FCNVMB_paper_with_code1代码部分解释
——基于pytorch ,python3.8
1. LibConfig
——库文件,导入包
2. ParamConfig
——定义参数。
ReUse每次是否重新训练;DataDin地震数据维度;ModelDin速度模型维度;data_dsp_blk输入的下采样率;label_dsp_blk输出的下采样率;dh空间间隔。
3. PathConfig
——路径设置
4. forward.py
——使用正演方式生成地震数据,进行训练
eng = matlab.engine.start_matlab()-
将
matlab.engine包导入 -
通过调用
start_matlab启动新的 MATLAB进程。start_matlab函数返回 Python 对象eng,您可以通过该对象传递数据和调用由 MATLAB 执行的函数。
5. func
5.1. DataLoad_Test.py
——加载测试数据
5.2. DataLoad_Train.py
——加载训练数据。
5.2.1. scipy.io.loadmat("FilePath"):
读取路径为"FilePath"的.mat文件,函数返回值为字典类型dict。之后还需要通过后续操作将值提取出来(字典操作来提取键值对的值)。
关于为什么scipy.io.loadmat("FilePath")的结果是一个字典,这是因为一个.mat文件中存在多个变量,每一个变量名都对应相应的数据,也就是变量名和变量值的键值对。
5.2.2 str( )函数:
——能将int类型、float类型的数据转换成字符串类型。
5.2.3. reshape()函数:
——是数组对象中的方法,用于在不更改数据的情况下为数组赋予新形状。
5.2.4. np.float32():
——将输入转换为一个numpy.float32类型的NumPy数组。
5.2.5. range()函数:
Python中的for i in range(range()函数的for循环)如何使用,详细介绍_for in range循环-CSDN博客
5.2.6. np.append(arr, values, axis=None)
参数:
- arr:需要被添加values的数组
- values:添加到数组arr中的值
- axis:可选参数,如果axis没有给出,那么arr,values都将先展平成一维数组。注:如果axis被指定了,那么arr和values需要同为一维数组或者有相同的shape,否则报错:ValueError: arrays must have same number of dimensions
补充对axis的理解:
1. axis的最大值为数组arr的维数-1,如arr维数等于1,axis最大值为0;arr维数等于2,axis最大值为1,以此类推。
2. 当arr的维数为2(理解为单通道图),axis=0表示沿着行增长方向添加values;axis=1表示沿着列增长方向添加values。
3. 当arr的维数为3(理解为多通道图),axis=0,axis=1时同上;axis=2表示沿着图像深度增长方向添加values。
返回:添加了values的新数组。
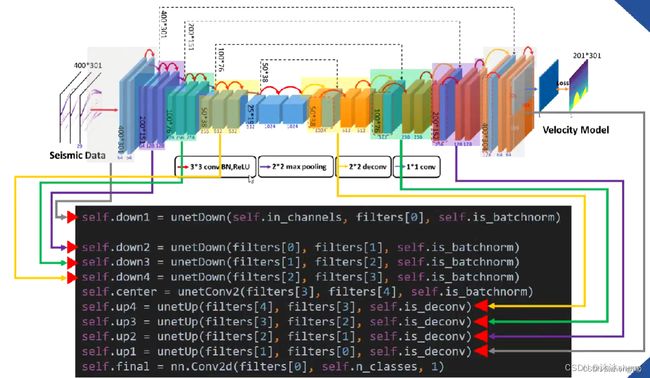
5.3. UnetModel.py
——网络模型名称,设计网络如下:

5.3.1. 卷积块部分unetConv2,中级操作
一些卷积组合(两次红色箭头)被封装为: unetConv2(…)(卷积->BN->RELU->卷积->BN->RELU)。代表三种操作的集合(conv,BN,ReLU),特征图的尺寸并不会发生改变,相当于特征的重整合,为接下来的尺寸变化做准备。
5.3.2. 下采样unetDown,高级操作
表示编码和解码的高级操作被封装为unetDown(…)和unetUp(…),即下采样和上采样,这些操作的组合顺序在图中用不同的色区分割。这两个高级操作是由[两次中级操作]和[一次低级操作如最大池化、反卷积、1*1卷积]
5.3.3. 上采样unetUp,高级操作
5.3.4. UnetModel
5.4. Utls.py
——经常用到的函数、工具等。ssim评价指标;PSNR信噪比
5.4.1. ig, ax = plt.subplots():
用来创建总画布/figure“窗口”的,有figure就可以在上边(或其中一个子网格/subplot上)作图了。
在matplotlib中,有两种画图方式:
- plt.***系列。通过plt.xxx来画图,其实是取了一个捷径。这是通过matplotlib提供的一个api,这个plt提供了很多基本的function可以让你很快的画出图来,但是如果你想要更细致的精调,就要使用另外一种方法。
- fig, ax = plt.subplots():这个就是正统的稍微复杂一点的画图方法了。指定figure和axes,然后对axes单独操作。
Figure:fig = plt.figure(): 可以解释为画布。
axes:理解为你要放到画布上的各个物体。如果你的figure只有一张图,那么你只有一个axes。如果你的figure有subplot,那么每一个subplot就是一个axes。
Axis:ax.xaxis/ax.yaxis: xy坐标轴。 每个坐标轴由竖线和数字组成的,每一个竖线其实也是一个axis的subplot,因此ax.xaxis也存在axes这个对象。对这个axes进行编辑就会修改xaxis图像上的表现。
5.4.2. plt.plot(x,y)函数:
是matplotlib.pyplot模块下的一个函数, 用于画图,它可以绘制点和线, 并且对其样式进行控制。x为x轴数据, y为y轴数据。
5.4.3. gaussian:
圆对称的高斯加权公式 ,标准差为1.5,和为1,来估计局部平均值,标准差,协方差。
不同于MSE, SSIM以窗口的局部特征,在加上高斯核,相当于引入了平滑先验,符合人对视觉的感知。在用MSE作为loss的时候,可以额外加入SSIM,效果会更好。
5.4.4. SSIM:
取值范围[-1, 1], 具有对成性,边界性,唯一最大性(当且仅当x=y时SSIM=1),是一种距离公式。
SSIM 主要考量图片的三个关键特征:亮度(Luminance), 对比度(Contrast), 结构 (Structure)。
当需要衡量一整张图片的质量,经常使用的是以一个一个窗口计算SSIM然后求平均。
当我们用一个一个block去计算平均值,标准差,协方差时,这种方法容易造成 blocking artifacts, 所以在计算MSSIM时,会使用到 circular-symmetric Gaussian weighting function圆对称的高斯加权公式 标准差为1.5,和为1,来估计局部平均值,标准差,协方差。
6. FCNVMB_train.py
——网络训练使用的是tensor数据
在用pytorch训练模型时,通常会在遍历epochs的过程中依次用到三个函数,这三个函数的作用是先将梯度归零(optimizer.zero_grad()),然后反向传播计算得到每个参数的梯度值(loss.backward()),最后通过梯度下降执行一步参数更新(optimizer.step())。
6.1. optimizer = torch.optim.Adam(net.parameters(), lr=LearnRate)
——构造一个优化器对象optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数。
6.2. load_state_dict():
——加载模型参数。用于将预训练的参数权重加载到新的模型之中。
注:stat_dict是一个字典,该字典包含每一层的tensor类型的可学习参数。只有包含可学习参数的网络层才能将其参数映射到state_dict字典中,此外,stat_dict也包含优化器的state和超参数。
6.3. 续行符 \ :
在编码时,每一行的代码数量是有限制的,而很多时候所要表达内容一行并不能完整表达,这时就需要续行符来对不同行的内容进行连接,使其作为完整的一行内容来输出。
6.4. data_utils.TensorDataset():
基于一系列张量构建数据集。这些张量的形状可以不尽相同,但第一个维度必须具有相同大小,这是为了保证在使用 DataLoader 时可以正常地返回一个批量的数据。
6.5. scipy.io.loadmat("FilePath"):
读取路径为"FilePath"的.mat文件,函数返回值为字典类型dict。之后还需要通过后续操作将值提取出来(字典操作来提取键值对的值)。
关于为什么scipy.io.loadmat("FilePath")的结果是一个字典,这是因为一个.mat文件中存在多个变量,每一个变量名都对应相应的数据,也就是变量名和变量值的键值对。
6.6. torch.from_numpy():
将生成的数组(array)转换为张量Tensor,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变。
6.7. PyTorch中的TensorDataset:
——对数据进行封装。
torch.utils.data 中的 TensorDataset 基于一系列张量构建数据集。这些张量的形状可以不尽相同,但第一个维度必须具有相同大小,这是为了保证在使用 DataLoader 时可以正常地返回一个批量的数据。
TensorDataset 可以用来对 tensor 进行打包,就好像 python 中的 zip 功能,将输入的tensors捆绑在一起组成元组。该类通过每一个 tensor 的第一个维度进行索引。因此,该类中的 tensor 第一维度必须相等. 另外:TensorDataset 中的参数必须是 tensor。
注:torch.utils.data.TensorDataset继承父类torch.utils.data.Dataset,不需要对类TensorDataset的函数进行重写。
元组、列表、数组的差别_数组,元组,列表的区别_小手指动起来的博客-CSDN博客
6.8. data_utils.DataLoader():
是PyTorch中加载数据集的核心。DataLoader 返回的是可迭代的数据装载器(DataLoader),使用DataLoader的好处是可以快速的迭代数据。
主要是对数据进行batch的划分,除此之外,特别要注意的是输入进函数的数据一定得是可迭代的。如果是自定的数据集的话可以在定义类中用def__len__、def__getitem__定义。
torch.utils.data.DataLoader参数:
- dataset (Dataset) – 加载数据的数据集。
- batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
- shuffle (bool, optional) – 设置为
True时会在每个epoch重新打乱数据(默认: False)。
6.9. time.time():
——返回当前时间的时间戳。
6.10. enumerate(trainloader, 0):
用于可迭代、可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标。上面代码的0表示,索引从0开始,假如为1的话,那索引就从1开始。
6.11. PyTorch: view( ):
pytorch中的view( )函数相当于numpy中的resize( )函数,都是用来重构(或者调整)张量维度的。
6.12. pytorch中的MSELoss函数:
均方误差(mean square error, MSE),是反应估计量与被估计量之间差异程度的一种度量,设t是根据子样确定的总体参数θ 的一个估计量,![]() 的数学期望,称为估计量t的均方误差。
的数学期望,称为估计量t的均方误差。
常用于回归问题的损失函数,它计算预测输出和实际输出之间的均方误差,即预测值与实际值之差的平方的平均值。MSE Loss对于数据的高斯分布假设较为合理,适用于预测连续变量的任务。
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
参数解释:
- size_average(可选,默认为 None):这是一个布尔值或整数,用于指定是否对所有输入批次的输出进行平均。如果设置为 True,则对所有输入批次的输出进行平均。如果设置为整数 n,则对前 n 个输入批次的输出进行平均。如果设置为 None,则根据 reduce 参数的值决定是否进行平均。
- reduce(可选,默认为 None):这是一个布尔值,用于指定是否对输入批次的输出进行减少。如果设置为 True,则对输入批次的输出进行减少,返回一个标量。如果设置为 False,则返回每个输入批次的输出的张量。如果 size_average 和 reduce 都为 None,则根据 reduction 参数的值决定是否进行减少和平均。
- reduction(可选,默认为 ‘mean’):这是一个字符串,用于指定如何对输入批次的输出进行减少。可选的值有 ‘mean’、‘sum’ 和 ‘none’。如果设置为 ‘mean’,则对输入批次的输出进行平均。如果设置为 ‘sum’,则对输入批次的输出求和。如果设置为 ‘none’,则不进行减少,返回每个输入批次的输出的张量。
补充:在pytorch深度学习中,损失函数(Loss Function)是一个用于计算模型预测输出和实际输出之间的误差的函数。它用于衡量模型的性能,并通过反向传播算法更新模型的权重和参数,以减小预测输出和实际输出之间的误差。损失函数loss定义了模型优劣的标准,loss越小,模型越好。
6.13. .item()的用法
用于在只包含一个元素的tensor中提取值,否则的话使用.tolist()。即item()的作用是取出单元素张量的元素值并返回该值,保持该元素类型不变。
使用item()函数取出的元素值的精度更高,所以在求损失函数等时我们一般用item()。
在训练时统计loss变化时,会用到loss.item(),能够防止tensor无线叠加导致的显存爆炸。
6.14. numpy.isnan()函数
用于判断一个数组中的元素是否为NaN(not a number)。NaN是一个特殊的浮点数,用于表示不可能的数值,例如0/0、∞/∞等。
6.15. loss.backward():
将损失loss 向输入侧进行反向传播,同时对于需要进行梯度计算的所有变量x (requires_grad=True),计算梯度![]() ,并将其累积到梯度x.grad中备用,即:
,并将其累积到梯度x.grad中备用,即: ![]()
6.16. format():
用于格式化方法,即用来控制字符串和变量的显示效果。 在没有参数序号时,参数是按顺序使用的。可以通过format()参数的序号指定参数的使用,参数从0开始编号
6.17. 训练情况分析:
- TrainSize10_Epoch20_BatchSize5_LRO.001_epoch20.——预测图全紫,不显示。效果不合格。
- TrainSize20_Epoch20_BatchSize5_LRO.001_epoch20.——能显示,效果不好
- TrainSize30_Epoch20_BatchSize5_LRO.001_epoch20.——能显示,效果不好
- 工作站上进行,效果ok
需要大量训练数据。
7. FCNVMB_test
7.1. np.zeros函数的作用:
zeros(shape, dtype=float, order='C')
初始化一个矩阵,返回来一个给定形状和类型的用0填充的数组;
7.2. model.eval( ) :
不启用 BatchNormalization 和 Dropout。
神经网络模块存在两种模式,train模式(net.train())和eval模式(net.eval())。一般的神经网络中,这两种模式是一样的,只有当模型中存在dropout和batchnorm的时候才有区别。
一旦我们用测试集进行结果测试的时候,一定要使用net.eval()把dropout关掉,因为这里我们的目的是测试训练好的网络,而不是在训练网络,没有必要再dropout和再计算BN的方差和均值(BN使用训练的历史值)。
训练完train_datasets之后,model要来测试样本了。在model(test_datasets)之前,需要加上model.eval(). 否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有batch normalization层所带来的的性质。
eval()时,pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大。eval()在非训练的时候是需要加的,没有这句代码,一些网络层的值会发生变动,不会固定,你神经网络每一次生成的结果也是不固定的,生成质量可能好也可能不好。
7.3. Variable:
是一种可以不断变化的变量,符合反向传播,参数更新的属性。pytorch的variable是一个存放会变化值的地理位置,里面的值会不停变化
8. 出现的问题:
1. UserWarning: size_average and reduce args will be deprecated, please use reduction='mean' instead. warnings.warn(warning.format(ret))
2.