Bert模型的基本原理与Fine-tuning
文章目录
-
- 基本原理
- BERT的输入
- Fine-tuning(微调)
-
- BERT用于sequence的分类任务
- BERT用于问答任务
- BERT用于 NER(实体命名识别)
本文主要讲解Bert模型的基本原理与Fine-tuning。
基本原理
BERT是一种 预训练语言模型 ,即首先使用大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成具体NLP任务(分类、序列标注、句间关系判断和机器阅读理解等)。
BERT的全称是Bidirectional Encoder Representation from Transformers,即:基于transformer的双向Encoder,所以在学习BERT之前先对Self-Attention与transformer进行学习,具体可以参考深入理解 Bert核心:Self-Attention与transformer。
该模型的主要创新点在:(1)使用了MAsk机制捕捉句子中词语之间的的representation。(2)使用了Next Sentence Prediction捕捉句子级别的representation。
回顾一下transformer模型:
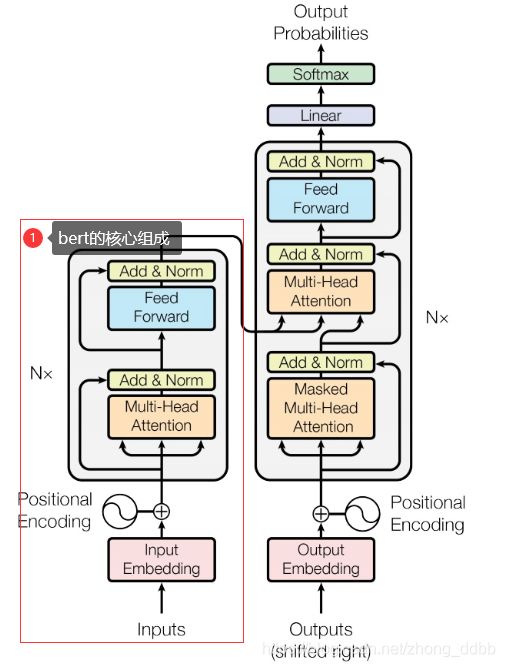
图中的(1)就是bert模型的核心组成部分,将这样的结构进行堆叠,就是BERT 模型。如下图:
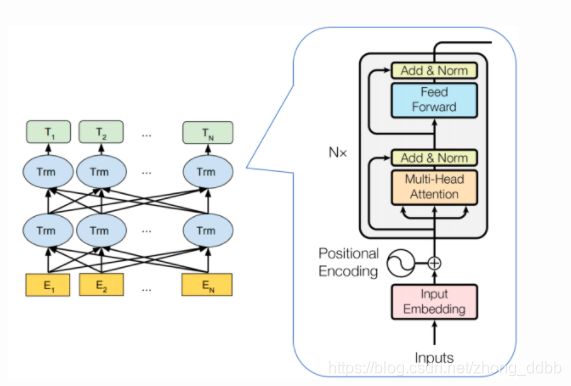
在transformer中,每一个输入分别对应一个Embedding输出,将其称之为隐向量。在做具体NLP任务的时候,只需要从中取对应的隐向量作为输出即可。
Bert模型的两个基本预任务:
(1)Masked Language Model(MLM)
通过随机掩盖一些词(替换为统一标记符[MASK]),然后预测这些被遮盖的词来训练双向语言模型,并且使每个词的表征参考上下文信息。此处产生loss_1。
(2)Next Sentence Prediction(NSP)
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。每次的训练样本是一个上下句,其中一半的样本是正样本(上下句之间的对应关系是真实的);另外一半样本是负样本(上下句之间是无关的)。此处产生loss_2。
模型的loss为:loss_1+ loss_2。
此处插入一个预训练模型(GPT,BERT,ELMO)小对比。三个模型如下图所示:
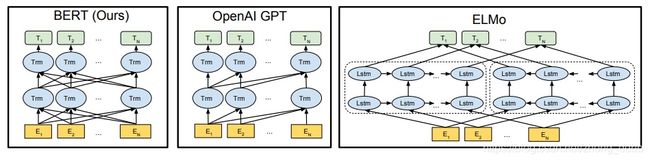
注:图中的Trm与LSTM一样只是代表一个单元。那些复杂的连线表示的是词与词之间的依赖关系,BERT中的依赖关系既有前文又有后文,而GPT的依赖关系只有前文。
GPT是单向模型,预测时只能预测下一个词;BERT和ELMO是双向模型,其中,而BERT是预测文中扣掉的词,可以充分利用到上下文的信息,这使得模型有更强的表达能力,这也是BERT中Bidirectional的含义。BERT和ELMO都是双向,但二者的目标函数不同。
ELMO的目标函数为:
P ( w i ∣ w 1 , ⋯ w i − 1 ) 和 P ( w i ∣ w i + 1 , ⋯ w n ) P(w_i|w_1,\cdots w_{i-1})和 P(w_i|w_{i+1},\cdots w_n) P(wi∣w1,⋯wi−1)和P(wi∣wi+1,⋯wn)
独立训练处两个representation然后拼接。
BERT的目标函数为:
P ( w i ∣ w 1 , ⋯ w i − 1 , w i + 1 , ⋯ w n ) P(w_i|w_1,\cdots w_{i-1},w_{i+1},\cdots w_n) P(wi∣w1,⋯wi−1,wi+1,⋯wn)
BERT的输入
如下图所示是BERT模型的“my dog is cute, he likes playing.”的输入形式:
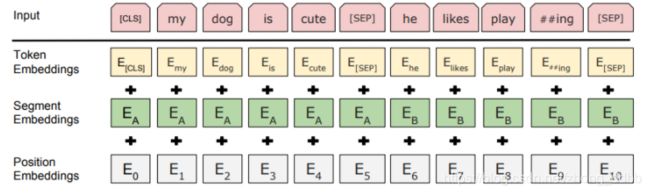
每个输入由3部分构成,其中
- Token Embeddings是词向量,第一个单词是CLS(Classification)标志,可以用于之后的分类任务;第一个SEP表示第一个句子的结束,同时标志第二个句子开始。
- Segment Embeddings用来区别两种句子,因为预训练不光做LM(语言模型)还要做以两个句子为输入的分类任务
- Position Embeddings表示位置信息,这里的位置embedding是通过学习的方式得到的。
Fine-tuning(微调)
BERT用于sequence的分类任务
分类任务包括对单句子的分类任务。左图表示两个句子的分类,如比如判断两句话是否表示相同的含义;右边是单句子分类,如:比如判断电影评论是喜欢还是讨厌。
预训练中的NSP任务使得BERT中的“[CLS]”位置的输出包含了整个句子对(句子)的信息,我们利用其在有标注的数据上微调(Fine-tuning)模型,给出预测结果。
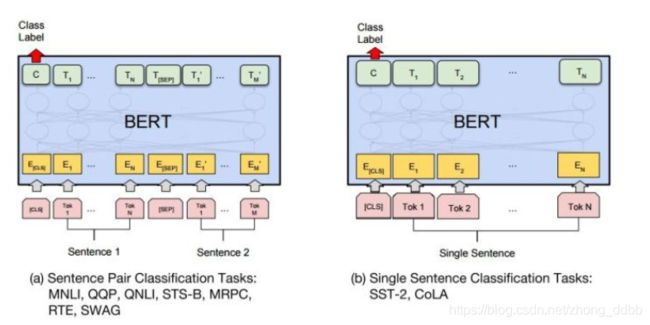
所以,这两种情况,只需要在 Transformer 的输出之上加一个分类层。BERT直接取第一个[CLS]token的final hidden state C C C与权重相乘后做softmax,得到预测结果P:
P = s o f t m a x ( C W T ) P = softmax(CW^T) P=softmax(CWT)
BERT用于问答任务
预训练中的MLM任务使得每个Token位置的输出都包含了丰富的上下文语境以及Token本身的信息,我们对BERT的每个Token的输出都做一次分类,在有标注的数据上微调(Fine-tuning)模型并给出预测。
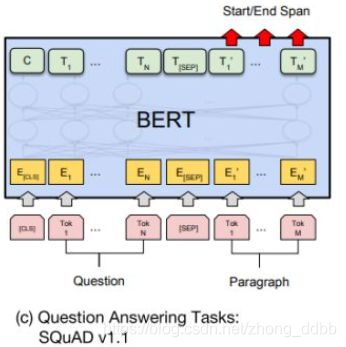
上图表示一个问答任务,给出一个问题Question,并且给出一个段落Paragraph,然后从段落中标出答案的具体位置。
(1)关于输入
输入部分由问题和包含答案的文本组成,并有特殊分隔符“【SEP】”分隔。同时输入序列为token embeddings,segmentation embeddings,以及position embedding之和。BERT的输出为每个token所对应的encoding vector。
(2)关于输出
假设vector的维度为D,那么整个输出序列为 T N × D T^{N \times D} TN×D,其中N为整个序列的长度。因为答案由文本中连续的token组成,所以预测答案的过程本质上是确定答案开头和结尾token所在的位置的过程。因此,经过全连接层之后,得到:
O N × 2 = F C ( T N × D ) O^{N \times 2} = FC(T^{N\times D}) ON×2=FC(TN×D)
其中 F C FC FC 代表全连接层, O N × 2 O^{N\times 2} ON×2 为每一个token分别作为答案开头和结尾的logit值,再经过Softmax层之后就得到了相应的概率值。经过数据后处理之后,便可得到预测答案。
举例说明如下:
(1) 数据集
来源:2016年开源的中文问答数据集,据片段如下图所示:

(2)数据预处理
首先对问题和证据进行tokenization的处理,即将sentence转为character level的sequence。将question sequence 和 evidence sequence相连接并以“【SEP】”分隔。在序列的开头增加“【CLS】”。为了保证输入序列长度一致,在连接的sequence后做padding处理。segmentation id 表征了token所在句子的信息,而input mask 表征了token是否为padding值。经过预处理后,输入序列如下:

注:对于question+evidence的长度大于BERT 规定的最大序列长度的情况,将evidence以一定的步长分割为若干段分别于question连接。为了保证分割后的evidence尽可能不削减完整evidence的语义。evidence与evidence之间有一定长度的重叠部分,该部分的长度为超参数可供用户调节。
BERT用于 NER(实体命名识别)
下图表示实体命名识别,比如给出一句话,对每个词进行标注,判断属于人名,地名,机构名,还是其他。在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。

(1)关于输入
每个序列的第一个token始终是特殊分类嵌入([CLS]),剩下的每一个token代表一个汉字。BERT的input embeddings 是token embeddings, segmentation embeddings 和position embeddings的总和。
其中token embeddings是词(字)向量,segment embeddings 用来区分两种句子,只有一个句子的任务(如序列标注),可以用来区分真正的句子以及句子padding的内容,而position embedding保留了每个token的位置信息。
(2)关于输出
BERT模型+FC layer(全连接层):
BERT的output 是每个token的encoding vector。只需要在BERT的基础上增加一层全连接层,一般情况下,在NER任务中,全连接层(经过softmax)的输出为4个维度,分别作为每一类的概率。(在NER任务中一般有4类:B表示实体的开始,I表示实体的中间,E表示实体的结束,O表示不是实体)。
并确定全连接层的输出维度,便可把embedding vector映射到标集合。词性标注问题的标签集合即中文中所有词性的集合。
BERT+CRF 模型
在BERT后连接一个CRF层,CRF是一种经典的概率图模型,CRF层可以加入一些约束来保证最终的预测结果是有效的。这些约束可以在训练数据时被CRF层自动学习得到。
为了满足BERT的要求,我们需要对数据进行预处理,将原文本拆分成一系列的汉字,并对每个汉字进行词性标注。
数据预处理,分词,构造标签;最终结果如下:
![]()
流程如下:

参考:
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
自然语言处理中的Transformer和BERT
【NLP】Google BERT模型原理详解
【技术分享】BERT系列(三)-- BERT在阅读理解与问答上应用
【技术分享】BERT系列(二)-- BERT在序列标注上的应用
【技术分享】BERT系列(一)——BERT源码分析及使用方法
美团BERT的探索和实践