【YOLOv8新玩法】姿态评估寻找链接切割点
学习《OpenCV应用开发:入门、进阶与工程化实践》一书
做真正的OpenCV开发者,从入门到入职,一步到位!
前言
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现工件切割点位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上训练,生成一个工件切割分离点预测模型
制作数据集
本人从网络上随便找到了个工业工件,然后写代码合成了一些数据,总计数据有360张图像、其中336张作为训练集、24张作为验证集。

其中YOLOv的数据格式如下:

解释一下:
Class-index 表示对象类型索引,从0开始 后面的四个分别是对象的中心位置与宽高 xc、yc、width、height
Px1,py1表示第一个关键点坐标、p1v表示师傅可见,默认填2即可。
模型训练
跟训练YOLOv8对象检测模型类似,直接运行下面的命令行即可:
yolo train model=yolov8n-pose.pt data=mul_lines_dataset.yaml epochs=15 imgsz=640 batch=1



模型导出预测
训练完成以后模型预测推理测试 使用下面的命令行:
yolo predict model=lines_pts_best.pt source=D:\bird_test\back1\2.png

导出模型为ONNX格式,使用下面命令行即可
yolo export model=lines_pts_best.pt format=onnx
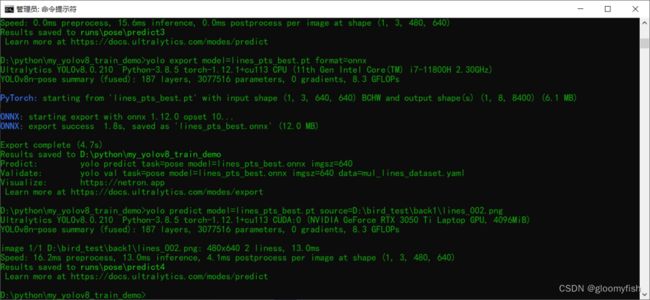
部署推理
基于ONNX格式模型,采用ONNXRUNTIME推理结果如下:
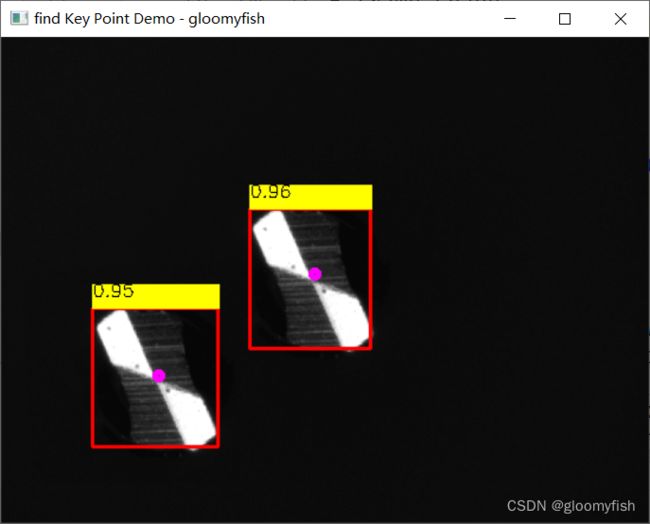
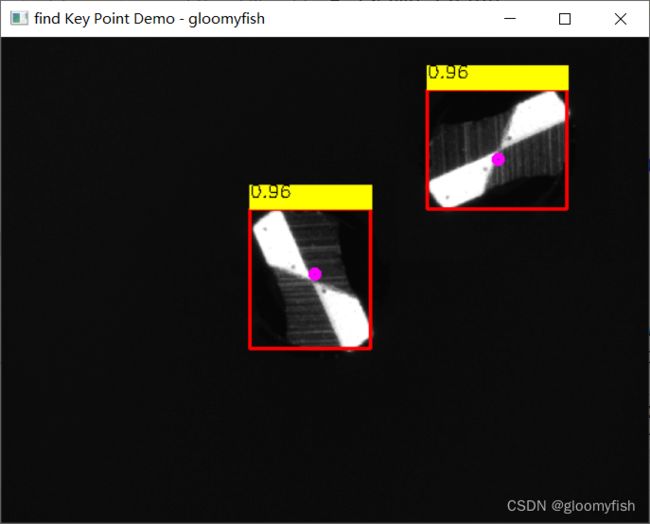
ORT相关的推理演示代码如下:
def ort_keypoint_demo():
# initialize the onnxruntime session by loading model in CUDA support
model_dir = "lines_pts_best.onnx"
session = onnxruntime.InferenceSession(model_dir, providers=['CUDAExecutionProvider'])
# 就改这里, 把RTSP的地址配到这边就好啦,然后直接运行,其它任何地方都不准改!
# 切记把 onnx文件放到跟这个python文件同一个文件夹中!
frame = cv.imread("D:/bird_test/back1/lines_002.png")
bgr = format_yolov8(frame)
fh, fw, fc = frame.shape
start = time.time()
image = cv.dnn.blobFromImage(bgr, 1 / 255.0, (640, 640), swapRB=True, crop=False)
# onnxruntime inference
ort_inputs = {session.get_inputs()[0].name: image}
res = session.run(None, ort_inputs)[0]
# matrix transpose from 1x8x8400 => 8400x8
out_prob = np.squeeze(res, 0).T
result_kypts, confidences, boxes = wrap_detection(bgr, out_prob)
for (kpts, confidence, box) in zip(result_kypts, confidences, boxes):
cv.rectangle(frame, box, (0, 0, 255), 2)
cv.rectangle(frame, (box[0], box[1] - 20), (box[0] + box[2], box[1]), (0, 255, 255), -1)
cv.putText(frame, ("%.2f" % confidence), (box[0], box[1] - 10), cv.FONT_HERSHEY_SIMPLEX, .5, (0, 0, 0))
cx = kpts[0]
cy = kpts[1]
cv.circle(frame, (int(cx), int(cy)), 3, (255, 0, 255), 4, 8, 0)
cv.imshow("Find Key Point Demo", frame)
cv.waitKey(0)
cv.destroyAllWindows()
if __name__ == "__main__":
ort_keypoint_demo()
认真学习 YOLOv8 点这里。