结离婚数据分析完整数据代码数据
这里你可以编写代码,文档
关于文件目录
project:project 目录是本项目的工作空间,可以把将项目运行有关的所有文件放在这里,目录中文件的增、删、改操作都会被保留
input:input 目录是数据集的挂载位置,所有挂载进项目的数据集都在这里,未挂载数据集时 input 目录被隐藏
temp:temp 目录是临时磁盘空间,训练或分析过程中产生的不必要文件可以存放在这里,目录中的文件不会保存
In [28]:
import pandas as pd import numpy as np
In [45]:
df=pd.read_csv('/home/mw/input/marrieddata8411/data.csv')
df.head()
Out[45]:
| 地区 | 年份 | 结婚登记(万对) | 内地居民登记结婚(万对) | 内地居民初婚登记(万对) | 内地居民再婚登记(万对) | 涉外及港澳台居民登记结婚(万对) | 离婚登记(万对) | 粗离婚率(‰) | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 北京市 | 2022年 | 9.13 | 9.09 | 11.81 | 6.45 | 0.04 | 4.42 | 2.02 |
| 1 | 北京市 | 2021年 | 10.34 | 10.29 | 13.63 | 7.04 | 0.04 | 5.04 | 2.30 |
| 2 | 北京市 | 2020年 | 11.38 | 11.34 | 12.43 | 10.33 | 0.04 | 8.19 | 3.77 |
| 3 | 北京市 | 2019年 | 12.90 | 12.82 | 14.15 | 11.64 | 0.08 | 8.38 | 3.89 |
| 4 | 北京市 | 2018年 | 13.78 | 13.70 | 16.92 | 10.65 | 0.08 | 7.41 | 3.43 |
In [46]:
#内地居民登记结婚(万对)比内地居民初婚登记(万对)少?结婚不是包括初婚和再婚嘛?
items = [
[
col,
df[col].dtype,
df[col].isnull().sum(),
] for col in df
]
display(pd.DataFrame(data=items, columns=[
'Attributes',
'Data Type',
'Total Missing',
]))
| Attributes | Data Type | Total Missing | |
|---|---|---|---|
| 0 | 地区 | object | 0 |
| 1 | 年份 | object | 0 |
| 2 | 结婚登记(万对) | float64 | 0 |
| 3 | 内地居民登记结婚(万对) | float64 | 0 |
| 4 | 内地居民初婚登记(万对) | float64 | 0 |
| 5 | 内地居民再婚登记(万对) | float64 | 1 |
| 6 | 涉外及港澳台居民登记结婚(万对) | float64 | 50 |
| 7 | 离婚登记(万对) | float64 | 0 |
| 8 | 粗离婚率(‰) | float64 | 217 |
In [47]:
#缺失值处理 df['涉外及港澳台居民登记结婚(万对)']=df['涉外及港澳台居民登记结婚(万对)'].fillna(df["结婚登记(万对)"] - df["内地居民登记结婚(万对)"]) df['内地居民再婚登记(万对)']=df['内地居民再婚登记(万对)'].fillna(df["内地居民登记结婚(万对)"] - df["内地居民初婚登记(万对)"])
In [48]:
df.drop_duplicates(inplace=True) df.reset_index(inplace=True,drop=True)
In [49]:
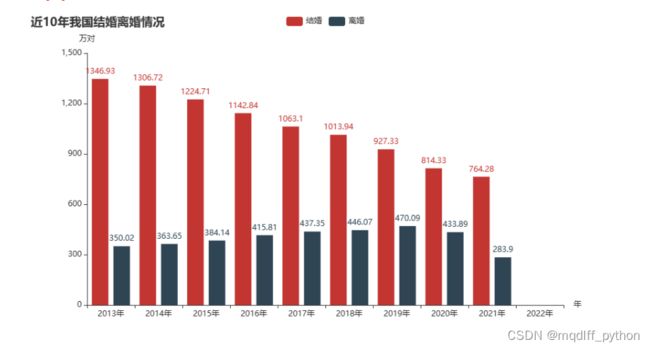
#分析一下近十年我国结婚离婚情况
data=df.groupby('年份')[['结婚登记(万对)','离婚登记(万对)']].agg({'结婚登记(万对)':np.sum,'离婚登记(万对)':np.sum})
In [52]:
data.index.tolist()[-10:-1] round(data['结婚登记(万对)'],2).tolist()[-10:-1] round(data['离婚登记(万对)'],2).tolist()[-10:-1]
Out[52]:
[350.02, 363.65, 384.14, 415.81, 437.35, 446.07, 470.09, 433.89, 283.9]
In [53]:
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.charts import Line
import matplotlib.pyplot as plt
c=(
Bar()
.add_xaxis(data.index.tolist()[-10:])
.add_yaxis("结婚",round(data['结婚登记(万对)'],2).tolist()[-10:-1])
.add_yaxis("离婚",round(data['离婚登记(万对)'],2).tolist()[-10:-1])
.set_global_opts(
title_opts=opts.TitleOpts(title="近10年我国结婚离婚情况"),
yaxis_opts=opts.AxisOpts(name="万对"),
xaxis_opts=opts.AxisOpts(name="年"))
.render_notebook()
)
c
Out[53]:
In [55]:
#分析各地区离结率
df_area=df.groupby("地区")[['结婚登记(万对)','离婚登记(万对)']].agg({'结婚登记(万对)':np.sum,'离婚登记(万对)':np.sum})
In [56]:
df_area.index.tolist() df_area['离结率']=round(df_area['离婚登记(万对)']/df_area['结婚登记(万对)']*100,2) df_area['离结率'].tolist()
In [57]:
from pyecharts import options as opts
from pyecharts.charts import Map
c = (
Map()
.add("离结率", [list(z) for z in zip(df_area.index.tolist(), df_area['离结率'].tolist())], "china",is_roam=False)
.set_global_opts(
title_opts=opts.TitleOpts(title="各地离结率"),
visualmap_opts=opts.VisualMapOpts(max_=100, is_piecewise=True),
tooltip_opts=opts.TooltipOpts(formatter='{b}:{c}%')
)
.render_notebook()
)
c
#可以看到东北三省“黑吉辽”、天津市、重庆市、上海市的离结率较高,可能东北那边大男子主义居多?其他就是较发达的地区离结率居高
Out[57]:

In [59]:
#分析一下各地区初婚占结婚对数的比率
df_new=df[['地区','年份','内地居民初婚登记(万对)','内地居民再婚登记(万对)']]
data=df_new.groupby('年份')[['内地居民初婚登记(万对)','内地居民再婚登记(万对)']].agg({'内地居民初婚登记(万对)':np.sum,'内地居民再婚登记(万对)':np.sum})
In [61]:
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(data.index.tolist()[-10:])
.add_yaxis("初婚登记", round(data['内地居民初婚登记(万对)'],2).tolist()[-10:], stack="stack1", category_gap="50%",label_opts=opts.LabelOpts(
position="inside"))
.add_yaxis("再婚登记",round(data['内地居民再婚登记(万对)'],2).tolist()[-10:], stack="stack1", category_gap="50%",label_opts=opts.LabelOpts(
position="top"))
.render_notebook()
)
c
Out[61]:
