ChatGPT炒股:整理北交所拟IPO的新三板企业
很多省份都会发布上市后备企业库名单。通常,这些名单会由各省的地方金融监督管理局或类似的政府机构发布。您可以通过访问这些机构的官方网站,或者通过搜索“省份名称 + 2023年上市后备企业名单”来查找相关信息。例如,如果您想要查找湖北省的名单,可以尝试搜索“湖北省2023年上市后备企业名单”。此外,一些经济新闻网站、金融信息服务平台或者地方政府的公告栏也可能发布这类信息。

我们可以把这些上市后备企业名单和新三板企业做对比,就能知道哪些新三板企业可能即将要申报北交所IPO了。
比如辽宁省上市后备企业库:
辽宁省上市后备企业库名单(381家).xlsx

全部的新三板股票名单:
新三板股票20231217.xlsx

在ChatGPT中输入提示词:
你是一个Python编程专家,要完成一个整理Excel表格数据的任务,具体步骤如下:
读取F盘的Excel文件:”辽宁省上市后备企业库名单(381家).xlsx”,获取B2列的所有单元格内容;
读取F盘的Excel文件:”新三板股票20231217.xlsx”,获取C2到C6240之间的所有单元格内容;
将”辽宁省上市后备企业库名单(381家).xlsx”中B2列的单元格内容,逐一和”新三板股票20231217.xlsx”的C2到C6240之间的所有单元格内容进行比对;
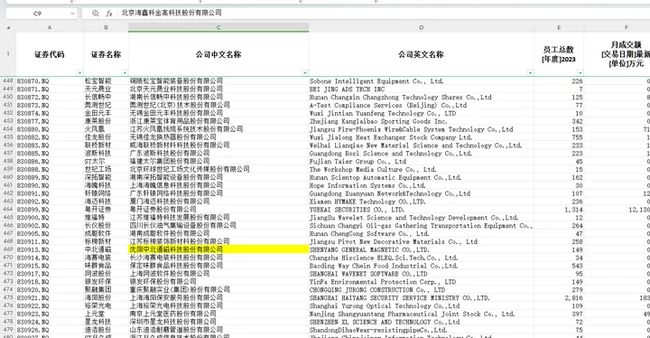
如果两者一致,那么将对应的”新三板股票20231217.xlsx”表格中的单元格填充为黄色;
注意:每一步都要输出相关信息

Python源代码如下:
import pandas as pd
from openpyxl import load_workbook
from openpyxl.styles import PatternFill
# 设置文件路径
ln_file_path = 'F:/辽宁省上市后备企业库名单(381家).xlsx'
nqb_file_path = 'F:/新三板股票20231217.xlsx'
# 读取 "辽宁省上市后备企业库名单(381家).xlsx" 文件
ln_workbook = pd.read_excel(ln_file_path, usecols="B") # 只读取B列数据
ln_companies = ln_workbook.iloc[1:].dropna().values.flatten() # 获取B2列及以下的所有单元格内容,去除NaN值
print(f"读取辽宁省上市后备企业名单中的 {len(ln_companies)} 家企业。")
# 读取 "新三板股票20231217.xlsx" 文件
nqb_workbook = load_workbook(nqb_file_path)
nqb_sheet = nqb_workbook.active
nqb_companies = [nqb_sheet[f'C{i}'].value for i in range(2, 6241)] # 获取C2到C6240的所有单元格内容
print("开始比对两个名单中的企业名称...")
# 设置填充颜色为黄色
yellow_fill = PatternFill(start_color='FFFF00', end_color='FFFF00', fill_type='solid')
# 比对公司名称并标记
for idx, company in enumerate(nqb_companies, start=2): # 从C2开始
if company in ln_companies:
nqb_sheet[f'C{idx}'].fill = yellow_fill
print(f"在新三板名单中找到匹配企业 '{company}',将C{idx}标记为黄色。")
# 保存修改后的文件
nqb_workbook.save('F:/新三板股票20231217_标记.xlsx')
print("完成比对,所有匹配的企业已在 '新三板股票20231217_标记.xlsx' 文件中标记。")
此脚本执行以下步骤:
设置两个Excel文件的路径。
使用 pandas 读取“辽宁省上市后备企业库名单(381家).xlsx”文件中的B列数据。
使用 openpyxl 读取“新三板股票20231217.xlsx”文件中C列的数据。
比较两个列表中的企业名称,并在找到匹配时使用 openpyxl 将相应的单元格填充为黄色。
保存标记过的“新三板股票20231217.xlsx”文件。
运行此脚本前,请确保文件确实位于F盘,并且文件名与代码中提供的完全一致。如果有任何路径或文件名不同,请相应修改代码中的字符串。此外,确保在运行脚本时关闭所有Excel文件,以避免文件访问冲突。