阿里云 ACK 云原生 AI 套件中的分布式弹性训练实践
作者:霍智鑫
众所周知,随着时间的推移,算力成为了 AI 行业演进一个不可或缺的因素。在数据量日益庞大、模型体量不断增加的今天,企业对分布式算力和模型训练效率的需求成为了首要的任务。如何更好的、更高效率的以及更具性价比的利用算力,使用更低的成本来训练不断的迭代 AI 模型,变成了迫切需要解决的问题。而分布式训练的演进很好的体现了 AI 模型发展的过程。
Distributed Training
分布式训练一般分为两种类型,数据并行和模型并行。数据并行是指每个训练 Worker 都保存有一份模型的副本,然后将大规模的数据进行切分,分布到每个训练 Worker 上进行计算,最后再进行集合通信统一计算结果的过程。在相当一段的时间内,该种模式是分布式训练的主流模式,因为模型的规模足以放进单个训练 Worker 之中,而数据的规模才是整体训练效率的瓶颈。利用分布式数据并行可以充分利用集群中的算力资源,并行处理庞大的数据集,以达到加速训练的效果。
而模型并行则是在模型非常庞大的情况下将模型进行切分,分布到不同的训练 Worker 中,然后训练数据按照模型的结构分布经过不同的训练 Worker,以达到用分布式的算力来训练大模型的效果。现在的大语言模型由于其体量的庞大,所以一般都是使用模型并行的模式来进行训练。

基于数据并行的分布式训练又分为两种不同的架构。
-
Parameter Server 架构:
有一个中心化的 Parameter Server 用来存储分布式训练的梯度,每一个训练 Worker 在进行每个 Step 的训练前都需要先从 Parameter Server 中先 pull 到最新的梯度信息,在这个 step 训练结束后再将训练的结果梯度 push 到 Parameter Server。在 Tensorflow 中,PS 模式的训练一般为异步的分布式训练,该情况下对于任务的全部 Worker 来说,其无需等待其他 Worker 的训练流程去同步梯度,只需要根据流程完成自身的训练即可。这种模式多用于基于 Tensorflow 的搜推广场景。
-
AllReduce 架构: 一个去中心化的同步的分布式训练模式,在分布式训练中一般采用 Ring-All Reduce,每个训练 Worker 只与自身左右 Rank 的 Worker 进行通信,这样就能形成一个通信环,经过环形通信可以使得每一个 Worker 中的梯度都同步到了其他的 Worker 中并完成计算。这种模式多用于 CV、NLP 的应用场景。

Elastic Training
上面我们介绍了分布式训练,现在来了解一下弹性分布式训练。什么是弹性训练?具体可以总结为三大块的能力:
- 训练规模弹性改变: 这里主要指的是弹性改变训练的 Worker 数目,扩容增加 Worker 数量以提升训练速度,缩容减少 Worker 数量以腾出部分集群资源;
- 训练过程弹性容错: 由于部分因素导致任务异常或可预见问题如 Spot 回收事件预示下的整体任务的容错,避免因为少部分 Worker 失败而直接导致的整个任务的失败;
- 训练资源弹性伸缩: 可以根据任务需要或者问题处理的判断来动态变更任务训练 Worker 的资源配置以达到一个更合理的任务 Worker 资源配比。

而弹性训练的能力带来的意义,大概也可以总结为三点:
-
大规模分布式训练容错,有效提升训练任务运行的成功率;
-
提升集群算力利用率,充分利用弹性来协调在离线任务的资源分配;
-
降低任务训练成本,使用可被抢占或稳定性稍差但成本更低的实例来进行训练从而整体层面降低成本。

PS Elastic Training
在 PS 模式下进行的弹性训练,由于其为异步模式,弹性的关键在于训练数据的划分。当其中一部分 Worker 失败之后,未被训练的数据或者失败 Worker 中的数据可以被剩下的 Worker 继续训练,当新的 Worker 加入之后,可以与现有的 Worker 一起参与进行训练。

DLRover
在蚂蚁 AI Infra 团队开源的项目 DLRover 中,其实现了 Training Master 来参与弹性训练。由 Training Master 来负责对任务的监听、数据集的划分、各角色资源的弹性。其中数据集的划分是弹性训练的关键,在 Master 中有一个 Dataset Shard Service 的角色来负责具体数据集的划分。
其将整个的数据集按照 Batch Size 进行切分,分为各个 Task Data,然后将 Task Data 放进数据集队列中供各个训练 Worker 进行消费。在 Dataset Shard Service 中存在着两个队列,所有未被训练消费的 Task Data 在 TODO 队列中,而正在被训练的 Task Data 则是在 DOING 队列,直到该 Data 训练结束 Worker 给出信号后,该 Task Data 才会完全出队。如果有训练 Worker 中途异常退出,检测超时的 Task Data 会重新进入 TODO 队列以供其他正常 Worker 进行训练。

DLRover 在 Kubernetes 上设计了一个 CRD ElasticJob,由 ElasticJob Controller 监听并创建一个 DLRover Master,再由该 Master 来创建 PS 和 Worker 的 Pod,并控制 PS 和 Worker 的弹性。

AllReduce Elastic Training
在 AllReduce 模式下进行的弹性训练,由于其为同步模式,弹性的关键在于如何保证训练的同步,同时还有为了同步梯度而建立起来的通信环的保持。当其中一部分 Worker 失败之后,剩下的 Worker 可以重建通信环继续训练,当新的 Worker 加入之后,可以与现有的 Worker 重建通信环进行训练。

Elastic Pytorch
Elastic Pytorch 是 Pytorch 中 AllReduce 模式的弹性分布式训练,其本质在每个 Worker 上启动一个 Elastic Agent,利用该 agent 的 monitor 对各个训练进程进行 listen,并且根据 Worker 进程的正常与否的情况来动态的在 Master 中的 Rendezvous Server 中进行注册 Worker 的信息,从而完成整个训练任务过程的弹性。目前这个过程可以在 Kubernetes 中利用 Pytorch Operator 运行。

Elastric Horovod
Horovod 是一个分布式的弹性训练框架,可以应用于 Tensorflow 或者 Pytorch 的分布式训练。同样是 AllReduce 模式的弹性分布式训练,Elastic Horovod 可以在运行过程中动态的自行触发调整训练 Worker 的数量,而不需要重启整个训练任务或者重新从持久化的 Checkpoint 中恢复训练状态,从而达到避免中断训练任务的目的。

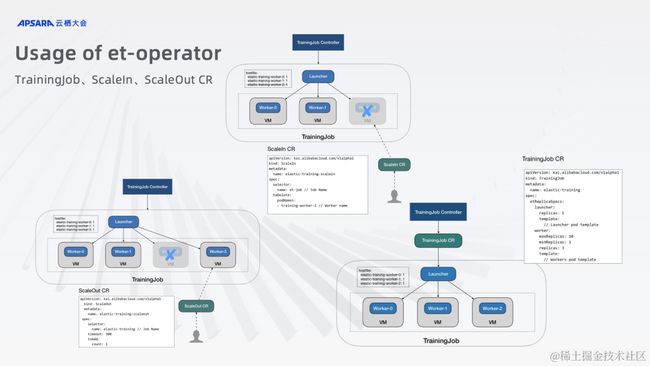
为了可以在 Kubernetes 上很好的运行 Elastic Horovod,ACK 团队实现了 Elastic Training Operator,其中有三个 CR。TrainingJob 是运行 Elastic Horovod 的任务承载,ScaleIn、ScaleOut 则分别作为任务缩容和扩容的触发 CR。用户可以通过以上三个 CR 来达到完成整个 Horovod Elastic 过程的目的。

用户可以通过提交 TrainingJob 来提交自己的 Elastic Horovod 任务,通过提交 ScaleIn 和 ScaleOut 来提交这个 Elastic Horovod 任务的缩容和扩容动作任务。
ACK 云原生 AI 套件 Elastic Training
基于上面几种(DLRover、Elastic Pytorch、Elastic Horovod)在 Kubernetes 中的弹性训练框架的方案,云原生 AI 套件提出了在 Spot 场景下的云原生 AI 弹性训练解决方案:
随着模型不断增大,AI 作业训练成本不断攀升,节省成本逐渐称为各行各业的关键命题。面向在 ACK 上做 AI 模型训练且成本敏感的客户,ACK 云原生 AI 套件在 ACK 上期望推广的弹性训练场景为基于抢占式实例 Spot 的弹性节点池作为底层训练资源的云原生 AI 弹性训练解决方案。
整体方案的目标在于以下几点:
-
期望将更多类型更多训练场景的 AI 训练任务在集群中以弹性的方式尽可能多的运行在成本更低的抢占式实例上;
-
这些训练任务可以根据客户需求动态的占用集群中空闲的资源,以达到资源利用率提升的目的;
-
使用该种弹性训练方式对客户 AI 训练任务的精度影响处于一个可以接受的范围内,不影响其最终的效果表现;
-
使用该种弹性训练方式可以使得客户的训练任务不会因为资源回收或者其他原因而导致整个任务进程的中断,进而丢失训练结果。
目前在 ACK 上,ACK 云原生 AI 套件提供了对 Elastic Horovod、DLRover (Tensorflow PS)、Elastic Pytorch 的支持,可以覆盖对 NLP、CV、搜推广场景的 AI 训练任务的支持,基本上涵盖了目前市面上的绝大多数的 AI 任务训练场景。
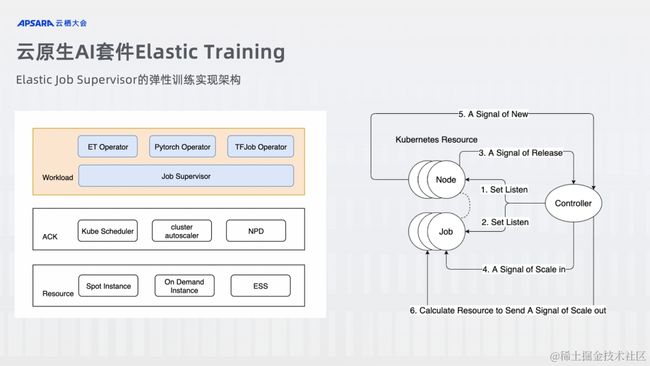
ACK 云原生 AI 套件提供了一个弹性训练控制组件 Elastic-Job-Supervisor,Elastic-Job-Supervisor 目前主要面向 Spot 场景做各个场景下弹性训练的控制。其可提供的 Spot 场景下的弹性训练能力有:
Max Wait Time: 若最大等待时长之前无法满足训练任务的资源请求时,则任务终止资源的等待,避免部分 Worker 申请资源后造成的浪费;

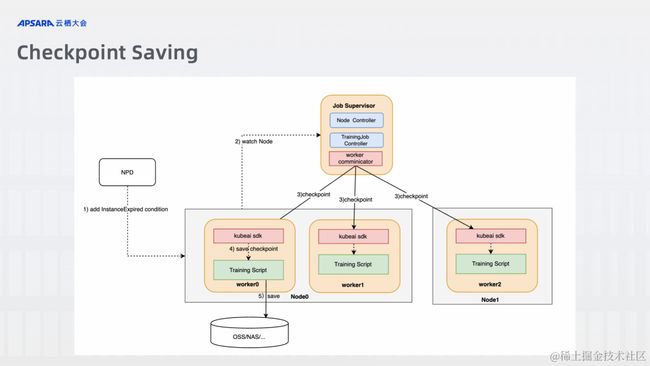
Checkpoint Saving: 拥有实例回收通知机制,使得训练任务在接收到抢占式实例回收的通知时进行自动的 Checkpoint Save 操作,以避免训练结果的丢失;
Fail Tolerance: 提交了一个分布式弹性训练任务,当部分实例被回收时,该分布式训练任务可以做到仍继续运行,不会因为部分 Worker 的回收而导致中断;

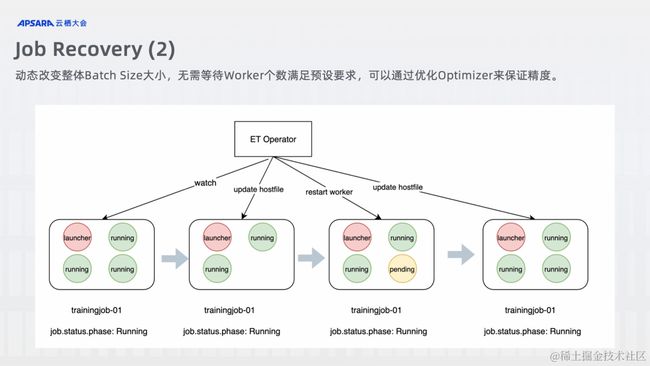
Job Recovery: 当集群中重新加入训练可用资源时,之前由于资源不足而 Suspended 的任务可以重新拉起继续进行训练,或者之前被缩容的分布式训练任务可以自动扩容到预设的 Replica 进行训练,这里又分为两种策略:
- 如果不满足预设的 Worker 数目,任务就会一直 Pending,知道满足了资源要求才会重启 Worker 恢复训练任务,该种情况下因为总 Worker 数不变,所以 Global Batch Size 就不变,进而最终精度也会得到保证。问题就在对资源是强要求,可能处在一直等待资源的状态中;
- 可以接受动态改变 Worker 的数量进行训练,即使不满足预设的 Worker 数量仍然不影响训练,也就是动态改变了 Global Batch 的大小。这种情况下是会影响模型最终训练的精度,可以通过选择合适的 Optimizer 算法和 Learning Rate 调整算法来尽可能的保证精度,或者使用梯度累积等方法来保证精度;

Cost Observability: 在使用抢占式实例进行训练时,可以利用 ACK 的 FinOps 对整体的训练成本的监控计算,展示基于抢占式实例 Spot 的弹性训练带来的成本节省。
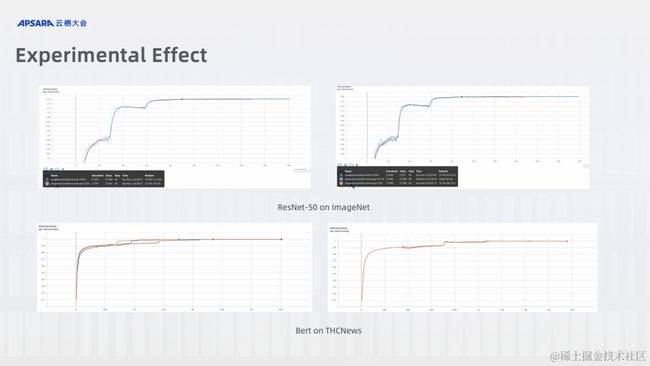

可以通过例子看到,通过实验验证,不同类型的分布式训练的副本数在一定的范围进行弹性的改变,加以一些相关的优化,其对精度的影响均处于可以接受的范围之内。在成本方面,通过在抢占式实例 Spot 上进行弹性变化 Worker 数量,可以在整体上将整个训练任务的花费成本降低到一个比较可观的值。与正常的按量付费云资源比起来,在 ResNet 上的测试可以达到 92% 的成本节省,在 BERT 上的测试可以达到 81% 的成本节省。
目前在较为热门的 LLM 场景下,ACK 云原生 AI 套件正在积极探索 DeepSpeed 等 LLM 训练框架下的弹性训练方案,以求将降低成本、提升训练成功率、提升资源利用率的效果用在 LLM 的训练之中。