input(shape=(28,28,1)) #输入数据形状28*28*1
x_input1=ZeroPadding2D((3,3))(x_input) #对输入数据进行补0填充
x=cov2d_lrn(x_input1,64,(7,7),2,padding="same",lrn_norm=False)
#搭建池化层
x=MaxPooling2D(pool_size=(2,2),strides=2,padding="same")(x)
#搭建BN层,局部响应归一化
x=BatchNormalization()(x)
x=cov2d_lrn(x,64,(1,1),1,padding="same",lrn_norm=False)
x=cov2d_lrn(x,192,(3,3),1,padding="same",lrn_norm=True)
x=MaxPooling2D(pool_size=(2,2),strides=2,padding="same")(x)
#搭建inception部分
#搭建inception3a层
x=inception_model(x,param=[(64,),(96,128),(16,32),(32,)],concat_axis=CONCAT_AXIS )
#搭建inception3b层
x=inception_model(x,param=[(128,),(128,192),(32,96),(64,)],concat_axis=CONCAT_AXIS )
#搭建池化层
x=MaxPooling2D(pool_size=(2,2),strides=2,padding="same")(x)
#搭建inception4a层
x=inception_model(x,param=[(192,),(96,208),(16,48),(64,)],concat_axis=CONCAT_AXIS )
#搭建inception4bc
x=inception_model(x,param=[(160,),(112,224),(24,64),(64,)],concat_axis=CONCAT_AXIS )
#搭建inception4c
x=inception_model(x,param=[(128,),(128,256),(24,64),(64,)],concat_axis=CONCAT_AXIS )
#搭建inception4d层
x=inception_model(x,param=[(112,),(144,288),(32,64),(64,)],concat_axis=CONCAT_AXIS )
#搭建inception4e层
x=inception_model(x,param=[(256,),(160,320),(32,128),(128,)],concat_axis=CONCAT_AXIS )
x=MaxPooling2D(pool_size=(2,2),strides=2,padding="same")(x)
#搭建inception5a层
x=inception_model(x,param=[(256,),(160,320),(32,128),(128,)],concat_axis=CONCAT_AXIS )
#搭建inception5b层
x=inception_model(x,param=[(384,),(192,384),(48,128),(128,)],concat_axis=CONCAT_AXIS )
#搭建平均池化层
x=AveragePooling2D(pool_size=(1,1),strides=1,padding="valid")(x)
#建立平坦层
x=Flatten()(x)
#搭建DROPOUT层
x=Dropout(0.4)(x)
#搭建全连接层,即输出层
x=Dense(units=10,activation="softmax")(x)
#调用MDOEL函数,定义该网络模型的输入层为X_input,输出层为x.即全连接层
model=Model(inputs=x_input,outputs=[x])
#查看网络模型的摘要
model.summary()
return model
model= googlenet()
optimizer=RMSprop(lr=1e-4)
model.compile(loss="categorical_crossentropy",optimizer=optimizer,metrics=["accuracy"])
#训练加评估模型
n_epoch=4
batch_size=128
def run_model():
training=model.fit(
X_train,
Y_train,
batch_size=batch_size,
epochs=n_epoch,
validation_split=0.25,
verbose=1
)
test=model.evaluate(X_train,Y_train,verbose=1)
print("误差:",test[0])
print("准确率:",test[1])
run_model()