线性回归实战
一、引言
大家在看这篇文章的时候可能会云里雾里,或许你忘记了前面讲述的知识(就是我),或许你对Python的语法不熟悉(就是我),但是没关系,忘记的知识复习下就好了,Python语法不熟悉就看看网课,有些函数不认识百度一下、CSDN一下就知道了,我也会尽力在代码中解释清楚,一步一步给出处理结果,所以大家慢慢学,别着急,加油~
二、题目
假设你是一家餐馆的首席执行官,正在选择一个城市开设一个新的分店,而且你有各个城市的利润和人口数据,你希望使用这些数据来帮助你做出选择。在本部分的练习中,你将使用线性回归算法以根据城市人口数量来预测带来的利润。
三、单变量线性回归
导入依赖
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
读取数据并查看具体信息
数据集获取:dataSet
提取码:6666
path = 'ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])print(data.head()) # 预览数据,默认显示5行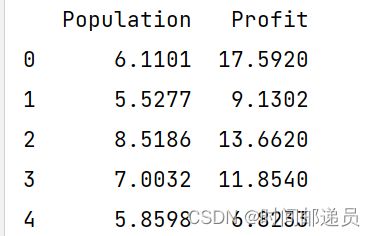
print(data.describe()) # 生成描述性统计信息,包括:计数、均值、标准差、最小值、25%分位数、中位数(50%分位数)、75%分位数和最大值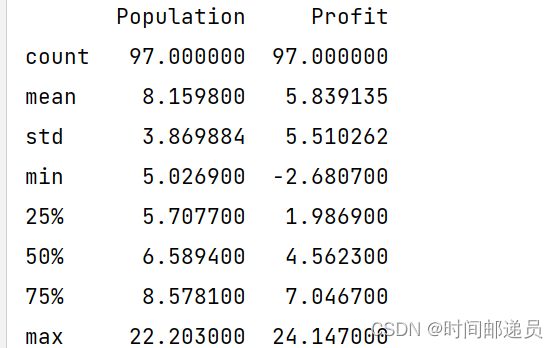
data.plot(kind='scatter', x='Population', y='Profit', figsize=(12, 8))
plt.show() #显示图像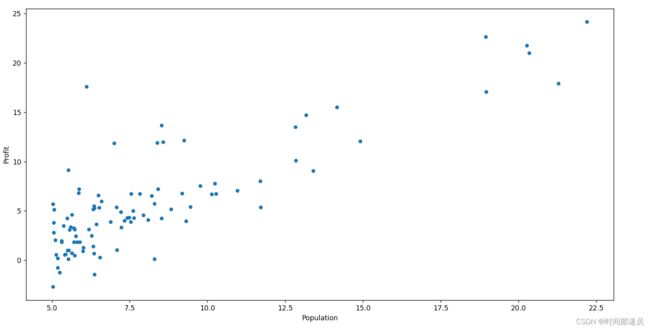
计算代价函数J(θ)
现在让我们使用梯度下降来实现线性回归,以最小化代价函数
首先,我们创建一个以参数θ为特征的代价函数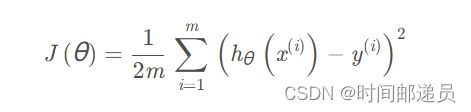
其中:
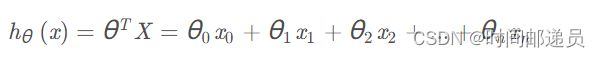
计算代价函数J(θ):
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))在训练集中添加一列,以便我们可以使用向量化的解决方案来计算代价和梯度
data.insert(0, 'Ones', 1)
变量初始化并计算
cols = data.shape[1] # 列数
X = data.iloc[:,0:cols-1] # 取前cols-1列,即输入向量
y = data.iloc[:,cols-1:cols] # 取最后一列,即目标向量
print(X.head())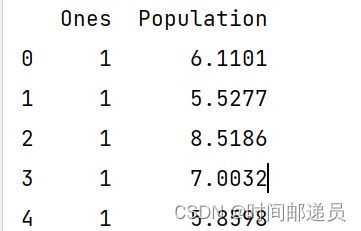
print(y.head()) 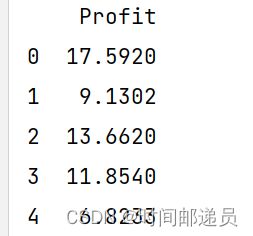
代价函数是应该是numpy矩阵,所以我们需要转换X和y,然后才能使用它们。,同时我们还需要初始化theta
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix(np.array([0, 0]))计算初始代价函数的值 (theta初始值为0)
print(computeCost(X, y, theta)) #32.072733877455676
四、批量梯度下降
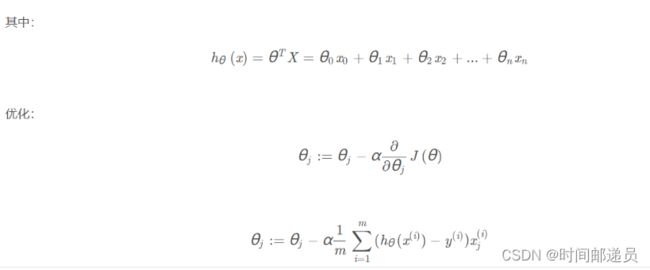
梯度下降函数代码实现:大家可以Debug调试,对每一个变量进行分析,这样理解更加容易
def gradientDescent(X, y, theta, alpha, iters):
temp = np.matrix(np.zeros(theta.shape)) # 构建零值矩阵
parameters = int(theta.ravel().shape[1]) # ravel功能将多维数组降至一维
cost = np.zeros(iters) # 构建iters个0的数组
for i in range(iters):
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:, j]) # 计算两矩阵(hθ(x)-y)x
temp[0, j] = theta[0, j] - ((alpha / len(X)) * np.sum(term))
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost初始化一些附加变量 - 学习速率α和要执行的迭代次数
alpha = 0.01
iters = 1000现在让我们运行梯度下降算法来将我们的参数θ应用于训练集并计算误差。
g, cost = gradientDescent(X, y, theta, alpha, iters)
print(computeCost(X, y, g))#4.515955503078914现在我们来绘制线性模型以及数据,直观地看出它的拟合
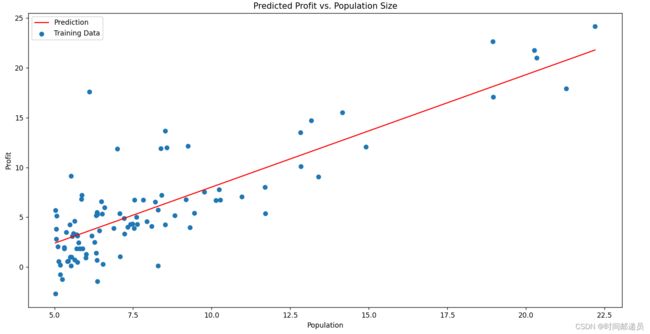
x = np.linspace(data.Population.min(), data.Population.max(), 100) # 抽100个样本
f = g[0, 0] + (g[0, 1] * x) # g[0,0]代表theta0 , g[0,1]代表theta1
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Training Data')
ax.legend() # 添加图例
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
# plt.show()
由于梯度方程式函数也在每个训练迭代中输出一个代价的向量,所以我们也可以绘制。 请注意,线性回归中的代价函数总是降低的
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(np.arange(iters), cost, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
# plt.show()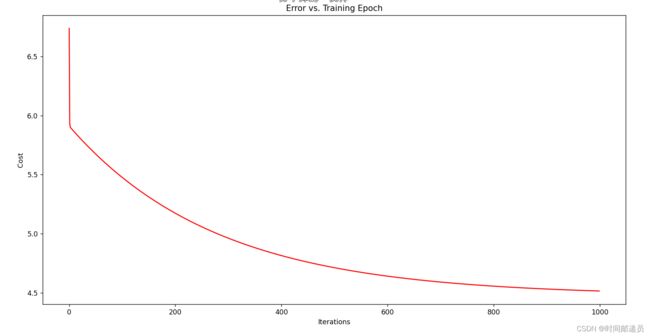
五、多变量线性回归
我前面给出的数据集还包括一个房屋价格数据集,其中有2个变量(房子的大小,卧室的数量)和目标(房子的价格),这不就是典型的多变量吗,其实和单变量的实现过程也差不多。
读入数据
path = 'ex1data2.txt'
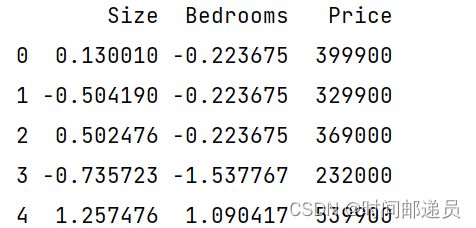
data2 = pd.read_csv(path, header=None, names=['Size', 'Bedrooms', 'Price'])
print(data2.head())归一化
变量初始化并计算
data2.insert(0, 'Ones', 1)
cols = data2.shape[1]
print(data2)
X2 = data2.iloc[:, 0:cols - 1]
y2 = data2.iloc[:, cols - 1:cols]
X2 = np.matrix(X2.values)
y2 = np.matrix(y2.values)
theta2 = np.matrix(np.array([0, 0, 0]))
g2, cost2 = gradientDescent(X2, y2, theta2, alpha, iters)
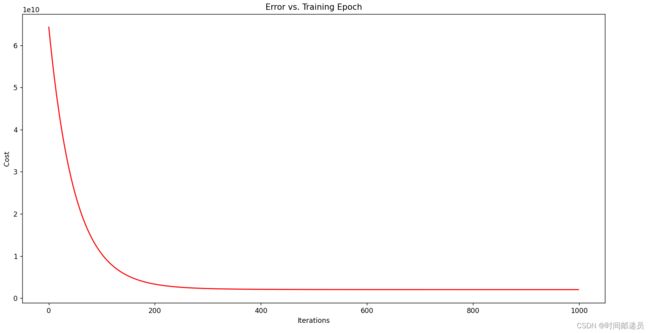
computeCost(X2, y2, g2)我们也可以快速查看它的的训练进程。
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(np.arange(iters), cost2, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
六、Normal Equation(正规方程)
前一节已经具体讲了正规方程的表达式以及求θ的方式,这里只需要代入参数即可
# 正规方程
def normalEqn(X, y):
theta = np.linalg.inv(X.T @ X) @ X.T @ y
return thetafinal_theta = normalEqn(X, y)
print(final_theta)