Kafka的简介及架构
目录
消息队列
产生背景
消息队列介绍
常见的消息队列产品
应用场景
消息队列的消息模型
Kafka的基本介绍
简介
Kafka的架构
Kafka的使用
Kafka的shell命令
Kafka的Python API的操作
完成生产者代码
完成消费者代码
消息队列
产生背景
消息队列:指数据在一个容器中,从容器中一端传递到另一端过程
消息:指的数据,只不过这个这个数据存在一定流动状态
队列:指的容器,可以存储数据,这个容器具备FIFO(先进先出)特性
公共容器的特点:
1.公共性:各个程序都可以与之对接
2.FIFO特性:先进先出
3.具备高效的并发能力:能够承载海量数据
4.具备一定的容错能力:比如支持重新读取消息方案
消息队列介绍
常见的消息队列产品
MQ:message queue消息队列
activeMQ: 出现时期比较早的一款消息队列的中间件产品,在早期使用人群是非常多,目前整个社区活跃度严重下降,使用人群基本很少
rabbitMQ: 此款是目前使用人群比较多的一款消息队列的中间件的产品,社区活跃度比较高,主要是应用传统业务领域中
rocketMQ: 是阿里推出的一款消息队列的中间件的产品,目前主要是在阿里系环境中使用,目前支持的客户端比较少,主要是Java中应用较多
Kafka: Apache旗下的顶级开源消息,是一款消息队列的中间件产品,项目来源于领英,是大数据体系中目前为止最为常用的一款消息队列产品
应用场景
消息队列的应用场景:
1.应用解耦合
2.异步处理
3.限流削峰
4.消息驱动系统
消息队列的消息模型
在Java中, 为了能够集成消息队列的产品, 专门提供了一个消息队列的协议: JMS(Java Message Server) java消息服务
消息队列中两个角色:生产者(producer)和消费者(consumer)
生产者:生产/发送消息到消息队列中
消费者:从消息队列中获取消息
在JMS规范中,专门规定了两种消息消费类型:
1.点对点消费类型:一条消息最终只能被一个消费所消费,微信聊天的私聊
2.发布订阅消费模型:指一条消息最终被多个消费者所消费,微信聊天的群聊
Kafka的基本介绍
简介
Kafka是一款消息队列中间件产品,来源于领英公司,后期贡献给了Apache,目前是Apache旗下的顶级开源项目,采用语言是Scala
Kafka的特点:
1.可靠性:Kafka集群是分布式的,有多副本机制,数据可以自动复制
2.可扩展性:Kafka集群可以灵活的调整,在线扩容
3.耐用性:Kafka数据保存在磁盘上,数据有多副本机制,数据持久化,一定程度上防止数据丢失
4.高性能:Kafka可以存储海量的数据,虽然是使用磁盘进行存储,但是Kafka有各种优化手段(例如:磁盘的顺序读写,零拷贝等)提高数据的读写速度(吞吐量)
Kafka的架构
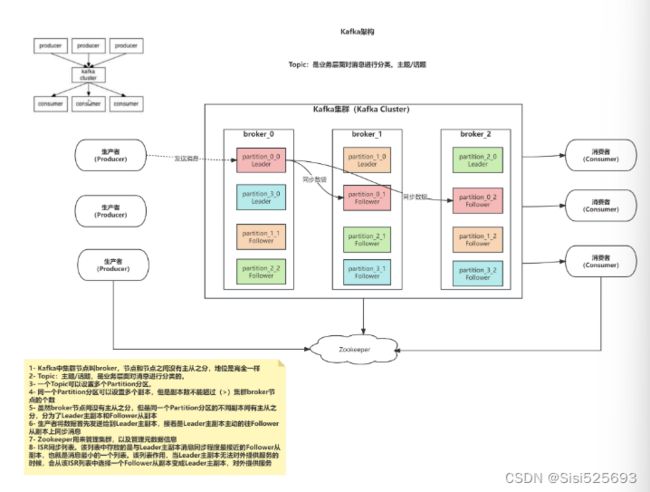
1. Kafka中集群节点叫broker,节点与节点之间没有主从之分,地位是完全一样
2.Topic:主题/话题,是业务层面对消息进行分类的
3.一个Topic可以设置多个分区
4.同一个partition分区可以设置多个副本,但是副本数不能超过(>)集群broker节点的个数
5.broker节点间没有主从之分,但是同一个partition分区的不同副本间有主从之分,分为Leader主副本和Follwer从副本
6.生产者将数据首先发送给到Leader主副本,接着是Leader主副本主动往Follower从副本上同步消息
7.Zookeeper用来管理集群,以及管理元数据信息
8.ISR同步列表,该列表中存放的是与Leader主副本消息同步程度最接近的Follower从副本,也就是消息最小的一个列表,该列表的作用是当Leader主副本无法对外提供服务的时候,会从该ISR列表中选择一个Follower从副本变成Leader主副本,对外提供服务
相关名词
Kafka Cluster : kafka集群
Topic : 主题/话题
Broker : Kafka中的节点
Producer : 生产者,负责生产/发送消息到Kafka中
Consumer : 消费者,负责从Kafka中获取消息
Partition : 分区,一个Topic可以设置多个分区,没有数量限制
Kafka的使用
Kafka的shell命令
Kafka本质上是一个消息队列中间件产品,主要负责消息数据的传递,也就说学习Kafka 也就是学习如何使用Kafka生产数据,以及如何使用Kafka来消费数据
创建Topic
./kafka-topics.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --create --topic test02 --partitions 4 --replication-factor 2
参数说明:
--bootstrap-server:kafka集群中broker连接信息
--create:指定操作类型,这里是新建Topic
--topic:指定要新建的Topic名称
--partitions:设置Topic的分区数
--replicattion-factor:设置Topic分区的的副本数
注意:如果副本数超过了集群broker节点个数,会报错
查看Topic
./kafka-topics.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --list
参数说明:
--bootstrap-server: Kafka集群中broker连接信息
--list: 指定操作类型。这里是查看Kafka集群上所有可用的Topic列表
查看具体Topic
./kafka-topics.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --describe --topic test04
参数说明:
--bootstrap-server: Kafka集群中broker连接信息
--describe: 指定操作类型。这里是查看具体Topic信息
模拟生产者Producer
./kafka-console-producer.sh --broker-list node1.itcast.cn:9092,node2.itcast.cn:9092 --topic test04
参数说明:
--broker-list: Kafka集群中broker连接信息
--topic: 指定要将消息发送到哪个具体的Topic
模拟消费者Consumer
./kafka-console-consumer.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --topic test04
参数说明:
--bootstrap-server: Kafka集群中broker连接信息
--topic: 指定要从哪个Topic中消费消息
--from-beginning: 指定该参数以后,会从最旧的地方开始消费
latest: 消费者(默认)从最新的地方开始消费
--max-messages: 最多消费的条数。满足条数后,就会自动结束
--group: 指定消费组名称。一个消费者只能属于一个消费组;一个消费组里面可以有多个消费者。同一个Topic中的同一条数据,只能被同一个消费组中的一个消费者所消费
在工作中的参数一般如何使用?
答: 推荐latest、--max-messages、--group一同使用。因为实际企业中Topic的数据量是特别大的,消费、打印都需要消耗服务器的资源,如果不限定消费的最大条数,可能造成服务器宕机。
修改Topic
./kafka-topics.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --alter --topic test01 --partitions 10
分区: 只能增大,不能减小。而且没有数量限制
副本: 既不能增大,也不能减小
查看消费组中有多少个消费者
./kafka-consumer-groups.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --group g_01 --members --describe
Kafka的Python API的操作
准备工作:在服务器的节点上安装一个python用于操作Kafka的库
安装命令:
python -m pip install kafka-python -i https://pypi.tuna.tsinghua.edu.cn/simpleAPI使用的参考文档:
https://kafka-python.readthedocs.io/en/master/usage.html#kafkaproducer
完成生产者代码
import time
from kafka import KafkaProducer
# 同步发送
def sync_send():
global topic, partition, offset
# 2.1- 同步发送数据/消息
metadata = producer.send("test01", value=f"hello_java_{i}".encode("UTF-8")).get()
# metadata = producer.send("test03",value=f"hello_spark_{i}".encode("UTF-8")).get()
# 2.2- 获取元信息中的内容
topic = metadata.topic
partition = metadata.partition
"""
offset消息偏移量,从0开始编号。也就是一条消息在分区中的序号/索引
在不同分区间,消息偏移量是无序
在同一个分区里面,消息偏移量是有序
"""
offset = metadata.offset
print(f"{topic},{partition},{offset},{metadata}")
if __name__ == '__main__':
# 1- 创建生产者
producer = KafkaProducer(
bootstrap_servers=["node1.itcast.cn:9092","node2.itcast.cn:9092"]
)
# 2- 发送消息
for i in range(10):
# 同步发送
# sync_send()
# 2.3- 异步发送
"""
异步发送,需要等待一下,或者明确关闭Producer生产者
"""
producer.send("test01", value=f"hello_hive_{i}".encode("UTF-8"))
time.sleep(1)
# 3- 释放资源/关闭生产者
# producer.close()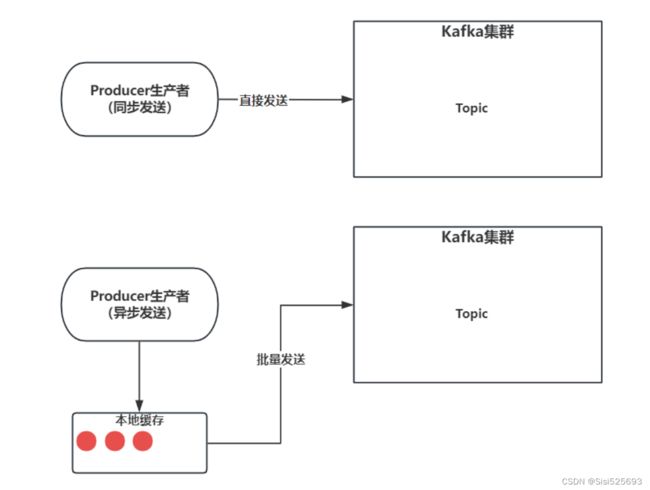
完成消费者代码
from kafka import KafkaConsumer
if __name__ == '__main__':
# 1- 创建消费者
consumer = KafkaConsumer(
"test01",
bootstrap_servers=["node1.itcast.cn:9092", "node2.itcast.cn:9092"]
)
# 2- 消费消息
for msg in consumer:
topic = msg.topic
partition = msg.partition
offset = msg.offset
# key和value消费出来都是bytes数据类型,需要进行解码
key = msg.key
value = msg.value
print(f"{topic},{partition},{offset},{key},{value.decode('UTF-8')},{msg}")