基于多策略改进的蝠鲼觅食优化算法
文章目录
- 一、理论基础
-
- 1、MRFO算法
- 2、MSMRFO算法
-
- (1)半数均匀初始化
- (2)指数权重系数
- (3)分裂算子
- 二、函数测试与结果分析
- 三、参考文献
一、理论基础
1、MRFO算法
请参考这里。
2、MSMRFO算法
本文从三方面对MRFO算法做出了改进:
1)在种群初始化方面,提出了半数均匀初始化策略以提高种群多样性;
2)提出新的指数变化权重因子,使其更好地平衡全局搜索和局部开发;
3)分裂算子的引入在提高种群多样性的同时进一步提升算法收敛精度。
(1)半数均匀初始化
在个体初始化阶段,为避免随机生成的个体过于密集,提出了一种半数均匀初始化策略。种群中的前一半个体采用与MRFO算法相同的随机初始化方式,后一半个体在均数区间内进行初始化。设计原理是将搜索空间人为划分为 N / 2 N/2 N/2个新的搜索子空间,然后将对应个体的初始解在对应搜索子空间内进行随机初始化。这种初始化方式不仅保留了种群的随机性,而且可以避免初始化个体集中分布,有利于提高种群的多样性、搜索效率,并且可在一定程度上避免局部极值的出现。
半数初始化策略的数学模型为: { x i ( t ) = rand ( x l , x u ) x j ( t ) = rand ( x l + x u − x l N / 2 ( j − 1 ) , x l + x u − x l N / 2 j ) (1) \begin{dcases}x_i(t)=\text{rand}(x_l,x_u)\\x_j(t)=\text{rand}\left(x_l+\frac{x_u-x_l}{N/2}(j-1),x_l+\frac{x_u-x_l}{N/2}j\right)\end{dcases}\tag{1} ⎩⎨⎧xi(t)=rand(xl,xu)xj(t)=rand(xl+N/2xu−xl(j−1),xl+N/2xu−xlj)(1)其中, x u x_u xu、 x l x_l xl分别表示搜索空间的上下限; rand ( ) \text{rand}() rand()表示在限定空间内生成向量的随机函数; i = ( 1 , 2 , ⋯ , N / 2 ) i=(1,2,\cdots,N/2) i=(1,2,⋯,N/2)、 j = ( N / 2 + 1 , ⋯ , N ) j=(N/2+1,\cdots,N) j=(N/2+1,⋯,N); x i ( t ) x_i(t) xi(t)、 x j ( t ) x_j(t) xj(t)表示第 t t t次迭代时的种群内个体初始值。
(2)指数权重系数
在链式觅食阶段,MRFO算法在迭代寻优过程中的权重系数是在固定范围内随机生成的,导致算法的收敛速度因前后期的搜索步长相同而变慢。对此,提出了一种根据迭代次数指数变化的权重系数,有 r 1 = 1 − exp [ − ( 4 T − t t ) 2 ] (2) r_1=1-\exp^{\left[-\left(4\frac{T-t}{t}\right)^2\right]}\tag{2} r1=1−exp[−(4tT−t)2](2)其中, T T T为最大迭代次数, t t t为当前迭代次数。算法初期 r r r的值偏大,提供了较大的步长,加速了种群个体往最优解方向逼近;后期 r r r值变小,增强局部搜索能力,保证算法寻优性能。
(3)分裂算子
分裂算子包括分裂条件选取、分裂个体步长阈值设置和分裂策略的定义。实行的方案包括3个方面:
1)分裂条件。在MRFO算法中,翻筋斗觅食阶段前期的位置更新只对适应度优于当前最优适应度的个体进行位置更新,并未对适应度差的个体进行改变。因此,在翻筋斗觅食过程中有可能出现算法空翻的搜索范围处于固定区间,导致算法陷入局部最优。新的分裂条件为 f ( x i ( t + 1 ) ) > f ( x i ( b ) ) (3) f(x_i(t+1))>f(x_i(b))\tag{3} f(xi(t+1))>f(xi(b))(3)其中, f ( x i ( t + 1 ) ) f(x_i(t+1)) f(xi(t+1))表示经过链式或气旋觅食更新后位置的适应度, f ( x b ) f(x_b) f(xb)表示当前最优位置适应度。
2)分裂阈值。将所有个体的适应度进行排序,只有符合分裂条件的个体可进行分裂,分裂阈值为 D = { P i , j rand ( − 1 2 , 1 2 ) , P i , b ≥ C P i , j + rand ( − P i , j 2 , P i , j 2 ) , e l s e (4) D=\begin{dcases}P_{i,j}\text{rand}\left(-\frac12,\frac12\right),\quad\quad\quad\,\,\,\,\,\, P_{i,b}≥C\\P_{i,j}+\text{rand}\left(-\frac{P_{i,j}}{2},\frac{P_{i,j}}2\right),\quad else\end{dcases}\tag{4} D=⎩⎪⎪⎨⎪⎪⎧Pi,jrand(−21,21),Pi,b≥CPi,j+rand(−2Pi,j,2Pi,j),else(4)其中, P i , j P_{i,j} Pi,j表示个体 i i i和 j j j之间的距离, P i , b P_{i,b} Pi,b表示当前个体和最优个体之间的距离, C = exp − t / T C=\exp^{-t/T} C=exp−t/T表示一个根据迭代次数指数变化的阈值, rand ( − 1 / 2 , 1 / 2 ) \text{rand}(-1/2,1/2) rand(−1/2,1/2)和 rand ( − P i , j / 2 , P i , j / 2 ) \text{rand}(-P_{i,j}/2,P_{i,j}/2) rand(−Pi,j/2,Pi,j/2)是在 [ − 1 / 2 , 1 / 2 ] [-1/2,1/2] [−1/2,1/2]和 [ − P i , j / 2 , P i , j / 2 ] [-P_{i,j}/2,P_{i,j}/2] [−Pi,j/2,Pi,j/2]上均匀分布的随机数。
采用适应度的差值代表个体之间的距离.算法前期 P i , b P_{i,b} Pi,b较大,随迭代次数 t t t的增加,个体接近当前最优值后 P i , b P_{i,b} Pi,b减小,当 P i , b ≥ C P_{i,b}≥C Pi,b≥C时, D ∈ [ − P i , j / 2 , P i , j / 2 ] D\in[-P_{i,j}/2,P_{i,j}/2] D∈[−Pi,j/2,Pi,j/2]有助于个体进行全局搜索;反之 D ∈ [ P i , j / 2 , 3 P i , j / 2 ] D\in[P_{i,j}/2,3P_{i,j}/2] D∈[Pi,j/2,3Pi,j/2]有助于局部搜索。
3)分裂策略。为了提高种群的多样性和算法的寻优精度,通过下面分裂策略对符合分裂的个体进行分裂: x i ( t ) = t T x i ( t ) + ( 1 − t T ) x i ( t ) D (5) x_i(t)=\frac tTx_i(t)+\left(1-\frac tT\right)x_i(t)D\tag{5} xi(t)=Ttxi(t)+(1−Tt)xi(t)D(5)在寻优前期的个体位置主要由后一部分的分裂项决定,增加了种群的多样性,寻优后期主要由个体自身位置决定。
二、函数测试与结果分析
为了评估MSMRFO算法的表现,引入鲸鱼优化(WOA, whale optimization algorithm)算法、A-C双参数鲸鱼优化(ACWOA, A-C parametric whale optimization algorithm)算法、蝴蝶优化(BOA, butterfly optimization algorithm)算法、哈里斯鹰优化(HHO, Harris hawks optimization)算法进行了对比实验。为了保证测试的准确性和公平性,对比算法和MSMRFO算法除了改进的初始化方式、权重系数和加入的分裂算子处不相同外,实验环境和参数全部保持相同。实验中设置 T = 500 T=500 T=500、 N = 30 N=30 N=30、 d = 30 d=30 d=30,每个基准测试函数独立运行30求其平均值,以文献[1]中表1的7个测试函数为例。结果显示如下:
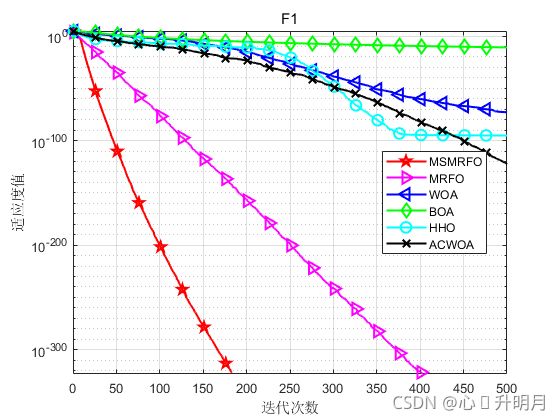
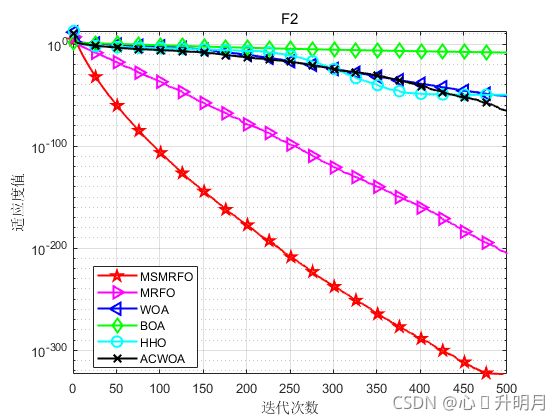
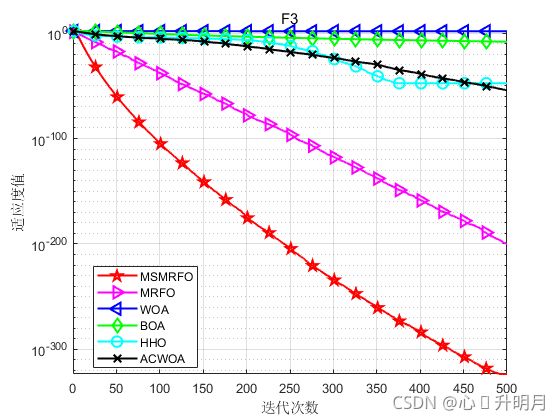
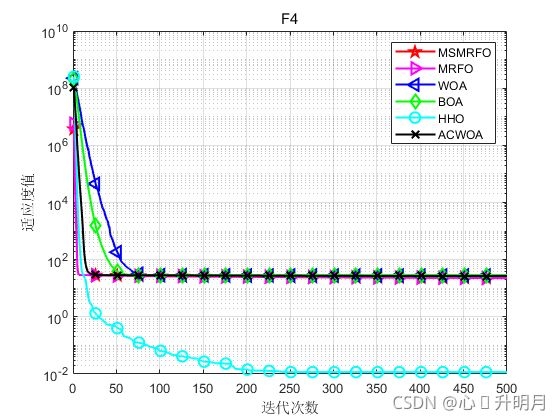


函数:F1
MSMRFO:最差值: 0,最优值:0,平均值:0,标准差:0
MRFO:最差值: 0,最优值:0,平均值:0,标准差:0
WOA:最差值: 1.7484e-72,最优值:2.2491e-88,平均值:1.0713e-73,标准差:4.0322e-73
BOA:最差值: 1.5031e-11,最优值:1.067e-11,平均值:1.2844e-11,标准差:9.8515e-13
HHO:最差值: 2.2759e-94,最优值:8.6641e-117,平均值:7.6303e-96,标准差:4.1544e-95
ACWOA:最差值: 6.1071e-122,最优值:2.2911e-144,平均值:2.0383e-123,标准差:1.115e-122
函数:F2
MSMRFO:最差值: 1.4822e-323,最优值:0,平均值:0,标准差:0
MRFO:最差值: 2.6713e-205,最优值:6.161e-217,平均值:1.7982e-206,标准差:0
WOA:最差值: 7.8615e-51,最优值:2.0219e-57,平均值:6.8955e-52,标准差:1.679e-51
BOA:最差值: 5.6282e-09,最优值:2.072e-09,平均值:4.5251e-09,标准差:1.238e-09
HHO:最差值: 4.7061e-49,最优值:9.3068e-60,平均值:1.8706e-50,标准差:8.5955e-50
ACWOA:最差值: 7.8446e-65,最优值:2.7735e-73,平均值:4.9817e-66,标准差:1.6391e-65
函数:F3
MSMRFO:最差值: 4.9407e-324,最优值:4.9407e-324,平均值:4.9407e-324,标准差:0
MRFO:最差值: 2.3572e-199,最优值:1.3296e-213,平均值:1.2548e-200,标准差:0
WOA:最差值: 86.6299,最优值:0.046693,平均值:47.6745,标准差:26.9541
BOA:最差值: 6.7626e-09,最优值:4.9834e-09,平均值:6.0803e-09,标准差:4.1985e-10
HHO:最差值: 7.2779e-47,最优值:1.3646e-55,平均值:2.4386e-48,标准差:1.3285e-47
ACWOA:最差值: 1.0935e-53,最优值:1.2015e-67,平均值:4.8658e-55,标准差:2.0544e-54
函数:F4
MSMRFO:最差值: 23.2073,最优值:21.5542,平均值:22.5896,标准差:0.4728
MRFO:最差值: 23.8562,最优值:22.0723,平均值:22.8197,标准差:0.4614
WOA:最差值: 28.7768,最优值:27.3589,平均值:27.9308,标准差:0.44714
BOA:最差值: 28.9754,最优值:28.8652,平均值:28.9364,标准差:0.031116
HHO:最差值: 0.07933,最优值:1.5752e-06,平均值:0.011608,标准差:0.01629
ACWOA:最差值: 27.0175,最优值:26.1812,平均值:26.7569,标准差:0.20067
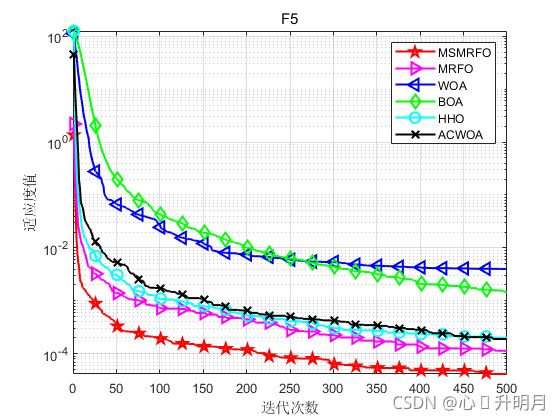
函数:F5
MSMRFO:最差值: 0.00029517,最优值:1.785e-06,平均值:4.1666e-05,标准差:6.0747e-05
MRFO:最差值: 0.0003713,最优值:6.0561e-06,平均值:0.000114,标准差:8.6578e-05
WOA:最差值: 0.015374,最优值:0.00011038,平均值:0.0040091,标准差:0.0034898
BOA:最差值: 0.002939,最优值:0.00039916,平均值:0.0014339,标准差:0.00063656
HHO:最差值: 0.0008135,最优值:3.2561e-06,平均值:0.00020148,标准差:0.00017825
ACWOA:最差值: 0.0012716,最优值:1.1796e-05,平均值:0.00018822,标准差:0.00024234
函数:F6
MSMRFO:最差值: -5901.3523,最优值:-5994.2862,平均值:-5952.6064,标准差:21.8483
MRFO:最差值: -1155.3912,最优值:-1790.3934,平均值:-1460.2387,标准差:135.3762
WOA:最差值: -1632.0633,最优值:-1909.0495,平均值:-1848.8072,标准差:105.5217
BOA:最差值: -1632.0633,最优值:-1632.0633,平均值:-1632.0633,标准差:2.3126e-13
HHO:最差值: -1908.9269,最优值:-1909.0495,平均值:-1909.0359,标准差:0.028267
ACWOA:最差值: -1908.0114,最优值:-1909.0495,平均值:-1908.8838,标准差:0.26901
函数:F7
MSMRFO:最差值: 2.9661,最优值:0.24972,平均值:2.7684,标准差:0.62609
MRFO:最差值: 2.9661,最优值:0.010987,平均值:2.6372,标准差:0.87619
WOA:最差值: 1.5324,最优值:0.18424,平均值:0.63343,标准差:0.30787
BOA:最差值: 3.0462,最优值:2.2964,平均值:2.8876,标准差:0.17672
HHO:最差值: 0.00031107,最优值:1.0283e-07,平均值:7.6689e-05,标准差:8.2285e-05
ACWOA:最差值: 0.50393,最优值:0.026039,平均值:0.11453,标准差:0.10235
实验结果表明:通过提出的初始化策略、权重因子更新策略和个体分裂策略可有效提高MRFO算法的收敛速度和寻优精度。
三、参考文献
[1] 刘永利, 朱亚孟, 晁浩. 多策略MRFO算法的卷积神经网络超参数优化[J]. 北京邮电大学学报, 2021, 44(6): 83-88+95.