【计算机组成与体系结构Ⅱ】指令调度与分支延迟(实验)
实验4:指令调度与分支延迟
一、实验目的
1. 加深对指令调度技术的理解。
2. 加深对分支延迟技术的理解。
3. 熟练采用指令调度技术解决流水线中的数据冲突的方法。
4. 进一步理解指令调度技术对CPU性能的改进。
5. 进一步理解延迟分支技术对CPU性能的改进。
二、实验平台
实验平台采用指令级和流水线操作级模拟器MIPSsim。
三、实验内容和步骤
1. 启动MIPSsim。
2. 根据实验3的相关知识中关于流水线各段操作的描述,进一步理解流水线窗口中各段的功能,掌握各流水线寄存器的含义(双击各段,就可以看到各流水线寄存器中的内容)。
3. 选择“配置”→“流水方式”选项,使模拟器工作在流水方式下。
4. 用指令调度技术解决流水线中的结构冲突与数据冲突:
1)启动MIPSsim。
2)用MIPSsim的“文件”→“载入程序”选项来加载schedule.s(在模拟器所在文件夹下的“样例程序”文件夹中)。
3)关闭定向功能,这是通过“配置”→“定向”选项来实现的。
4)执行所载入的程序,通过查看统计数据和时钟周期图,找出并记录程序执行过程中各种冲突发生的次数,发生冲突的指令组合以及程序执行的总时钟周期数。
5)自己采用调度技术对程序进行指令调度,消除冲突(自己修改源程序)。将调度(修改)后的程序重新命名为my-schedule.s。
6)载入my-schedule.s,执行该程序,观察程序在流水线中的执行情况,记录程序执行的总时钟周期数。
7)比较调度前和调度后的性能,论述指令调度对提高CPU性能的作用。
5. 用延迟分支技术减少分支指令对性能的影响:
1)在MIPSsim中载入branch.s样例程序(模拟器目录的“样例程序”文件夹中)。
2)关闭延迟分支功能。这是通过在“配置”→“延迟槽”选项来实现的。
3)执行程序,观察并记录发生分支延迟的时刻,记录该程序执行的总时钟周期数。
4)假设延迟槽为一个,自己对branch.s程序进行指令调度(自己修改源程序),将调度后的程序重新命名为my-branch.s。
6. 使用MIPS指令实现求两个数组的点积:
1)执行样例程序array.s,该程序的功能为实现求两个n维向量A、B的点积。
2)载入程序(array.s),观察流水线输出结果。

3)使用定向功能再次执行代码,与各个执行结果进行比较,观察执行效率的不同。
4)采用静态调度方法重排指令序列,减少相关,优化程序,分析执行结果和效率。
5)利用分支延迟,分析流水线的性能。
四、实验结果和分析
1:用指令调度技术解决流水线中的结构冲突与数据冲突(schedule.s)
(1)关闭定向功能。
(2)执行schedule.s程序,查看统计数据和时钟周期图,找出并记录程序执行过程中各种冲突发生的次数,发生冲突的指令组合以及程序执行的总时钟周期数。
【未修改的schedule.s程序代码】
| .text main: ADDIU $r1,$r0,A LW $r2,0($r1) ADD $r4,$r0,$r2 SW $r4,0($r1) LW $r6,4($r1) ADD $r8,$r6,$r1 MUL $r12,$r10,$r1 ADD $r16,$r12,$r1 ADD $r18,$r16,$r1 SW $r18,16($r1) LW $r20,8($r1) MUL $r22,$r20,$r14 MUL $r24,$r26,$r14 TEQ $r0,$r0 .data A: .word 4,6,8 |
【统计数据】

【时钟周期图】
周期0~周期17:

周期18~周期32:

【程序执行过程中各种冲突发生的次数】 8次
【发生冲突的指令组合】
| 冲突指令1(原因) |
冲突指令2(结果) |
导致冲突发生的原因 |
| ADDIU $r1,$r0,A |
LW $r2,0($r1) |
Read after write数据相关 |
| LW $r2,0($r1) |
ADD $r4,$r0,$r2 |
Read after write数据相关 |
| ADD $r4,$r0,$r2 |
SW $r4,0($r1) |
Read after write数据相关 |
| LW $r6,4($r1) |
ADD $r8,$r6,$r1 |
Read after write数据相关 |
| MUL $r12,$r10,$r1 |
ADD $r16,$r12,$r1 |
Read after write数据相关 |
| ADD $r16,$r12,$r1 |
ADD $r18,$r16,$r1 |
Read after write数据相关 |
| ADD $r18,$r16,$r1 |
SW $r18,16($r1) |
Read after write数据相关 |
| LW $r20,8($r1) |
MUL $r22,$r20,$r14 |
Read after write数据相关 |
【程序执行的总时钟周期数】33个
【程序停顿周期总数】17次
(3)自己采用调度技术对程序进行指令调度,消除冲突(自己修改源程序)。将调度(修改)后的程序重新命名为my-schedule.s。
【修改后的my-schedule.s程序代码(含注释部分)】
| .text main: ADDIU $r1,$r0,A MUL $r24,$r26,$r14 LW $r2,0($r1) MUL $r12,$r10,$r1 LW $r20,8($r1) LW $r6,4($r1) ADD $r16,$r12,$r1 ADD $r4,$r0,$r2 ADD $r8,$r6,$r1 ADD $r18,$r16,$r1 SW $r4,0($r1) MUL $r22,$r20,$r14 SW $r18,16($r1) TEQ $r0,$r0 .data A: .word 4,6,8 |
代码段开始 main代码起始 A + $r0 -> $r1 $r26 * $r14 -> $r24 [$r1 + 0] -> $r2 $r10 * $r1 -> $r12 [$r1 + 8] -> $r20 [$r1 + 4] -> $r6 $r12 + $r1 -> $r16 $r0 + $r2 -> $r4 $r6 + $r1 -> $r8 $r16 + $r1 -> $r18 $r4 -> [$r1 + 0] $r20 * $r14 -> $r22 $r18 -> [$r1 + 16] 程序结束 数据段开始 标签A定义 A标签后定义三个整数值:4, 6 和 8 |
【统计数据】

【时钟周期图】
周期0~周期17:

【程序执行过程中各种冲突发生的次数】1次
【发生冲突的指令组合】
| 冲突指令1(原因) |
冲突指令2(结果) |
导致冲突发生的原因 |
| ADDIU $r1,$r0,A |
LW $r2,0($r1) |
Read after write数据相关 |
【程序执行的总时钟周期数】18个
【程序停顿周期总数】2次
(4)比较调度前和调度后的性能,论述指令调度对提高CPU性能的作用。
【调度前和调度后的代码对比】

在调度前的代码中,多处位置出现RAW冲突,因此需要通过调换指令的顺序来解决数据相关。首先分析调度前完全没有读写依赖的指令,发现有【MUL $r24,$r26,$r14】乘法指令,因此将其移到【ADDIU $r1,$r0,A】指令的后面一条位置处。
分析后发现后续指令都直接或间接依赖与$r1的值,因此必须有一条指令需要气泡stall,在本实验中我们选择【LW $r2,0($r1)】。
紧接着,优先把有RAW冲突的原因指令都放在前面,利用没有数据冲突的其他RAW冲突的原因指令进行2个时钟周期的填充,再把有对应的RAW冲突的结果指令放在2条指令后的位置。例如下图中的指令,围绕$r12来看,可以先把需要写$r12的指令MUL放在第一个,然后插入两个没有数据相关的指令LW,最后把需要读$r12的指令ADD放在第四个。

【指令调度对提高CPU性能的作用】
指令调度的目的就是通过重排指令(即合理安排指令的执行顺序)来提高指令级的并行性,使得程序在拥有指令流水线的CPU上更高效的运行。在多线程或者多任务环境下,不同的指令可能会访问同一内存地址,导致数据冲突。通过指令调度,可以将这些冲突的指令分开执行,从而避免数据冲突。
例如在本实验中,存在较多的RAW数据冲突。通过指令调度工作后,程序的执行周期从33个减少至18个,大大降低了指令stall的周期数,提高了CPU的工作效率。
2:用延迟分支技术减少分支指令对性能的影响(branch.s)
(1)关闭延迟分支功能。

(2)执行程序,观察并记录发生分支延迟的时刻,记录该程序执行的总时钟周期数。
【未修改的branch.s程序代码】
| .text main: ADDI $r2,$r0,1024 ADD $r3,$r0,$r0 ADDI $r4,$r0,8 loop: LW $r1,0($r2) ADDI $r1,$r1,1 SW $r1,0($r2) ADDI $r3,$r3,4 SUB $r5,$r4,$r3 BGTZ $r5,loop ADD $r7,$r0,$r6 TEQ $r0,$r0 |
【统计数据】

【时钟周期图】
周期0~周期17:

周期18~周期35:

周期36~周期37:
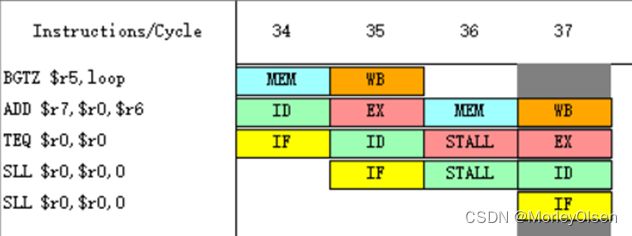
【程序执行过程中分支指令的控制停顿次数】2次
第一次分支指令执行:

第二次分支指令执行:

【发生冲突的指令组合】
| 冲突指令1(原因) |
冲突指令2(结果) |
导致冲突发生的原因 |
| ADDI $r1,$r1,1 |
SW $r1,0($r2) |
Read after write数据相关 |
| ADDI $r3,$r3,4 |
SUB $r5,$r4,$r3 |
Read after write数据相关 |
| SUB $r5,$r4,$r3 |
BGTZ $r5,loop |
Read after write数据相关 |
【程序执行的总时钟周期数】38个
【程序停顿周期总数】19次
(3)假设延迟槽为一个,自己对branch.s程序进行指令调度(自己修改源程序),将调度后的程序重新命名为my-branch.s。
【修改后的my-branch.s程序代码(含注释部分)】
| .text main: ADDI $r2,$r0,1024 ADD $r3,$r0,$r0 ADDI $r4,$r0,8 loop: ADDI $r3,$r3,4 LW $r1,0($r2) SUB $r5,$r4,$r3 ADDI $r1,$r1,1 BGTZ $r5,loop SW $r1,0($r2) ADD $r7,$r0,$r6 TEQ $r0,$r0 |
代码段开始 main代码段开始 $r0 + 1024 -> $r2 $r0 + $r0 -> $r3 $r0 + 8 -> $r4 loop代码段开始 $r3 + 4 -> r3 [$r2 + 0] -> $r1 $r4 - $r3 -> $r5 $r1 + 1 -> $r1 If $r5 > 0, jump to loop $r1 -> [$r2 + 0] $r0 + $r6 -> $r7 程序结束 |
【延迟槽设置】

【统计数据】

【时钟周期图】
周期0~周期17:

周期18~周期24:

【程序执行过程中分支指令的执行次数】2次
第一次分支指令执行:

第二次分支指令执行:

【程序执行的总时钟周期数】25个
【程序停顿周期总数】6次
(4)比较调度前和调度后以及是否开延迟槽的结果。
【调度前和调度后的代码对比】

已知延迟槽 = 1的情况下,我们将SW指令放入延迟槽中,且将涉及数据相关的指令进行重新排序调整。在这种情况下,执行时钟周期总数从38压缩到25。
【branch.s是否开延迟槽的对比】
在延迟槽 = 1的情况下,统计数据的结果如下图所示。在这种情况下,执行时钟周期总数从38压缩到37,即由于提前存入分支失败的下一条指令,因此会少1个时钟周期。

3:使用MIPS指令实现求两个数组的点积(array.s)
(1)载入程序(array.s),观察流水线输出结果。
【未修改的array.s程序代码】
| .text main: ADDIU $r1,$r0,array1 ADDIU $r2,$r0,array2 ADDIU $r3,$r0,10 #数组容量为10 ADDIU $r10,$r0,0 #r10保存最终结果,初始化为0 loop: LW $r4,0($r1) #对应位取数 LW $r5,0($r2) MUL $r6,$r4,$r5 #取出的数相乘 ADD $r10,$r10,$r6 #存入r10 ADDI $r1,$r1,4 #地址加,变为下一个数(word)地址 ADDI $r2,$r2,4 ADDI $r3,$r3,-1 #计数器r3减一 BGTZ $r3,loop #计数器r3仍大于零则跳转,说明数组没到末尾 TEQ $r0,$r0 .data array1: .word 0,1,2,0,1,2,3,0,1,2 array2: .word 0,1,2,0,1,2,3,0,1,2 |
【统计数据】

【程序执行的总时钟周期数】157个
【程序停顿周期总数】70次
(2)使用定向功能再次执行代码,与各个执行结果进行比较,观察执行效率的不同。
【开启定向】

【统计数据】

【程序执行的总时钟周期数】117个
【程序停顿周期总数】30次
(3)采用静态调度方法重排指令序列,减少相关,优化程序,分析执行结果和效率。
【修改后的my-array.s程序代码】
| .text main: ADDIU $r1,$r0,array1 ADDIU $r2,$r0,array2 ADDIU $r3,$r0,10 #数组容量为10 ADDIU $r10,$r0,0 #r10保存最终结果,初始化为0 loop: LW $r4,0($r1) #对应位取数 LW $r5,0($r2) ADDI $r3,$r3,-1 #计数器r3减一 MUL $r6,$r4,$r5 #取出的数相乘 ADDI $r1,$r1,4 #地址加,变为下一个数(word)地址 ADDI $r2,$r2,4 ADD $r10,$r10,$r6 #存入r10 BGTZ $r3,loop #计数器r3仍大于零则跳转,说明数组没到末尾 TEQ $r0,$r0 .data array1: .word 0,1,2,0,1,2,3,0,1,2 array2: .word 0,1,2,0,1,2,3,0,1,2 |
【不开启定向的统计数据】

【程序执行的总时钟周期数】107个
【程序停顿周期总数】20次
【开启定向的统计数据】

【程序执行的总时钟周期数】97个
【程序停顿周期总数】10次
【分析执行结果和效率】
在采用指令调度的情况下,不采用定向技术可以将程序执行的总时钟周期数从157个缩小至107个,采用定向技术可以将程序执行的总时钟周期数从157个缩小至97个,大大提高了CPU的执行效率。
定向技术利用部件内部间的旁路通路,减少了写后读(RAW)数据冲突引起的停顿。在计算结果尚未出来之前,后面等待使用该结果的指令并不一定立即需要该计算结果,如果能够将该计算结果从其产生的地方直接送到其它指令需要它的地方,那么就可以避免停顿。结果数据不仅可以从某一功能部件的输出定向到其自身的输入,而且还可以定向到其它功能部件的输入。
定向技术的实现原理是:(1)EX段和MEM段之间的流水寄存器中保存的ALU运算结果总是回送到ALU的入口。(2)当定向硬件检测到前一个ALU运算结果写入的寄存器就是当前ALU操作的源寄存器时,那么控制逻辑就选择定向的数据作为ALU的输入,而不采用从通用寄存器组读出的数据。
(4)利用分支延迟,分析流水线的性能。
【修改后的branch-array.s程序代码】
| .text main: ADDIU $r1,$r0,array1 ADDIU $r2,$r0,array2 ADDIU $r3,$r0,10 #数组容量为10 ADDIU $r10,$r0,0 #r10保存最终结果,初始化为0 LW $r5,0($r2) #loop1延迟槽不能执行,所以提前到前面 loop: LW $r4,0($r1) #对应位取数 ADDI $r3,$r3,-1 #计数器r3减一 MUL $r6,$r4,$r5 #取出的数相乘 ADDI $r1,$r1,4 #地址加,变为下一个数(word)地址 ADDI $r2,$r2,4 ADD $r10,$r10,$r6 #存入r10 BGTZ $r3,loop #计数器r3仍大于零则跳转,说明数组没到末尾 LW $r5,0($r2) #延迟槽一定执行该指令,同时缓解了r5的RAW冲突 TEQ $r0,$r0 .data array1: .word 0,1,2,0,1,2,3,0,1,2 array2: .word 0,1,2,0,1,2,3,0,1,2 |
【开启延迟槽】
【统计数据】

【程序执行的总时钟周期数】99个
【程序停顿周期总数】11次
【时钟周期图】
周期0~周期22:
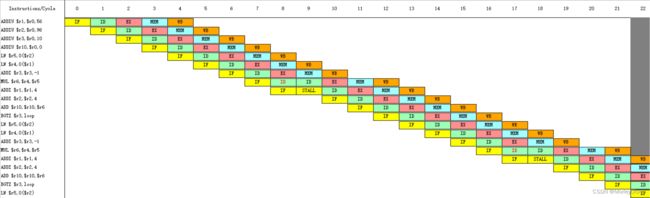
周期23~周期45:

周期46~周期68:

周期69~周期91:

周期92~周期98:
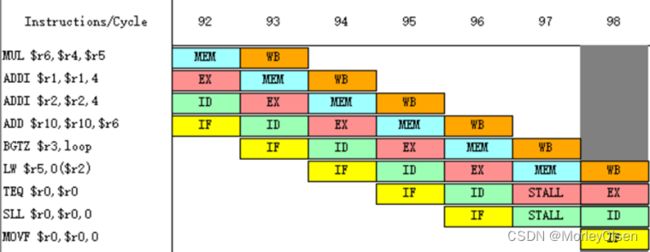
【开启延迟槽并开启定向】

【统计数据】

【程序执行的总时钟周期数】89个
【程序停顿周期总数】1次
【对比是否采用定向】可以发现由于RAW产生的停顿,在开启定向技术后均消失,程序停顿周期现在只因为自陷指令引起。
【时钟周期图】
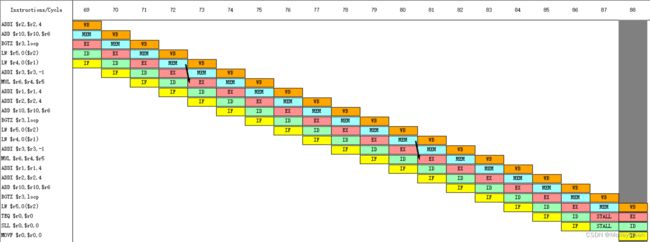
周期0~周期22:可以发现$r4的数据直接通过LW指令的MEM阶段送入MUL指令的EX阶段,不需要等待LW指令的WB阶段完成。

周期23~周期45:同理,都是LW指令利用定向技术将数据送入MUL指令。

周期46~周期68:同理,都是LW指令利用定向技术将数据送入MUL指令。

周期69~周期88:同理,都是LW指令利用定向技术将数据送入MUL指令。
五、实验总结
1:流水线上的相关性主要有数据相关、结构相关、控制相关,分别对应数据使用时间、资源、指令流向。相关性产生的影响包括(1)导致错误的执行结果;(2)流水线会出现停顿,降低流水线的效率和实际的加速比。
2:在指令优化问题中,基于软件的静态开发方法有:指令调度、循环展开。针对数据相关问题,通常采用指令调度进行解决。
3:在控制相关问题方面,基于编译器的软件改进通常采用延迟分支。分支延迟槽存放的内容是分支指令后的一条指令,不管分支是否成功,都要按顺序执行延迟槽中的指令。分支延迟技术能够在一定程度上提高循环的效率,但对于循环次数较少的情况效果有限。
4:使用定向技术(旁路通路)后,程序的执行所用时钟周期和停顿次数均降低,使执行效率大大提高。所有的定向都是从ALU/DM的输出到ALU、DM或0检测单元的输入。
5:分支延迟槽是把位于分支指令后面的一条指令放入延迟槽中,且不论分支是否成功都对该指令进行译码等阶段的工作。这种利用延迟槽的分支延迟技术能够在循环中提高一定的性能,但是循环次数少的提高并不多。
5:通过本次实验,深入理解了指令调度、定向技术、分支延迟的相关内容。