Agent检索增强生成
检索增强生成(RAG)设计模式通常用于在特定数据域中开发大语言模型(LLM)应用。然而,RAG的过往的研究重点主要在于提高检索工具的效率,例如嵌入搜索、混合搜索和微调嵌入,而忽视了智能搜索。本文介绍了一种受人类研究方法启发的新方法,该方法涉及多种搜索技术、观察临时结果、精炼以及在提供响应之前在多步骤过程中重试。本文提出基于智能Agent的检索增强方案,突破传统RAG模式的局限性,构建更加智能、更加贴近事实的LLM应用。
1 - 基本RAG模式和限制
标准RAG模式实现概述:

-
该过程首先根据用户的问题或对话创建查询,通常通过提示语言模型(LLM)。这通常称为查询重写步骤。
-
然后将该查询分派到搜索引擎,搜索引擎返回相关知识(检索)。
-
然后,检索到的信息会通过包含用户问题的提示进行增强,并转发给LLM。
-
最后,LLM对用户的查询(生成)做出回应。
RAG的局限性:
-
在RAG模式中,检索、增强和生成由单独的进程管理。LLM可能会通过不同的提示来进行每个过程。然而,直接与用户交互的LLM通常最了解回答用户查询所需的内容。检索LLM可能不会以与生成LLM相同的方式解释用户的意图,从而为其提供可能妨碍其响应能力的不必要的信息。
-
每个问题都会执行一次检索,没有来自LLM的任何反馈循环。如果由于搜索查询或搜索词等因素导致检索结果不相关,LLM缺乏纠正这种情况的机制,可能会诉诸捏造答案。
-
检索的上下文一旦提供就不可更改且无法扩展。例如,如果研究结果表明需要进一步调查,例如检索到的文档引用了应进一步检索的另一文档,则没有此规定。
-
RAG模式不支持多步骤迭代搜索。
2 - Agent智能RAG模式原理
智能Agent模型在回答缺乏直接知识的问题时从人类的研究方法中汲取灵感。在此过程中,在提供最终答案之前,可以执行一次或多次搜索以收集有用的信息。每次搜索的结果可以确定是否需要进一步调查,如果需要,则确定后续搜索的方向。这个迭代过程一直持续到我们相信我们已经积累了足够的知识来回答,或者得出结论我们无法找到足够的信息来回答。有时,研究结果可以进一步阐明用户的意图和查询范围。
为了复制这种方法,建议开发一个由语言模型(LLM)提供支持的智能Agent,用于管理与用户的对话。Agent自主确定何时需要使用外部工具进行研究,制定一个或多个搜索查询,进行研究,审查结果,并决定是否继续进一步研究或寻求用户的澄清。此过程一直持续到Agent认为自己已准备好向用户提供答案为止。
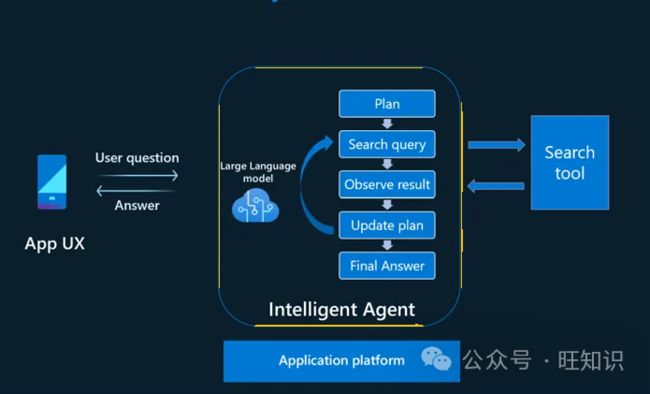
3 - Agent智能RAG模式实现
可以借助Azure OpenAI的功能调用能力来实现一个能自主使用搜索工具查找所需信息以协助处理用户请求的Agent。仅这一项功能就简化了RAG模式的传统实现方式(如前所述包括查询改写、增强和生成的独立步骤)。
Agent使用系统定义的角色和目标与用户交互,同时了解其可以使用的搜索工具。当Agent需要查找它不具备的知识时,它会制定搜索查询并向搜索引擎发出信号以检索所需的答案。
这个过程不仅让人想起人类行为,而且比RAG模式更有效。在RAG模式中,知识检索是一个单独的过程,无论是否需要都向聊天机器人提供信息。
实现此功能分为以下几步:
(1)定义角色、预期行为和要使用的工具以及何时使用。
PERSONA = """
You are Maya, a technical support specialist responsible for answering questions about computer networking and system.
You will use the search tool to find relavent knowlege articles to create the answer.
Answer ONLY with the facts from the search tool. If there isn't enough information, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question.
Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brakets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].
If the user is asking for information that is not related to computer networking, say it's not your area of expertise.
"""
(2)定义json格式的函数规范,包含函数和参数描述。
FUNCTIONS_SPEC= [
{
"name": "search_knowledgebase",
"description": "Searches the knowledge base for an answer to the technical question",
"parameters": {
"type": "object",
"properties": {
"search_query": {
"type": "string",
"description": "The search query to use to search the knowledge base"
},
},
"required": ["search_query"],
},
},
] 有趣的是,“用于搜索知识库的搜索查询”的参数描述起着至关重要的作用。它指导LLM根据帮助用户进行对话所需的内容制定合适的搜索查询。此外,可以描述搜索查询参数并将其限制为遵守特定的工具格式,例如Lucene查询格式。还可以结合其他参数来执行过滤等任务。
(3)实现函数调用流程。

此时,我们开发了一种能够进行独立搜索的智能Agent。然而,为了真正创建一个能够承担更复杂的研究任务(例如多步骤和自适应执行)的智能Agent,我们还需要实现一些额外的功能。
为了增加Agent在系统消息中计划、行动、观察和调整的能力,我们需要在角色定义中添加如下信息:
Being smart in your research. If the search does not come back with the answer, rephrase the question and try again.Review the result of the search and use it to guide your next search if needed.If the question is complex, break down to smaller search steps and find the answer in multiple steps.
更新之后的角色定义如下:
PERSONA = """You are Maya, a technical support specialist responsible for answering questions about computer networking and system.You will use the search tool to find relavent knowlege articles to create the answer.Being smart in your research. If the search does not come back with the answer, rephrase the question and try again.Review the result of the search and use it to guide your next search if needed.If the question is complex, break down to smaller search steps and find the answer in multiple steps.Answer ONLY with the facts from the search tool. If there isn't enough information, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question.Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brakets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].If the user is asking for information that is not related to computer networking, say it's not your area of expertise."""
添加的指令表示机器人应该重试并根据需要更改问题。此外,它还表示机器人应该审查搜索结果以指导下一次搜索,并在需要时采用多步骤方法。这假设可以多次调用搜索工具。
由于LLM无法自行重复此过程,因此我们需要使用应用程序逻辑来管理此过程。我们可以通过将整个过程放在一个循环中来做到这一点。当模型准备好给出最终答案时,循环退出:
while True:
response = openai.ChatCompletion.create(
deployment_id=self.engine, # The deployment name you chose when you deployed the GPT-35-turbo or GPT-4 model.
messages=conversation,
functions=self.functions_spec,
function_call="auto"
)
response_message = response["choices"][0]["message"]
# Step 2: check if GPT wanted to call a function
if response_message.get("function_call"):
print("Recommended Function call:")
print(response_message.get("function_call"))
print()
# Step 3: call the function
# Note: the JSON response may not always be valid; be sure to handle errors
function_name = response_message["function_call"]["name"]
# verify function exists
if function_name not in self.functions_list:
raise Exception("Function " + function_name + " does not exist")
function_to_call = self.functions_list[function_name]
# verify function has correct number of arguments
function_args = json.loads(response_message["function_call"]["arguments"])
if check_args(function_to_call, function_args) is False:
raise Exception("Invalid number of arguments for function: " + function_name)
search_query = function_args["search_query"]
print("search_query", search_query)
# check if there's an opportunity to use semantic cache
if function_name == "search_knowledgebase":
if os.getenv("USE_SEMANTIC_CACHE") == "True":
cache_output = get_cache(search_query)
if cache_output is not None:
print("semantic cache hit")
conversation.append({"role": "assistant", "content": cache_output})
return False, query_used, conversation, cache_output
else:
print("semantic cache missed")
query_used = search_query
function_response = function_to_call(**function_args)
print("Output of function call:")
print(function_response)
print()
# Step 4: send the info on the function call and function response to GPT
# adding assistant response to messages
conversation.append(
{
"role": response_message["role"],
"name": response_message["function_call"]["name"],
"content": response_message["function_call"]["arguments"],
}
)
# adding function response to messages
conversation.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
) # extend conversation with function response
continue
else:
break # if no function call break out of loop as this indicates that the agent finished the research and is ready to respond to the user完整代码可以参考:
https://github.com/microsoft/OpenAIWorkshop/blob/sephack/scenarios/incubations/copilot/smart_agent/utils.py
以下是演示场景中正在运行的智能Agent:

问题是对两种产品之间的功能进行比较。每个产品的功能都存储在单独的文档中。为此,我们的Agent执行两个搜索查询:
X100 vs Z200 power profile for Radio 0
X100 power profile for Radio 0
第一个查询是一种贪婪方法,因为Agent希望有一个包含比较的文档。情况并非如此,因为搜索查询没有返回有关X100的足够信息,因此添加了专用于X100的第二个查询。
如果将其提供给经典的RAG解决方案,它将无法找到好的答案,因为它会在第一个查询处停止。
4 - 结论
实施Agent模式可以显着增强LLM应用能力。这是由于该模式具有测试各种策略并根据观察到的结果改进其方法的智能能力。