机器人强化学习——Sim-to-Real Robot Learning from Pixels with Progressive Nets (2017)
论文地址:https://arxiv.org/abs/1610.04286
1 简介
针对现实世界中DRL对复杂任务学习慢的问题,提出progressive networks来将仿真中学习的策略迁移到真实世界中。
progressive networks是个通用框架,核心思想是将 从低维视觉特征到高级policy之间的所有东西 迁移到新任务,实现方式是将其他任务上预训练的特征通过侧面连接输入到新任务的网络中。
实验表明,只使用DRL和稀疏奖励来学习任务是可行的。
2 progressive netowrks 介绍
侧面连接:新网络的某一层以该新网络的前一层和以前任务网络的前一层为输入。结构如下:
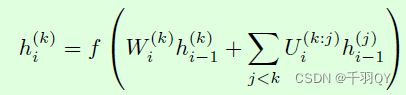
第 k k k个网络的第 i i i层值的计算公式如下:
其中。 f ( ) f() f()为Relu函数。
该结构的优点:
(1)不会通过微调改变为其他任务学习的特征;
(2)不同结构的子网络可以使用不同模态的输入,或提高学习速度;
(3)增加了网络容量,包括不同的新输入。
可以改变每个网络的宽度(层的神经元个数)、不同任务的难度、连接单个或多个以前的任务网络。
3 progressive network 网络在DRL的应用

该网络中的每个子网络学习一个特殊的任务。
对 progressive network 设计如下技巧:
(1)不同的子网络可以有不同的容量和结构。
在仿真中训练的子网络有更大的容量和深度来从头学习任务,在真实机器人上学习的子网络有更小的容量,从而加快学习并限制参数。
(2)任务互补序列的输出层 不需要 layer-wise adapters。(adapters的概念看progressive network原论文)
(3)使用仿真中训练的子网络输出层初始化真实机器人上子网络的输出层,真实任务网络的最后一层权重设为0,复制仿真任务网络的最后一层权重到侧向连接权重。
由于设为0,真实任务网络中的参数无法改变输出,则输出全部由仿真任务网络的权重决定。这使得现实机器人上的初始策略与仿真中训练完成的策略相同。
4 实验
4.1 实验设置
任务:机械手末端运动至目标位置上,目标位置通过红色方块指出,目标位于 40 ∗ 30 c m 40*30cm 40∗30cm的区域内。
方法:采用 Kinova Jaco 6-DOF机械臂,子网络采用 A3C 算法,输入state为 3 ∗ 64 ∗ 64 3*64*64 3∗64∗64的原始图像,输出为9个policy和1个value,每个policy包括三个action: 正的固定关节速度、负固定速度、零,每个policy的输出由softmax激活。9个policy对应6个机械臂关节和三指机械手。
实验测试了两种A3C网络的性能:
(1)输入->卷积1->卷积2->全连接->输出
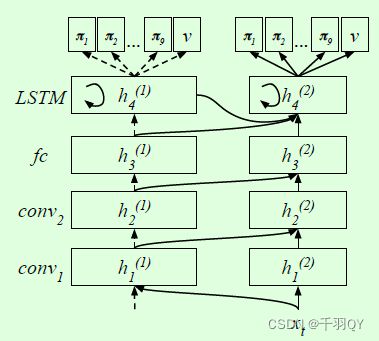
(2)输入->卷积1->卷积2->全连接->LSTM->输出,如下图所示:
各网络的具体参数见论文。
步进网络包括两个子网络。子网络1在仿真中训练,卷积核数更多,全连接层的神经元也更多;子网络2在真实中训练,卷积核数和神经元数更少。
reward:如果机械手距离目标区域小于10cm,则reward获得 + 1 +1 +1,否则为0。每个episode最多执行 50 step,直到step结束或产生安全问题。
实验表明,表现好的agent可以快速进入目标区域,并保持在安全的位姿,平均得分30。
4.2 仿真训练
实验表明宽的网络结构(卷积核数和神经元数多)在学习速度和性能上都更好,LSTM比全连接层性能更好。
5千万step后,性能趋于稳定。
测试了30组不同的学习率和entropy costs,选出性能最好的网络作为待迁移的子网络1。
entropy costs 是什么?
4.3 迁移至机器人
reward通过识别红色目标物体的位置和获得机械手的位置得到。
baseline1:不在仿真中训练,直接在真实场景中从头训练;
baseline2:在仿真中训练后,在真实中微调子网络1,没有子网络2。
三个网络均在真实中训练60000 step(约4小时)。
实验结果:
(1)步进网络性能最好;
(2)baseline1的reward一直是0,训练失败;
(3)baseline2的性能比步进网络差。
稳定性比较:
在仿真中训练好子网络1后,改变颜色和视角,并在仿真中训练步进网络和baseline2网络,分别测试了300组不同的seed、学习率、entropy costs。
结果表明,步进网络更稳定且性能更好。
4.4 迁移至包含本体数据的动态机器人任务
任务:通过增加滑轮装置,使红色目标在桌子上滑动,并随机逆向移动;机械手需要跟踪红色目标。
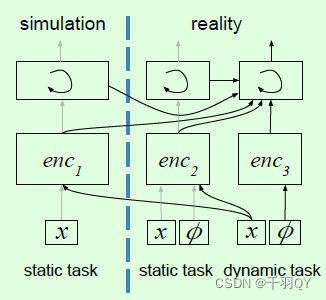
方法:子网络1以图像为输入,在仿真的固定目标reach任务中训练;子网络2以图像和本体特征为输入,在真实的固定目标reach任务中训练;子网络3以本体特征为输入,并将图像输入子网络1和2,在真实的动态目标跟踪任务中训练。训练一个子网络时,其他子网络不更新。
本体特征 (proprioceptive features):9个关节角和速度,共18个标量输入。
本体特征的输入方式:经过一层MLP和Relu,和子网络的卷积层输出合并,继续向后传输(参考google那个机械臂农场的论文)。
Encoder 1 is a convolutional net, encoder 2 is a convolutional net with proprioceptive features added before the LSTM, and encoder 3 is an MLP。网络结构如下:
方法对比:
(1)baseline:和4.4.3的方法一样,子网络2在动态目标跟踪任务中训练。学习速度很慢,需要50000 step才达到稳定;
(2)本节方法:学习速度很快。
表明步进网络可用于curriculum task (课程任务,由易到难的学习任务),且可以保留以前学习的特征(保留子网络2的特征)。