使用mergekit 合并大型语言模型
模型合并是近年来兴起的一种新技术。它允许将多个模型合并成一个模型。这样做不仅可以保持质量,还可以获得额外的好处。
假设我们有几个模型:一个擅长解决数学问题,另一个擅长编写代码。在两种模型之间切换是一个很麻烦的问题,但是我们可以将它们组合起来,利用两者的优点。而且这种组合的方法可以不需要GPU来完成。

在本文中我们将介绍各种合并算法,研究如何实现它们,并深入研究它们的工作原理。还将使用mergekit工具合并Mistral、WizardMath和CodeLlama模型。
模型合并算法
有几种用于组合模型的算法。其中许多使用加权平均组合。但是在本文中,我将重点介绍一些更高级的算法,并将它们按复杂度递增的顺序排列。
1、Task Vector
这种方法引入了一种使用“Task Vector”修改神经网络行为的方法。这些向量表示预训练模型权重空间中的方向,可以表示在特定任务上改进的性能。
向量可以通过算术运算来计算,比如加法或者减法,从而允许在模型中进行有针对性的行为改变:
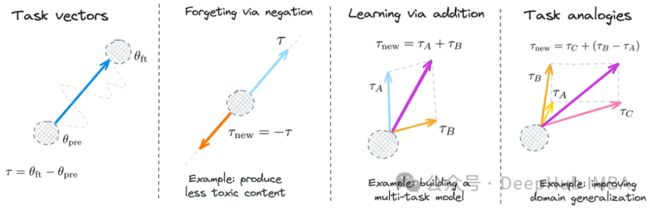
Task Vector提供了一种简单而有效的方法来编辑模型,从而实现性能改进、减少偏差和使用新信息更新模型。该方法已被证明可以很好地处理各种模型和任务。
基于Task Vector的模型编辑为控制和改进神经网络模型在各种任务中的性能提供了一种新颖而通用的方法。
论文地址:
https://arxiv.org/abs/2212.04089
2、SLERP
SLERP解决了传统加权平均方法在模型合并中的局限性。它提供了一种更细致的方法,以一种保留高维空间中每个父模型的独特特征和曲率的方式混合模型。
SLERP的优点如下:
平滑过渡:确保更平滑的参数过渡,在高维矢量插值至关重要。
特征保存:保持两个父模型的不同特征和曲率。
细致的混合:考虑矢量空间中的几何和旋转属性,从而产生准确反映两种模型特征的结果。
SLERP流程:
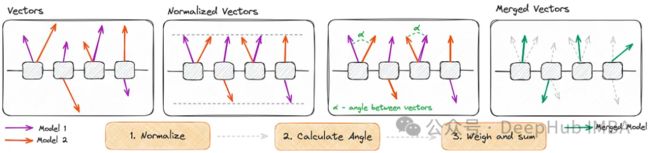
1、输入向量归一化为单位长度,关注方向而不是大小。
2、这些向量之间的角度是用它们的点积确定的。它根据插值因子和矢量之间的夹角计算尺度因子。
3将原始向量与这些因子加权并求和,得到插值向量。
SLERP能够以一种平滑地在参数之间转换的方式合并模型,并保留每个模型的独特特征,使其成为复杂模型合并任务的首选方法。尽管SLERP在同时合并两个模型方面很流行且有效,但它仅限于两两组合。
代码:
https://github.com/Digitous/LLM-SLERP-Merge
3、TIES
传统的模型合并在处理不同模型参数之间会获得不同的干扰。当合并多个模型时,这种干扰会导致性能的大幅下降。
为了克服这些挑战,TIES方法引入了三个步骤:
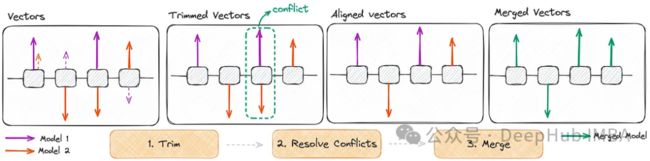
1、重置在微调期间只发生轻微变化的参数。这一步有助于减少冗余。
2、解决了由于不同模型的参数值符号不同而产生的冲突。
3、它只合并那些与最终商定的符号一致的参数。
ties - merge方法已被证明在各种设置下优于几种现有的merge方法。它有效地解决了干扰问题,特别是符号干扰,增强了合并模型的整体性能。
论文地址:
https://arxiv.org/abs/2306.01708
4、DARE
DARE不需要再训练或gpu。它主要关注于学习类似(同源)模型的参数,它使用与TIES类似的方法,但有两个主要区别:
Delta参数的修剪:通过将它们设置为零来识别和消除大多数Delta参数(微调和预训练参数之间的差异)。这个过程不会显著影响模型的功能。较大的模型可以较大比例丢弃这些参数。
重缩放权重:增加了一个重缩放步骤,其中调整模型的权重以保持输出期望大致不变。这可以将模型的“大”比例权重添加到具有比例因子的基本模型的权重中。
算法的工作步骤如下:
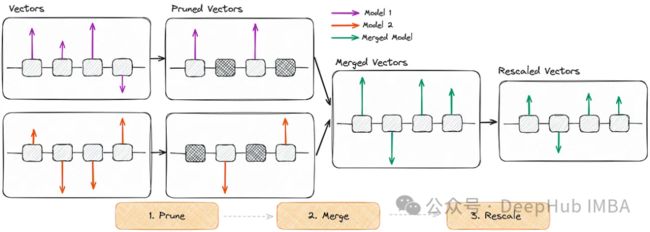
1、修剪将微调权重重置为原始预训练值,减少不必要的参数更改。
2、合并将多个模型中的参数进行平均,以创建一个统一的模型。
3、重新缩放调整合并模型的权重以保持其预期性能。
DARE提供了一种独特而有效的方法,通过修剪和重新缩放参数来合并语言模型,从而使模型具有增强和多样化的功能,而无需进行大量的再训练。
论文地址:
https://arxiv.org/abs/2311.03099
合并模型演示
我们将使用mergekit合并模型,这是一个为合并预训练的语言模型而设计的工具包。它支持上面我们介绍的所有算法,并且设置起来非常简单。模型合并可以只在一个CPU上运行,当然有GPU会更好。
安装:
python3 -m pip install --upgrade pip
git clone https://github.com/cg123/mergekit.git
cd mergekit && pip install -q -e .
我将下面三个模型进行混合:Mistral-7b, WizardMath-7b和CodeLlama-7b。这是yaml配置:
models:
- model: mistralai/Mistral-7B-v0.1 # no parameters necessary for base model
- model: WizardLM/WizardMath-7B-V1.0
parameters:
density: 0.5 # fraction of weights in differences from the base model to retain
weight: # weight gradient
- filter: mlp
value: 0.5
- value: 0
- model: codellama/CodeLlama-7b-Instruct-hf
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
int8_mask: true
dtype: float16
运行:
mergekit-yaml ultra_llm_merged.yaml output_folder \
--allow-crimes \ # Allow mixing architectures
--copy-tokenizer \ # Copy a tokenizer to the output
--out-shard-size 1B \ # Number of parameters per output shard
--low-cpu-memory \ # Store results and intermediate values on GPU. Useful if VRAM > RAM
--write-model-card \ # Output README.md containing details of the merge
--lazy-unpickle # Experimental lazy unpickler for lower memory usage
同时合并多个模型需要大量的资源。我们这个测试是在30个vcpu的系统,资源和时间如下:
下载模式:大约5分钟。
合并过程:大约7分钟。
峰值内存使用:30Gb。
这些时间和资源消耗可能会根据正在合并的特定模型而变化。
总结
我们介绍了合并模型几种算法的工作原理。并且使用mergekit来对三个LLM进行了简单的合并实验,我相信在不久的将来,我们将看到通过合并创建的模型越来越多。因为这是一种结合有用技能而不需要微调的经济有效的方法。
最后mergekit使用也非常简单,并且支持很多模型和不同的合并方法,需要更详细的信息可以看他的github
https://github.com/cg123/mergekit
https://avoid.overfit.cn/post/9b2b050b705e449395038aa8acabe388
作者:Sergei Savvov