tensorflow2实现resnet50并用来分类猫狗
一、首先实现resnet50
具体可以参考这篇文章
import warnings
warnings.filterwarnings("ignore")
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
from tensorflow.keras.layers import (Conv2D,MaxPool2D,Input,ZeroPadding2D,
Add,AveragePooling2D,Dense,Flatten,BatchNormalization,
)
from tensorflow.keras.models import Model
def conv_block(inputs,block_id:str,filter_num,stride=1):
""" 从conv3_x开始,第1个1*1卷积需要下采样 """
if (block_id[0]!='1' and block_id[2]=='1'):
stride = 2
bottle_conv1 = Conv2D(filter_num,1,stride,activation='relu',name="block"+block_id+"_conv1")(inputs)
bottle_conv1 = BatchNormalization()(bottle_conv1)
bottle_conv2 = Conv2D(filter_num,3,1,activation='relu',name="block"+block_id+"_conv2")(bottle_conv1)
bottle_conv2 = BatchNormalization()(bottle_conv2)
bottle_conv3 = Conv2D(filter_num*4,1,1,activation='relu',name="block"+block_id+"_conv3")(bottle_conv2)
bottle_conv3 = BatchNormalization()(bottle_conv3)
bottle_conv3_pad = ZeroPadding2D((1,1),name="block"+block_id+"_conv3Pad")(bottle_conv3)
""" 从conv3_x开始,第1个1*1卷积需要下采样与输出进行堆叠 """
inputs_conv = Conv2D(filter_num*4,1,stride,activation='relu',name='block'+block_id+"_conv4")(inputs)
inputs_conv = BatchNormalization()(inputs_conv)
# print(block_id,bottle_conv3.shape,inputs_conv.shape)
bottle_out = Add()([bottle_conv3_pad,inputs_conv])
return bottle_out
def RESNET50(input_shape=(224,224,3),num_classes=1000):
inputs = Input(shape=input_shape)
inputsPad = ZeroPadding2D((3,3))(inputs) # 多出
conv1 = Conv2D(64,7,2,activation='relu',name='conv1')(inputsPad)
conv1 = BatchNormalization()(conv1)
conv2_x_1 = MaxPool2D((3,3),2,padding='same',name='conv2_x_maxpooling')(conv1) # 注意padding
print('conv2_x start...')
filter_nums0 = 64
BLOCK1_out = conv2_x_1
for i in range(1,4):
BLOCK1_out = conv_block(BLOCK1_out,f"1_{i}",filter_nums0)
print('conv2_x done!')
print(BLOCK1_out.shape)
print('conv3_x start...')
filter_nums1 = 128
# remind downsampling
BLOCK2_out = BLOCK1_out
for i in range(1,5):
BLOCK2_out = conv_block(BLOCK2_out,f"2_{i}",filter_nums1)
print('conv3_x done!')
print(BLOCK2_out.shape)
print('conv4_x start...')
filter_num2 = 256
# remind downsampling
BLOCK3_out = BLOCK2_out
for i in range(1,7):
BLOCK3_out = conv_block(BLOCK3_out,f"3_{i}",filter_num2)
print('conv4_x done!')
print(BLOCK3_out.shape)
print('conv5_x start...')
filter_num3 = 512
# remind downsampling
BLOCK4_out = BLOCK3_out
for i in range(1,4):
BLOCK4_out = conv_block(BLOCK4_out,f"4_{i}",filter_num3)
print('conv5_x done!')
print(BLOCK4_out.shape)
avgPooling = AveragePooling2D(BLOCK4_out.shape[1],name='average_pool')(BLOCK4_out)
x = Flatten()(avgPooling)
outlayer = Dense(num_classes,activation='softmax',name='out_layer')(x)
print('out shape:',outlayer.shape)
model = Model(inputs=inputs,outputs=outlayer,name='resnet50-tf2')
# model.load_weights("resnet50_weights_tf_dim_ordering_tf_kernels.h5")
return model
# model = RESNET50(num_classes=2)
# model.summary()
# print(f"layer's length={len(model.layers)}")
# for i,layer in enumerate(model.layers):
# print(i,layer.name)
二、准备数据
如下面的图所示,将数据分成![]() 和
和![]() 文件夹,每个文件夹里面分成
文件夹,每个文件夹里面分成![]() 和
和![]()

三、写训练文件
细节都写在注释里了,有不懂的地方可以留言
from resnet50 import RESNET50
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import (ModelCheckpoint,TensorBoard)
import tensorflow as tf
import os
from tensorflow.keras.optimizers.schedules import ExponentialDecay
from tensorflow.keras.preprocessing.image import ImageDataGenerator
if __name__ == '__main__':
print('这条线以下是输出'.center(62,'-'))
model = RESNET50(num_classes=2) # cat,dog
INIT_LEARNING_RATE = 0.001
# 学习率指数衰减
learningRateDecay = ExponentialDecay(initial_learning_rate=INIT_LEARNING_RATE,
decay_steps=2000,decay_rate=0.96)
adam = Adam(learning_rate=learningRateDecay)
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['acc'])
# model.load_weights("logs/EP058_acc0.022-vac0.490.h5") 这个可以从断点处继续训练
""" 数据 """
bs = 30
train_dir = "datasets/train/"
val_dir = "datasets/test/"
train_datagen = ImageDataGenerator(rescale=1.0/255.0)
val_datagen = ImageDataGenerator(rescale=1.0/255.0)
train_generator = train_datagen.flow_from_directory(train_dir,batch_size=bs,
class_mode='categorical',
target_size=(224,224))
val_generator = val_datagen.flow_from_directory(val_dir,batch_size=bs,
class_mode='categorical',
target_size=(224,224))
# 设置checkpoint
logdir = 'logs/'
if not os.path.exists(logdir):
os.mkdir(logdir)
checkpoint_path = logdir + "EP{epoch:03d}_loss{loss:.3f}-valoss{val_loss:.3f}.h5"
checkpoint_dir = os.path.dirname(checkpoint_path)
cp_callback = ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,verbose=1)
# 设置tensorboard
tensorboard_callback = TensorBoard(log_dir=logdir, histogram_freq=1)
# 训练
epochs = 100
model.fit(train_generator,
validation_data=val_generator,
epochs=epochs,
callbacks=[cp_callback,tensorboard_callback])
print('输出完毕'.center(66,'-'))
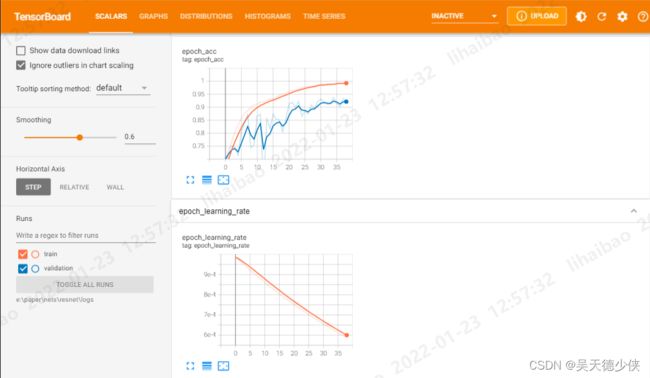
可以通过 tensorboard --logdir=logs --host=localhost 查看训练情况:
四、写预测文件
训练好的权重文件会保存在logs文件夹里面:
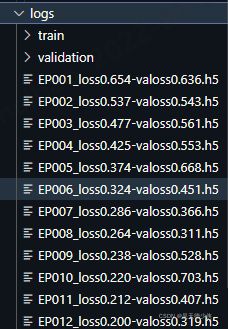
一般挑最后一个进行预测。其中注意要将传入预测的图片进行和训练时一样的预处理,具体包括:①reshape,②expand_dims,③归一化
from resnet50 import RESNET50
import cv2
import numpy as np
import time
import matplotlib.pyplot as plt
if __name__ == '__main__':
print('这条线以下是输出'.center(62,'-'))
classes_name = ['cat',"dog"]
input_shape = (224,224)
print('predict start...'.center(66,'-'))
model = RESNET50(num_classes=len(classes_name))
model.load_weights("logs/EP039_loss0.019-valoss0.295.h5")
print(f'load weights successfully!')
figure = plt.figure(figsize=(6,4),dpi=200)
for i,filename in enumerate(['testCat1.jpg','testCat2.jpg',
'testDog.jpg','testDog2.jpg']):
start = time.time()
inputs = cv2.imread(filename)
inputs = cv2.resize(inputs,input_shape).astype(np.float32)
inputs0 = np.array(inputs, dtype="float") / 255.0
inputs = np.expand_dims(inputs0,axis=0)
# print(inputs.shape)
# print(inputs)
outputs = model.predict(inputs)
print(outputs)
result_index = np.argmax(outputs)
result = classes_name[result_index]
print(f"图片是{result}")
print(f'花费时间{time.time()-start:.2f}s')
plt.subplot(2,2,i+1)
plt.title(result)
plt.axis('off')
plt.imshow(inputs0[...,::-1])
plt.show()
print('输出完毕'.center(66,'-'))我到网上下了2张猫和狗的图片进行测试:

最后将预测结果通过画图显示出来,以预测结果作为图像的title:
