01多智能体交互模型:标准博弈与随机博弈
文章目录
- 前言
- 一、博弈分层模型
-
- 1.Normal-form game(标准博弈)
-
- 根据奖励的不同分类
- repeated Normal-form game
-
- 有限重复博弈与无限重复博弈
- 更复杂的策略
- 2.随机博弈
-
- 马尔科夫性
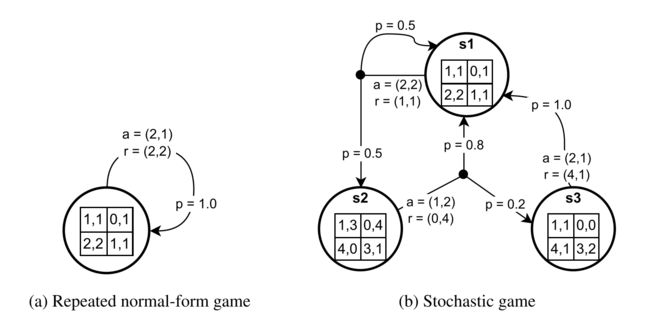
- repeated 标准博弈、随机博弈图示
前言
多智能体强化学习——博弈论模型
一、博弈分层模型

1.Normal-form game(标准博弈)
标准博弈:
每个智能体采取策略,根据策略采取对应的动作,所有动作组成联合动作空间,每个智能体根据奖励函数与联合动作空间获取奖励。
根据奖励的不同分类

主要分为三类:零和博弈、共同利益博弈、一般和博弈
零和博弈:所有智能体的奖励和为0;共同利益博弈:所有智能体采取相同的动作获取相同的奖励;一般和博弈:不同智能体之间的奖励函数没有关系
repeated Normal-form game
标准博弈描述了多个智能体的单次交互过程,通过重复标准博弈获得多次交互,得到一个序列的博弈过程。在第t个时间步,每个智能体根据随机性的策略采取相应的动作,第t个时间步的策略受到t时刻之前的联合动作的影响, h t = { a 0 , a 1 , . . . . . , a t − 1 } h^t=\{a^0,a^1,.....,a^{t-1}\} ht={a0,a1,.....,at−1},其中 a t = { a 1 t , a 2 t , . . . . . , a n t } a^t=\{a_1^t,a_2^t,.....,a_n^t\} at={a1t,a2t,.....,ant},每个智能体在t时刻根据联合动作获取到对应的奖励。
有限重复博弈与无限重复博弈
一般并不相同,有限过程会受到“end-game”的影响,智能体采取动作时会倾向选择靠近游戏结束的动作,而无限过程,可以指定每一步游戏结束的概率。
更复杂的策略
在第t个时间步,策略是由过去的整个联合状态决定的,与其内部的历史联合动作序列相关( f ( h t ) f(h^t) f(ht)),随机策略更加复杂。
2.随机博弈
随机博弈:


随机博弈过程:根据初始状态分布,在t时刻每个智能体观测当前的环境 s t s^t st,根据随机策略 π i ( a i t ∣ h t ) \pi_i (a_i^t|h^t) πi(ait∣ht),采取动作 a i t a_i^t ait,产生t时刻的联合动作 a t = { a 1 t , a 2 t , . . . . . , a n t } a^t=\{a_1^t,a_2^t,.....,a_n^t\} at={a1t,a2t,.....,ant}。随机策略是在历史序列的条件下选择动作,其中 h t = ( s 0 , a 0 , s 1 , a 1 , . . . . , s t ) h^t=(s^0,a^0,s^1,a^1,....,s^t) ht=(s0,a0,s1,a1,....,st),对于每个智能体都是全部可观测的。获取到t时刻的联合动作后,根据当前状态转移到新的状态 T ( s t , a t , s t + 1 ) \mathcal{T}(s^t,a^t,s^{t+1}) T(st,at,st+1),每个智能体会得到对应的奖励 r i t = R i ( s t , a t , s t + 1 ) r_i^t=\mathcal{R}_i(s^t,a^t,s^{t+1}) rit=Ri(st,at,st+1),经过许多时间步长后,终止在最终状态(有限过程)。
马尔科夫性
随机博弈过程遵循马尔科夫性质,下一时刻的状态与奖励只与当前的状态有关。
Pr ( s t + 1 , r t ∣ s t , a t , s t − 1 , a t − 1 , . . . , s 0 , a 0 ) = Pr ( s t + 1 , r t ∣ s t , a t ) \Pr(s^{t+1},r^t\mid s^t,a^t,s^{t-1},a^{t-1},...,s^0,a^0)=\Pr(s^{t+1},r^t\mid s^t,a^t) Pr(st+1,rt∣st,at,st−1,at−1,...,s0,a0)=Pr(st+1,rt∣st,at)
因此随机博弈也称为马尔科夫博弈过程。
repeated 标准博弈、随机博弈图示