【手搓深度学习算法】用逻辑回归分类Iris数据集-线性数据篇
用逻辑回归分类Iris数据集-线性数据篇
前言
逻辑斯蒂回归是一种广泛使用的分类方法,它是基于条件概率密度函数的最大似然估计的。它的主要思想是将输入空间划分为多个子空间,每个子空间对应一个类别。在每个子空间内部,我们假设输入变量的取值与类别标签的概率成正比。
在逻辑斯蒂回归中,我们首先通过数据进行线性回归,得到的结果再通过sigmoid函数转化为概率,这样就可以得到每个类别的概率。然后,我们可以通过设置一个阈值,如果概率大于阈值,我们就认为这个样本属于这个类别,否则就属于其他类别。这就是逻辑斯蒂回归的基本原理。
逻辑斯蒂回归在现实生活中有很多应用,比如垃圾邮件分类、疾病诊断等。它可以处理非线性关系,而且它的预测结果是概率,这对于处理分类问题非常有用。
在深度学习中,逻辑斯蒂回归的作用主要体现在两个方面:一是作为一种基础的分类方法,它可以用于二分类问题,比如判断一个邮件是否为垃圾邮件;二是作为一种特征提取方法,它可以用于提取输入数据的特征,这些特征可以被其他深度学习模型使用。
本文介绍了逻辑回归算法的其中一种应用场景-对线性的多分类数据集进行分类,后续还将总结逻辑回归在非线性数据集中的应用方法。
本文首先使用基础python和numpy进行基础代码实现,然后引入一个科学计算库
from scipy.optimize import minimize
来优化梯度下降过程,并且比较前后的准确率差异
名词解释
回归
很多初学(复习)统计学或者深度学习算法的同学(包括我),对“回归”这个名词可能感觉有点疑惑,因为它既熟悉又陌生,熟悉是因为它在现实生活中也很常见,比如香港回归,澳门回归。。。,陌生的是当它跟统计学名词联系在一起,又会让人有点摸不着头脑,什么线性回归,逻辑斯蒂回归。。。,为此,我专门查找了相关资料,总结如下:
在统计学和深度学习中,“回归”这个术语的含义主要是关于预测一个连续的目标变量。这个目标变量可以是任何可以连续变化的东西,比如销售额、房价、股票价格等。在这种情况下,“回归”的意思是“倒推”或者“预测”。
在统计学中,我们使用回归分析来研究一个或多个自变量(即影响因素)与一个因变量(即我们想要预测的结果)之间的关系。例如,我们可能会使用回归分析来研究房价与房屋面积、位置、年份等因素的关系。在这种情况下,我们的目标是找到一个函数,这个函数可以根据这些因素预测房价。这就是“回归”的含义:我们是在“倒推”或者“预测”房价。
在深度学习中,我们也使用回归模型,但是这里的“回归”更多的是指预测一个连续的目标变量。例如,我们可能会使用深度学习的回归模型来预测一个物品的评分,或者预测一个人的年龄。在这种情况下,我们的目标是找到一个函数,这个函数可以根据一些输入特征预测这个连续的目标变量。这也是“回归”的含义:我们是在“倒推”或者“预测”这个连续的目标变量。
总的来说,无论是在统计学还是在深度学习中,“回归”的含义都是“倒推”或者“预测”一个连续的目标变量。这个目标变量可以是任何可以连续变化的东西,比如销售额、房价、股票价格、评分、年龄等。我们的目标是找到一个函数,这个函数可以根据一些输入特征预测这个连续的目标变量。
逻辑斯蒂回归和线性回归的异同点
逻辑斯蒂回归和线性回归都是回归分析的一种,但它们的主要区别在于处理的问题类型和输出结果的形式。
相同点:
-
回归分析:逻辑斯蒂回归和线性回归都是回归分析的一种,它们都试图找到一个或多个自变量(即影响因素)与一个因变量(即我们想要预测的结果)之间的关系。
-
预测连续变量:逻辑斯蒂回归和线性回归都是用来预测连续变量的。在逻辑斯蒂回归中,我们通过sigmoid函数将线性回归的结果转化为概率,从而得到每个类别的概率。
不同点:
-
处理问题类型:线性回归主要用于处理连续的目标变量,而逻辑斯蒂回归主要用于处理分类问题。
-
输出结果的形式:线性回归的输出结果是一个连续的值,而逻辑斯蒂回归的输出结果是一个概率值,通常用于二分类问题。
-
处理非线性关系:线性回归只能处理线性关系,而逻辑斯蒂回归可以处理非线性关系。
实现
工具函数
Sigmoid
Sigmoid函数是一种常用的激活函数,它将任意实数映射到0和1之间。Sigmoid函数的定义如下:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
其中, x x x是输入, σ ( x ) \sigma(x) σ(x)是输出。
Sigmoid函数的图像如下(不平滑因为是我自己生成的。。。):

Sigmoid函数的主要特性包括:
-
单调递增:对于所有的 x x x, σ ( x ) \sigma(x) σ(x)都是单调递增的。
-
输出范围在0和1之间:对于所有的 x x x, 0 ≤ σ ( x ) ≤ 1 0 \leq \sigma(x) \leq 1 0≤σ(x)≤1。
-
可微:Sigmoid函数是可微的,这使得它可以用于神经网络的反向传播算法。
def sigmoid(data):
return 1 / (1+np.exp(-data))
逻辑斯蒂回归类
以下代码在名为"LogisticRegression"的类中
初始化
将传入的数据集和标签记录下来以便进一步处理,同时初始化权重矩阵
def __init__(self, data,labels) -> None:
self.data = data
self.labels = labels
self.unique_labels = np.unique(labels) #取标签中的类的名称的集合
self.num_examples = self.data.shape[0] #取数据集中样本的数量
self.num_features = self.data.shape[1] #取数据集中的特征个数
num_unique_labels = self.unique_labels.shape[0] #取标签中类的个数
self.theta = np.zeros((num_unique_labels,self.num_features)) #初始化权重向量,因为我们是多分类,所以权重是 “分类数量 x 特征个数”的矩阵
训练函数
对每个可能的分类执行训练过程,因为逻辑斯蒂回归通常用于处理二分类问题,所以每次都将当前分类的标签置为“1”,其他分类的标签置为“0”
def train(self, lr = 0.01, max_iter = 1000):
cost_histories = [] #记录损失历史记录,以便可视化
for label_index, unique_label in enumerate(self.unique_labels): #对所有可能的分类进行遍历
current_initial_theta = np.copy(self.theta[label_index].reshape(self.num_features, 1)) #复制对应的权重向量,以避免直接修改
current_labels = (self.labels == unique_label).astype(float) #等于当前标签的置为1,否则为0
(current_theta, cost_history) = LogisticRegression.gradient_descent(self.data, current_labels, current_initial_theta, max_iter) #执行梯度下降过程
self.theta[label_index] = current_theta.T #记录当前分类最终的权重向量
cost_histories.append(cost_history) #记录当前分类最终的损失历史记录
return cost_histories, self.theta
梯度下降过程
在规定的迭代次数里执行梯度下降,每次权重向量都减去学习率乘以当前梯度,通过迭代优化模型的参数(也就是权重向量 θ \theta θ),使得模型的预测结果与真实标签之间的差异(也就是损失函数)最小。
gradient_descent 方法的主要任务是执行梯度下降的迭代过程。它接收五个参数:数据集 data、标签 labels、当前的初始权重向量 current_initial_theta、学习率 lr 和最大迭代次数 max_iter。在每次迭代中,它会调用 gradient_step 方法计算梯度,然后根据梯度更新权重向量。同时,它还会记录每次迭代后的损失值,以便于后续的可视化或者调试。
gradient_step 方法的主要任务是计算梯度。它接收三个参数:数据集 data、标签 labels 和当前的权重向量 theta。首先,它会计算预测值 predictions,然后计算预测值与真实标签之间的差异 label_diff。最后,它会计算梯度 gradients,并返回梯度的平均值。
在这里,梯度的计算公式为:
∇ θ J ( θ ) = 1 N ∑ i = 1 N ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) \nabla_\theta J(\theta) = \frac{1}{N} \sum_{i=1}^{N} (h_\theta(x^{(i)}) - y^{(i)})x^{(i)} ∇θJ(θ)=N1i=1∑N(hθ(x(i))−y(i))x(i)
其中, N N N 是数据集的大小, h θ ( x ( i ) ) h_\theta(x^{(i)}) hθ(x(i)) 是预测值, y ( i ) y^{(i)} y(i) 是真实标签, x ( i ) x^{(i)} x(i) 是第 i i i 个数据点。
这个公式的含义是,对于每一个数据点,我们都计算了预测值与真实标签之间的差异,然后乘以该数据点的特征向量,最后将所有数据点的结果加起来,再除以数据集的大小,得到的就是梯度。
这个梯度反映了模型预测结果与真实标签之间的差异,我们希望通过不断地调整权重向量,使得这个差异越来越小,从而提高模型的预测效果。
def gradient_descent(data, labels, current_initial_theta, lr, max_iter):
cost_history = [] #损失历史
num_features = data.shape[1] #特征数量
optimized_theta = current_initial_theta #取初始权重
for _ in range(max_iter): #在规定的迭代次数范围内迭代
optimized_theta -= float(lr) * LogisticRegression.gradient_step(data, labels, optimized_theta).reshape(num_features, 1) #执行单步更新权重
cost_history.append(LogisticRegression.cost_function(data, labels, optimized_theta)) # 记录损失历史
optimized_theta = optimized_theta.reshape(num_features, 1)
return optimized_theta, cost_history
def gradient_step(data, labels, theta):
num_examples = labels.shape[0] #样本数量
predictions = LogisticRegression.predict(data.T, theta) #特征和权重的点积然后执行sigmoid,得到概率
label_diff = predictions - labels #差异
gradients = (1/num_examples)*np.dot(data.T, label_diff) #计算梯度,差异和数据的点积除以样本数量
return gradients.T.flatten() #将梯度转换为一维
损失函数
主要功能是计算模型的预测结果与真实标签之间的差异,也就是损失函数。
cost_function 方法的主要任务是计算损失函数。它接收三个参数:数据集 data、标签 labels 和当前的权重向量 theta。
首先,它会计算预测值 prediction,
然后根据预测值和真实标签的关系,计算两部分的损失 y_is_set_cost 和 y_is_not_set_cost。
最后,它会将这两部分的损失相加,然后除以数据集的大小,得到的就是损失函数。
在这里,损失函数的计算公式为:
J ( θ ) = − 1 N [ ∑ i = 1 N y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J(\theta) = -\frac{1}{N}\left[\sum_{i=1}^{N}y^{(i)}\log(h_\theta(x^{(i)})) + (1 - y^{(i)})\log(1 - h_\theta(x^{(i)}))\right] J(θ)=−N1[i=1∑Ny(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
其中, N N N 是数据集的大小, y ( i ) y^{(i)} y(i) 是第 i i i 个数据点的真实标签, h θ ( x ( i ) ) h_\theta(x^{(i)}) hθ(x(i)) 是第 i i i 个数据点的预测值。
这个公式的含义是,对于每一个数据点,如果它的真实标签是1,那么我们就计算 log ( h θ ( x ( i ) ) ) \log(h_\theta(x^{(i)})) log(hθ(x(i))) 的值;如果它的真实标签是0,因为 h θ ( x ( i ) ) h_\theta(x^{(i)}) hθ(x(i)) 计算的是 p r e d i c t = 1 predict = 1 predict=1的概率,所以我们就计算 log ( 1 − h θ ( x ( i ) ) ) \log(1 - h_\theta(x^{(i)})) log(1−hθ(x(i))) 的值。然后,我们将所有数据点的结果加起来,再除以数据集的大小,得到的就是损失函数。
损失函数反映了模型预测结果与真实标签之间的差异,我们希望通过不断地调整权重向量,使得这个差异越来越小,从而提高模型的预测效果。
def cost_function(data, labels, theta):
num_examples = data.shape[0] #样本数量
prediction = LogisticRegression.predict(data.T, theta) #特征和权重的点积然后执行sigmoid,得到概率
y_is_set_cost = np.dot(labels[labels == 1].T, np.log(prediction[labels == 1])) #当标签等于1时的权重向量
y_is_not_set_cost = np.dot(1-labels[labels == 0].T, np.log(1-prediction[labels == 0])) #当标签等于0时的权重向量
cost = (-1/num_examples) * (y_is_set_cost+y_is_not_set_cost) # 计算整体损失
return cost
预测计算函数
特征和权重的点积然后计算Sigmoid得到概率
def predict(data, theta):
predictions = sigmoid(np.dot(data.T, theta))
return predictions
验证计算函数
验证计算函数先对输入特征矩阵进行预测计算,然后对每个样本,计算其概率最大值,最后将每个样本的最佳预测分类和每个样本属于三个分类的概率返回。
def predict_test(self, data):
num_examples = data.shape[0] #样本数量
prob = LogisticRegression.predict(data.T, self.theta.T) #计算预测值
max_prob_index = np.argmax(prob, axis = 1) #最大的概率值的index
class_prediction = np.empty(max_prob_index.shape, dtype=object) # 初始化预测结果
for index,label in enumerate(self.unique_labels):
class_prediction[max_prob_index == index] = label # 取预测值
return class_prediction.reshape((num_examples,1)), prob
完整流程
逻辑回归模型的主入口。它的主要任务是加载数据集,划分训练集和测试集,训练模型,并评估模型的性能。
-
加载数据集:首先,它从指定的路径加载 Iris 数据集,并将其转换为 NumPy 数组。然后,它打乱数据集的顺序,以确保训练集和测试集的随机性。
-
划分训练集和测试集:然后,它将数据集划分为训练集和测试集。训练集用于训练模型,测试集用于评估模型的性能。
-
预处理数据:接下来,它将训练集和测试集的标签转换为整数形式,以便于模型的训练和预测。
-
训练模型:然后,它创建一个逻辑回归模型,并使用训练集进行训练。训练过程中,模型会不断地调整其权重向量,以减少预测结果与真实标签之间的差异。
-
评估模型:最后,它使用测试集对模型进行评估,计算模型的准确率。同时,它还会打印出模型预测错误的样本信息,以及每个样本的预测概率。
这个 main 函数的主要目的是实现一个完整的逻辑回归模型的流程,包括数据加载、预处理、模型训练和评估。
import pandas as pd
import matplotlib.pyplot as plt
def main():
iris_dataset = "J:\\MachineLearning\\数据集\\Iris\\iris.data"
dataset_src = pd.read_csv(iris_dataset).values
np.random.shuffle(dataset_src)
print("The shape of original dataset is {}".format(dataset_src.shape))
train_data = dataset_src[:int(len(dataset_src)*0.8)]
test_data = dataset_src[int(len(dataset_src)*0.8):]
train_dataset = train_data[:, :-1].astype('float')
train_label = train_data[:, -1].reshape(-1,1)
test_dataset = test_data[:, :-1].astype('float')
test_label = test_data[:, -1].reshape(-1,1)
print("The shape of train dataset is {}".format(train_dataset.shape))
print("The shape of test dataset is {}".format(test_dataset.shape))
print("The shape of train label is {}".format(train_label.shape))
print("The shape of test label is {}".format(test_label.shape))
# 创建一个字典,将每种花的名称映射到一个唯一的整数
flower_dict = {
'Iris-versicolor': 0,
'Iris-setosa': 1,
'Iris-virginica': 2
}
# 使用字典来转换数组
converted_array = [[flower_dict[item[0]]] for item in train_label]
train_label = np.array(converted_array).reshape(-1,1).astype('int')
converted_array = [[flower_dict[item[0]]] for item in test_label]
test_label = np.array(converted_array).reshape(-1,1).astype('int')
print(train_dataset)
print(train_label)
logistic_reg = LogisticRegression(np.array(train_dataset), np.array(train_label))
(loss_history, theta) = logistic_reg.train(5000)
plt.plot(loss_history[0])
plt.plot(loss_history[1])
plt.plot(loss_history[2])
prediction, prop = logistic_reg.predict_test(test_dataset)
accuracy = sum(prediction == test_label) / len(test_label)
print("Accuracy is {}".format(accuracy))
#fail_predict = [prediction[prediction != test_label], test_label[prediction != test_label]]
fail_predict = []
for index, item in enumerate(prediction.flatten()):
if (item != test_label.flatten()[index]):
info = {}
info["index"]=index
info["predict"]=item
info["actual"]=test_label.flatten()[index]
fail_predict.append(info)
for predict_info in fail_predict:
print("Predict is {} prop is {}, actual is {} prop is {}".format(
predict_info["predict"], prop[predict_info["index"], [int(predict_info["predict"])]],
predict_info["actual"], prop[predict_info["index"], [int(predict_info["actual"])]]))
print(np.array(fail_predict).shape)
fail_predict = []
prediction, prop = logistic_reg.predict_test(train_dataset)
accuracy = sum(prediction == train_label) / len(train_label)
print("Accuracy is {}".format(accuracy))
for index, item in enumerate(prediction.flatten()):
if (item != train_label.flatten()[index]):
info = {}
info["index"]=index
info["predict"]=item
info["actual"]=train_label.flatten()[index]
fail_predict.append(info)
for predict_info in fail_predict:
print("Predict is {} prop is {}, actual is {} prop is {}".format(
predict_info["predict"], prop[predict_info["index"], [int(predict_info["predict"])]],
predict_info["actual"], prop[predict_info["index"], [int(predict_info["actual"])]]))
if (__name__ == "__main__"):
main()
查看基础实现的损失下降和准确率
lr = 0.001, iter = 10000
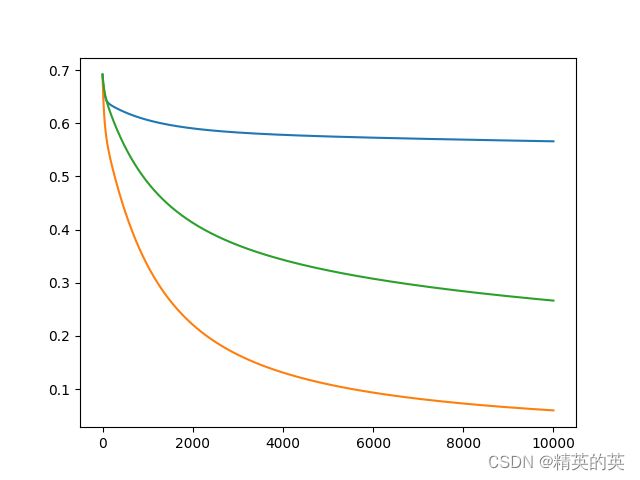

使用minimize函数进行训练
以下是关于minimize函数的介绍
minimize 是 SciPy 库中的一个函数,它用于求解非线性优化问题。该函数的主要目标是找到一个最小值点,使得目标函数的值最小。
minimize 函数的基本用法如下:
from scipy.optimize import minimize
def objective_func(x):
return x[0]**2 + x[1]**2
initial_guess = [2, 2]
result = minimize(objective_func, initial_guess)
print(result.x)
在这个例子中,objective_func 是我们想要最小化的目标函数,initial_guess 是我们对最小值点的初始猜测。minimize 函数会返回一个结果对象,其中 result.x 是找到的最小值点,result.fun 是在最小值点处的目标函数值。
minimize 函数支持多种优化算法,包括梯度下降法、牛顿法、BFGS 法等。你可以通过 method 参数来指定使用哪种优化算法。例如,如果你想使用梯度下降法,你可以这样调用 minimize 函数:
result = minimize(objective_func, initial_guess, method='SGD')
此外,minimize 函数还支持自动微分,这意味着你可以传入一个未经微分的目标函数,minimize 函数会自动计算其梯度。如果你已经计算了梯度,或者你想使用自己的梯度计算方法,你可以通过 jac 参数来提供梯度函数。
我们将上面介绍的“gradient_descent”函数替换成使用minimize的形式:
def gradient_descent(data, labels, current_initial_theta, max_iter):
cost_history = []
num_features = data.shape[1]
#scipy.optimize.minimize`函数被用于实现梯度下降算法。这个函数的主要作用是找到一个最小值点,使得目标函数的值最小。
result = minimize(
#要优化的目标
fun = lambda current_theta:LogisticRegression.cost_function(data, labels, current_theta.reshape(num_features, 1)),
#初始化的权重参数
x0 = current_initial_theta.flatten(),
#选择优化策略, 表示使用共轭梯度法进行优化
method='CG',
#梯度下降迭代计算公式
jac= lambda current_theta:LogisticRegression.gradient_step(data, labels,current_theta.reshape(num_features, 1)),
#记录结果
callback = lambda current_theta:cost_history.append(LogisticRegression.cost_function(data, labels, current_theta.reshape(num_features, 1))),
#迭代次数
options = {'maxiter':max_iter}
)
if not (result.success):
raise ArithmeticError('Can not minimize cost function ' + result.message)
#minimize`函数的输出是一个结果对象,其中`result.x`是找到的最小值点,`result.fun`是在最小值点处的目标函数值。
optimized_theta = result.x.reshape(num_features, 1)
return optimized_theta, cost_history
使用minimize函数进行梯度下降的损失变化趋势和准确率
可以看到损失收敛的很快,而且准确率也更高


完整代码
import numpy as np
from scipy.optimize import minimize
def sigmoid(data):
return 1 / (1+np.exp(-data))
def prepare_data(data, normalize_data=True):
assert isinstance(data, np.ndarray), "Data must be a numpy array"
# 标准化特征矩阵(可选)
if normalize_data:
features_mean = np.mean(data, axis=0) #特征的平均值
features_dev = np.std(data, axis=0) #特征的标准偏差
features = (data - features_mean) / features_dev #标准化数据
else:
features_mean = None
features_dev = None
features = data
data_processed = features
# 返回处理后的数据
return data_processed, features_mean, features_dev
class LogisticRegression:
'''
1. 对数据进行预处理操作
2. 先得到所有的特征个数
3. 初始化参数矩阵
'''
def __init__(self, data,labels) -> None:
self.data = data
self.labels = labels
self.unique_labels = np.unique(labels) #取标签中的类的名称的集合
self.num_examples = self.data.shape[0] #取数据集中样本的数量
self.num_features = self.data.shape[1] #取数据集中的特征个数
num_unique_labels = self.unique_labels.shape[0] #取标签中类的个数
self.theta = np.zeros((num_unique_labels,self.num_features)) #初始化权重向量,因为我们是多分类,所以权重是 “分类数量 x 特征个数”的矩阵
def train(self, lr = 0.01, max_iter = 1000):
cost_histories = [] #记录损失历史记录,以便可视化
for label_index, unique_label in enumerate(self.unique_labels): #对所有可能的分类进行遍历
current_initial_theta = np.copy(self.theta[label_index].reshape(self.num_features, 1)) #复制对应的权重向量,以避免直接修改
current_labels = (self.labels == unique_label).astype(float) #等于当前标签的置为1,否则为0
(current_theta, cost_history) = LogisticRegression.gradient_descent(self.data, current_labels, current_initial_theta, max_iter) #执行梯度下降过程
#(current_theta, cost_history) = LogisticRegression.gradient_descent(self.data, current_labels, current_initial_theta, '''lr,''' max_iter) #执行梯度下降过程
self.theta[label_index] = current_theta.T #记录当前分类最终的权重向量
cost_histories.append(cost_history) #记录当前分类最终的损失历史记录
return cost_histories, self.theta
@staticmethod
def gradient_descent(data, labels, current_initial_theta, max_iter):
cost_history = []
num_features = data.shape[1]
#scipy.optimize.minimize`函数被用于实现梯度下降算法。这个函数的主要作用是找到一个最小值点,使得目标函数的值最小。
result = minimize(
#要优化的目标
fun = lambda current_theta:LogisticRegression.cost_function(data, labels, current_theta.reshape(num_features, 1)),
#初始化的权重参数
x0 = current_initial_theta.flatten(),
#选择优化策略, 表示使用共轭梯度法进行优化
method='CG',
#梯度下降迭代计算公式
jac= lambda current_theta:LogisticRegression.gradient_step(data, labels,current_theta.reshape(num_features, 1)),
#记录结果
callback = lambda current_theta:cost_history.append(LogisticRegression.cost_function(data, labels, current_theta.reshape(num_features, 1))),
#迭代次数
options = {'maxiter':max_iter}
)
if not (result.success):
raise ArithmeticError('Can not minimize cost function ' + result.message)
#minimize`函数的输出是一个结果对象,其中`result.x`是找到的最小值点,`result.fun`是在最小值点处的目标函数值。
optimized_theta = result.x.reshape(num_features, 1)
return optimized_theta, cost_history
'''
@staticmethod
def gradient_descent(data, labels, current_initial_theta, lr, max_iter):
cost_history = [] #损失历史
num_features = data.shape[1] #特征数量
optimized_theta = current_initial_theta #取初始权重
for index, _ in enumerate(range(max_iter)): #在规定的迭代次数范围内迭代
optimized_theta -= float(lr) * LogisticRegression.gradient_step(data, labels, optimized_theta).reshape(num_features, 1) #执行单步更新权重
loss = LogisticRegression.cost_function(data, labels, optimized_theta)
if (index % 10 == 0):
print("Step {} loss is {}".format(index, loss))
cost_history.append(loss) # 记录损失历史
optimized_theta = optimized_theta.reshape(num_features, 1)
return optimized_theta, cost_history
'''
@staticmethod
def gradient_step(data, labels, theta):
num_examples = labels.shape[0] #样本数量
predictions = LogisticRegression.predict(data.T, theta) #特征和权重的点积然后执行sigmoid,得到概率
label_diff = predictions - labels #差异
gradients = (1/num_examples)*np.dot(data.T, label_diff) #计算梯度,差异和数据的点积除以样本数量
return gradients.T.flatten() #将梯度转换为一维
@staticmethod
def cost_function(data, labels, theta):
num_examples = data.shape[0] #样本数量
prediction = LogisticRegression.predict(data.T, theta) #特征和权重的点积然后执行sigmoid,得到概率
y_is_set_cost = np.dot(labels[labels == 1].T, np.log(prediction[labels == 1])) #当标签等于1时的权重向量
y_is_not_set_cost = np.dot(1-labels[labels == 0].T, np.log(1-prediction[labels == 0])) #当标签等于0时的权重向量
cost = (-1/num_examples) * (y_is_set_cost+y_is_not_set_cost) # 计算整体损失
return cost
@staticmethod
def predict(data, theta):
predictions = sigmoid(np.dot(data.T, theta))
return predictions
def predict_test(self, data):
num_examples = data.shape[0] #样本数量
prob = LogisticRegression.predict(data.T, self.theta.T) #计算预测值
max_prob_index = np.argmax(prob, axis = 1) #最大的概率值的index
class_prediction = np.empty(max_prob_index.shape, dtype=object) # 初始化预测结果
for index,label in enumerate(self.unique_labels):
class_prediction[max_prob_index == index] = label # 取预测值
return class_prediction.reshape((num_examples,1)), prob
import pandas as pd
import matplotlib.pyplot as plt
def main():
iris_dataset = "J:\\MachineLearning\\数据集\\Iris\\iris.data"
dataset_src = pd.read_csv(iris_dataset).values
np.random.shuffle(dataset_src)
print("The shape of original dataset is {}".format(dataset_src.shape))
train_data = dataset_src[:int(len(dataset_src)*0.8)]
test_data = dataset_src[int(len(dataset_src)*0.8):]
train_dataset = train_data[:, :-1].astype('float')
train_label = train_data[:, -1].reshape(-1,1)
test_dataset = test_data[:, :-1].astype('float')
test_label = test_data[:, -1].reshape(-1,1)
print("The shape of train dataset is {}".format(train_dataset.shape))
print("The shape of test dataset is {}".format(test_dataset.shape))
print("The shape of train label is {}".format(train_label.shape))
print("The shape of test label is {}".format(test_label.shape))
# 创建一个字典,将每种花的名称映射到一个唯一的整数
flower_dict = {
'Iris-versicolor': 0,
'Iris-setosa': 1,
'Iris-virginica': 2
}
# 使用字典来转换数组
converted_array = [[flower_dict[item[0]]] for item in train_label]
train_label = np.array(converted_array).reshape(-1,1).astype('int')
converted_array = [[flower_dict[item[0]]] for item in test_label]
test_label = np.array(converted_array).reshape(-1,1).astype('int')
print(train_dataset)
print(train_label)
logistic_reg = LogisticRegression(np.array(train_dataset), np.array(train_label))
(loss_history, theta) = logistic_reg.train(lr=0.001, max_iter= 10000)
plt.plot(loss_history[0])
plt.plot(loss_history[1])
plt.plot(loss_history[2])
prediction, prop = logistic_reg.predict_test(test_dataset)
accuracy = sum(prediction == test_label) / len(test_label)
print("Accuracy is {}".format(accuracy))
#fail_predict = [prediction[prediction != test_label], test_label[prediction != test_label]]
fail_predict = []
for index, item in enumerate(prediction.flatten()):
if (item != test_label.flatten()[index]):
info = {}
info["index"]=index
info["predict"]=item
info["actual"]=test_label.flatten()[index]
fail_predict.append(info)
for predict_info in fail_predict:
print("Predict is {} prop is {}, actual is {} prop is {}".format(
predict_info["predict"], prop[predict_info["index"], [int(predict_info["predict"])]],
predict_info["actual"], prop[predict_info["index"], [int(predict_info["actual"])]]))
print(np.array(fail_predict).shape)
fail_predict = []
prediction, prop = logistic_reg.predict_test(train_dataset)
accuracy = sum(prediction == train_label) / len(train_label)
print("Accuracy is {}".format(accuracy))
for index, item in enumerate(prediction.flatten()):
if (item != train_label.flatten()[index]):
info = {}
info["index"]=index
info["predict"]=item
info["actual"]=train_label.flatten()[index]
fail_predict.append(info)
for predict_info in fail_predict:
print("Predict is {} prop is {}, actual is {} prop is {}".format(
predict_info["predict"], prop[predict_info["index"], [int(predict_info["predict"])]],
predict_info["actual"], prop[predict_info["index"], [int(predict_info["actual"])]]))
if (__name__ == "__main__"):
main()