用通俗易懂的方式讲解:Stable Diffusion WebUI 从零基础到入门
本文主要介绍 Stable Diffusion WebUI 的实际操作方法,涵盖prompt推导、lora模型、vae模型和controlNet应用等内容,并给出了可操作的文生图、图生图实战示例。适合对Stable Diffusion感兴趣,但又对Stable Diffusion WebUI使用感到困惑的同学。
前面分享了两篇文章:十分钟读懂 Stable Diffusion 运行原理 和 一文教会你学会 AI 绘画利器 Stable Diffusion,喜欢的可以阅读一下
本文希望能够降低大家对 Stable Diffusion WebUI 的学习成本,更快速的体验到AIGC图像生成的魅力。喜欢记得收藏、关注、点赞。
文章目录
-
- 用通俗易懂的方式讲解系列
- 引言
-
-
- 安装
- 模型
-
- 操作流程
-
-
- prompt推导
- lora模型
- ControlNet
- 图生图示例
- 文生图示例
- 示例1
- 示例2
- 提示词解析
- VAE
- 模型的安装
- 效果
-
- 结束语
用通俗易懂的方式讲解系列
- 用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
- 用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
- 用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
- 用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
- 用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
- 用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调)
- 用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
- 用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
- 用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
- 用通俗易懂的方式讲解:大模型训练过程概述
- 用通俗易懂的方式讲解:专补大模型短板的RAG
- 用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
- 用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
- 用通俗易懂的方式讲解:大模型微调方法总结
- 用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
引言
Stable Diffusion (简称sd)是一个深度学习的文本到图像生成模型, Stable Diffusion WebUI是对Stable Diffusion模型进行封装,提供可操作界面的工具软件。Stable Diffusion WebUI上加载的模型,是在Stable Diffusion 基座模型基础上,为了获得在某种风格上的更高质量的生成效果,而进行再次训练后产生的模型。目前 Stable Diffusion 1.5版本是社区内最盛行的基座模型。
安装
sd web-ui的安装请参考:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs
sd web-ui使用了gradio组件包,gradio在配置share=True时,会创建frpc隧道并链接到aws,详情可参考(https://www.gradio.app/guides/sharing-your-app),因此在sd web-ui应用启动时,请根据自身安全生产或隐私保护要求,考虑是否禁止开启share=True配置,或删除frpc客户端。
模型
https://civitai.com/是一个开源的sd模型社区,提供了丰富的模型免费下载和使用。在此简述一下模型的分类,有助于提高对sd web-ui的使用。sd模型训练方法主要分为四类:Dreambooth, LoRA,Textual Inversion,Hypernetwork。
-
Dreambooth:在sd基座模型的基础上,通过 Dreambooth 训练方式得到的大模型, 是一个完整的新模型,训练速度较慢,生成模型文件较大,一般几个G,模型文件格式为 safetensors 或 ckpt。特点是出图效果好,在某些艺术风格上有明显的提升。如下图所示,sd web-ui中该类模型可以在这里进行选择。
-
LoRA: 一种轻量化的模型微调训练方法,在原有大模型的基础上对该模型进行微调,用于输出固定特征的人或事物。特点是对于特定风格的图产出效果好,训练速度快,模型文件小,一般几十到一百多 MB,不能独立使用,需要搭配原有大模型一起使用。sd web-ui提供了lora模型插件,以及使用lora模型的方式,具体操作可见本文的 “操作流程->lora模型” 。
-
Textual Inversion:一种使用文本提示和对应的风格图片来微调训练模型的方法,文本提示一般为特殊的单词,模型训练完成后,可以在text prompts中使用这些单词,来实现对模型生成图片风格和细节的控制,需要搭配原有的大模型一起使用。
-
Hypernetwork:与LoRA类似的微调训练大模型的方法,需要搭配原有的大模型一起使用。
操作流程
prompt推导
-
在sd中上传一张图片
-
反向推导关键词,有两个模型CLIP和DeepBooru,以图1为例:

图1: iphone 14 pro max 原相机拍摄的高清照片
使用CLIP进行prompt反推的结果:
a baby is laying on a blanket surrounded by balloons and balls in the air and a cake with a name on it, Bian Jingzhao, phuoc quan, a colorized photo, dada
使用DeepBooru进行prompt反推的结果:
1boy, ball, balloon, bubble_blowing, chewing_gum, hat, holding_balloon, male_focus, military, military_uniform, open_mouth, orb, solo, uniform, yin_yang
CLIP反推结果是一个句子,DeepBooru的反推结果是关键词。
可以修改正向prompt,也可以添加反向prompt,反向prompt用于限制模型在生产图片时不添加反向prompt中出现的元素。反向prompt不是必须的,可以不填。
lora模型
lora模型对大模型生成图的风格和质量有很强的干预或增强作用,但是lora模型需要与配套的大模型一起使用,不能单独使用。在sd-webui中使用lora模型的方式主要有两种:
- 方法一
安装additional-network插件,插件的github地址:https://github.com/kohya-ss/sd-webui-additional-networks,在sd-webui上可以在扩展中直接下载安装。该插件仅支持使用sd-script脚本训练的lora模型,目前https://civitai.com/上绝大多数的开源lora模型都是基于此脚本训练的,因此该插件支持绝大多数的lora模型。下载的lora模型需要放到
*/stable-diffusion-webui/extensions/sd-webui-additional-networks/models/lora
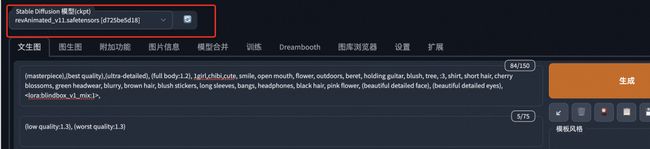
路径下, 新增模型需要重启sd-webui,插件和模型正确加载后,会在webui操作界面的左下角中出现“可选附加网络(LoRA插件)” 。在生成图片时触发lora,需要在插件中选中lora模型,并在正向提示词中加入Trigger Words。下图中选中的lora模型为blinndbox_v1_mix, trigger words为full body,chibi, 每个lora模型有自己独有的Trigger Words,在模型的简介中会注明。
如果插件在点击安装后没有反应,或者提示因为Flag引起的错误,是因为webui启动时允许扩展插件的设置配置为禁止,需要在webui启动时添加启动参数:–enable-insecure-extension-access
./webui.sh --xformers --enable-insecure-extension-access
- 方法二
不使用additional-network插件,使用sd-webui默认支持的lora模型使用方式,需要将lora模型放到
*/stable-diffusion-webui/models/Lora
目录下,重新启动sd-webui即可自动载入模型。
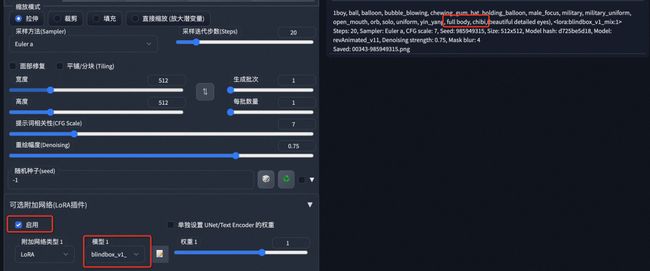
在正向提示词中加入lora模型启用语句,生产图片时即可触发lora模型:

web-ui提供了自动填充lora提示语句的功能,点击如图所示的图标,可以打开lora模型列表,然后点击模型区域,语句会自动填充到正向提示词区域:
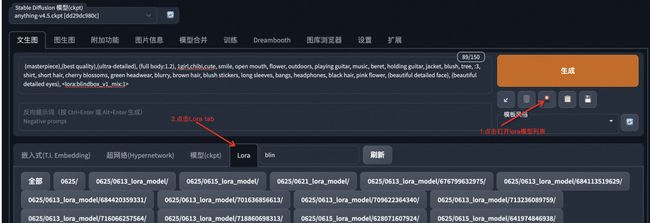
以上两种方式,选用其中任意一种均能使lora模型在内容生产中生效,两种方式同时使用也不会引起问题。
ControlNet
controlNet通过支持额外的输入条件,试图控制预训练的大模型,如Stable Diffusion。单纯的文本控制方式令内容的生产就像碰运气抽卡,结果无法控制且不容易达到预期效果,controlNet的出现使stable diffusion大模型的内容生成进入可控时期,让创作变得可控使得AIGC在工业应用上更进一步。
- 安装controlNet
在sd-webui上,点击扩展,进入插件安装页面,找到controlNet插件,点击install即可完成插件安装。

下载开源的controlnet模型
下载地址:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
一个模型由两个文件组成: .pth 和 .yaml,需要同时下载。文件名中"V11"后面的字母,p:表示可以使用,e:表示还在试验中,u:表示未完成。下载好的模型放在如下目录,重启sd-webui 即可完成controlnet模型加载。
*\stable-diffusion-webui\extensions\sd-webui-controlnet\models
图生图示例
- 模型选择
1、stable diffusion大模型选用:revAnimated_v11 (https://civitai.com/models/7371?modelVersionId=46846)
2、lora模型选用blind_box_v1_mix (https://civitai.com/models/25995?modelVersionId=32988)
3、采样方法Euler a
4、源图片使用 图1,使用DeepBooru模型进行正向prompts生成, 添加revAnimated_v11的特定prompts, 删除一些正向prompts,添加反向prompts,最后使用的prompt如下所示。
正向:
(masterpiece),(best quality), (full body:1.2), (beautiful detailed eyes), 1boy, hat, male, open_mouth, smile, cloud, solo, full body, chibi, military_uniform, lora:blindbox\_v1\_mix:1
反向:
(low quality:1.3), (worst quality:1.3)
生成的图片为:

图1:原图片

图2:sd生成图片
5、保持生成图片的条件不变,添加ControlNet模型,选择Openpose,control mode选择 balance ,生成的图片如下所示,生成的人物动作因为Openpose的作用被约束了,与原图像保持的更为相似。

图3:sd生成图片(添加openpose)
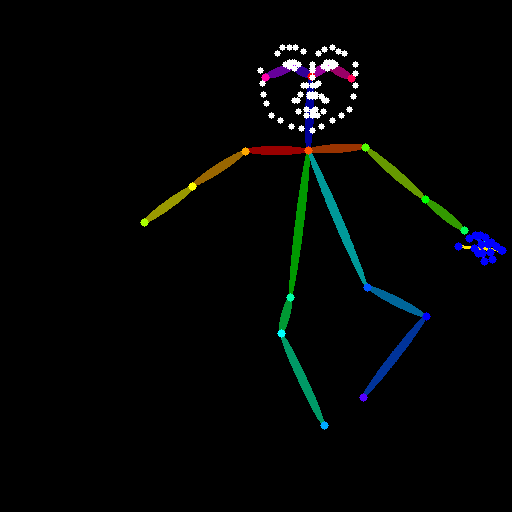
图4: openpose生成的图片
文生图示例
- 模型选择
-
stable diffusion大模型选用:revAnimated_v11 (https://civitai.com/models/7371?modelVersionId=46846)
-
lora模型选用blind_box_v1_mix (https://civitai.com/models/25995?modelVersionId=32988)
-
采样方法Euler a
示例1
提示词
正向:
(masterpiece),(best quality),(ultra-detailed), (full body:1.2), 1girl, youth, dynamic, smile, palace,tang dynasty, shirt, long hair, blurry, black hair, blush stickers, black hair, (beautiful detailed face), (beautiful detailed eyes), lora:blindbox\_v1\_mix:1, full body, chibi
反向:
(low quality:1.3), (worst quality:1.3)
生成的图片为:

图5: 文生图实例1
示例2
提示词
正向:
(masterpiece),(best quality),(ultra-detailed), (full body:1.2), 1girl,chibi,sex, smile, open mouth, flower, outdoors, beret, jk, blush, tree, :3, shirt, short hair, cherry blossoms, blurry, brown hair, blush stickers, long sleeves, bangs, black hair, pink flower, (beautiful detailed face), (beautiful detailed eyes), lora:blindbox\_v1\_mix:1,
反向:
(low quality:1.3), (worst quality:1.3)
生成图片为:

图6: 文生图实例2
提示词解析
-
(masterpiece),(best quality),(ultra-detailed), (full body:1.2), (beautiful detailed face), (beautiful detailed eyes) 这些带()的词为revAnimated_v11 模型配套prompts,用于提高图片的生成质量。
-
lora:blindbox\_v1\_mix:1 是触发 blind_box_v1_mix 模型的 prompt。
-
full body, chibi 为 blind_box_v1_mix 模型的 trigger words。
-
剩下的prompts为图片内容的描述。
-
revAnimated_v11 模型对prompt的顺序是敏感的,排在前面的提示词比排在后面的prompt对结果的影响更大。
VAE
在sd的实际使用中,vae模型起到滤镜和微调的作用,有些sd模型是自带vae的,并不需要单独挂载vae。与模型配套的vae的模型,通常会在模型的发布页面会附带vae的下载链接。
-
模型的安装
下载vae模型到sd web-ui的如下目录,重启sd web-ui,即可自动完成vae模型加载。
/stable-diffusion-webui/models/VAE
如下图所示,在sd web-ui上可以切换vae模型。

如果we-ui上看不到此选择框,则到设置-> 用户界面-> 快捷设置列表 添加配置 “sd_vae”,如下所示:

-
效果
在保持图6生成条件不变的基础上,附加Blessed2(https://huggingface.co/NoCrypt/blessed_vae/blob/main/blessed2.vae.pt)模型,图片的颜色和对比度有了明显的变化。

图7: 添加vae模型前

图8:添加vae模型后图片的饱和度和对比度都有提升
结束语
-
sd web-ui的学习曲线比较陡峭,具有一定的图像处理领域知识能够帮助用户更好的选择和组合模型。
-
零基础小白用户容易出现随便选择模型,胡乱组合,对着sd web-ui界面进行一系列操作后,出图效果和预期完全不符的情况,建议先了解每个模型的特点后再根据实际目标进行选择。
-
sd是开源的,sd web-ui是一个工具箱,不是一个商业产品,社区中有很多效果很棒的模型,出图的上限很高,但下限也很低,开源不代表没有成本,因为sd we-ui部署要求较高的硬件配置。要节省学习成本,较为稳定的出图效果,简单便捷的用户体验,没有硬件配置要求,midjourney 是当前的首选,但需要支付订阅费。