提高RAG性能的高级查询转换
英文原文地址:Advanced Query Transformations to Improve RAG
Different approaches to query transformations
2024 年 1 月 10 日
检索增强生成已成为生成式人工智能文献中讨论最多的话题之一。每天都有大量的博客文章和科学论文涌入,要保持更新是很有挑战性的。然而,RAG 的流行是当之无愧的,因为没有其他解决方案能像它一样有效地减轻大型语言模型中的幻觉。
RAG通过可靠的外部来源(如维基百科页面、私人PDF等)增强语言模型的通用知识。因此,RAG最重要的步骤是确保我们的检索能够找到正确的文档供模型使用。
我们之所以如此需要 RAG,是因为我们目前在将完整文档放入上下文窗口时面临一些限制。原因包括模型输入的标记长度受限、计算成本的比例增加,以及像"中间丢失"等问题。"中间丢失"指的是模型难以使用长输入上下文中间信息的现象。
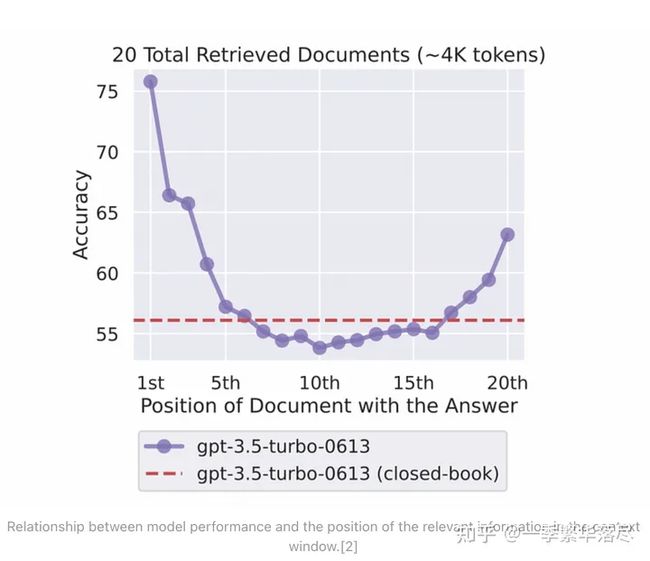
如果检索到的文档太长或不相关,俗话说,垃圾进,垃圾出。
增强 RAG 的技术有很多,这就带来了一个额外的挑战,即知道何时应用每一种技术。本文将分析查询转换的技术以及如何使用路由器根据输入提示选择适当的转换。
查询转换背后的理念是,检索器可能不会认为用户的初始提示与数据库中的相关文档特别相似。在这种情况下,我们可以先修改查询,提高其与信息源的相关性,然后再进行检索并将其输入语言模型。
我们将从一个简单的 RAG 应用程序开始,加载关于Nicolas Cage,The Best of Times (Nicolas Cage 首次参演的电视剧),和 Leonardo DiCaprio 的三个维基百科页面。
然后,我们将文档分割成 256 个字符的文本块,且没有重叠。这些文本块被嵌入和索引在一个矢量存储中,默认情况下,所有内容都存储在内存中,但如果需要持久性选项,有数十种可供选择。
默认情况下,所有内容都存储在内存中,但如果需要持久选项,也有几十种可供选择。
然后,我们将文档分割为256个字符的块,且没有重叠。这些块将被嵌入,使用向量存储。默认情况下所有内容都用向量存储。但如果您想要持久性选项,有数十种向量库可供选择。
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
pages = ['Nicolas_Cage', 'The_Best_of_Times_(1981_film)', 'Leonardo DiCaprio']
documents = loader.load_data(pages=pages, auto_suggest=False, redirect = False)
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
gpt3 = OpenAI(temperature=0, model="text-davinci-003")
embed_model = OpenAIEmbedding(model= OpenAIEmbeddingModelType.TEXT_EMBED_ADA_002)
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 256, chunk_overlap=0, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
retriever = index.as_retriever(similarity_top_k=3)
现在,我们必须确保模型只根据上下文做出回答,而不依赖于训练数据,即使它以前可能已经学会了答案。
# The response from original prompt
from llama_index.prompts import PromptTemplate
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
"Don't give an answer unless it is supported by the context above.\n"
)
qa_template = PromptTemplate(template)
我们将使用两个更复杂的查询来测试刚刚创建的 RAG 应用程序。让我们看看第一个。
问题 1 — “Who directed the pilot that marked the acting debut of Nicolas Cage?”(译:谁执导了 Nicolas Cage 的处女作?)
第一个具有挑战性的查询要求将多个信息链接起来:Nicolas Cage 的处女作和该影片的导演。提示中只提到了 Nicolas Cage ,而导演的名字却没有出现在任何地方。
由于模型不知道标志着 Nicolas Cage 首次亮相的电视节目 "The Best of Times" 的名称,因此无法从我们的文档中检索到相关细节。
question = "Who directed the pilot that marked the acting debut of Nicolas Cage?"
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
response = llm.complete(prompt)
print(str(response))

问题 2 — “Compare the education received by Nicolas Cage and Leonardo DiCaprio.”(译:比较 Nicolas Cage 和 Leonardo DiCaprio 所接受的教育。)
对于第二个查询,检索器只选择了与 Leonardo DiCaprio 教育相关的文本块。由于这些文本块与Nicolas Cage 无关,因此我们无法进行准确的比较。
question = "Compare the education received by Nicolas Cage and Leonardo DiCaprio."
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
response = llm.complete(prompt)
print(str(response))

让我们分析一些查询转换技术,看看在每种情况下哪种效果最好。
HyDE

Hypothetical Document Embeddings(HyDE,译:假设性文档嵌入)是一种生成文档嵌入以检索相关文档而无需实际训练数据的技术。首先,LLM 针对查询创建一个假设性答案。虽然该答案反映了与查询相关的模式,但这个答案包含的信息可能与事实不符。
接下来,查询和生成的答案都被嵌入。然后,系统会从预定义的数据库中识别并检索出在向量空间中与这些嵌入最接近的实际文档。

from llama_index.indices.query.query_transform import HyDEQueryTransform
from llama_index.query_engine.transform_query_engine import (
TransformQueryEngine,
)
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
query_engine = index.as_query_engine(similarity_top_k=3)
hyde = HyDEQueryTransform(include_original=True)
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
问题1:
response = hyde_query_engine.query("Who directed the pilot that marked the acting debut of Nicolas Cage?")
print(response)
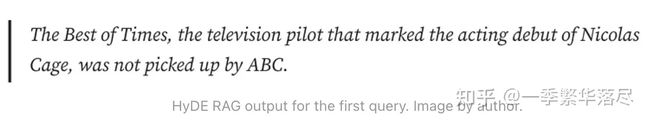
我们已经取得了部分进展——模型的答案仍然不正确,但已经接近正确答案。具体来说,它现在能够确定电视节目的名称("Best of Times")。让我们看看幻觉答案是什么样的。
query_bundle = hyde("Who directed the pilot that marked the acting debut of Nicolas Cage?")
hyde_doc = query_bundle.embedding_strs[0]
hyde_doc

尽管 Francis Coppola 并没有执导《The Best of Times》,但至少幻觉中包括了电影的名称。
问题 2
response = hyde_query_engine.query("Compare the education received by Nicolas Cage and Leonardo DiCaprio.")
print(response)

答案是正确的,因为幻觉的答案显著改善了输出。LLM 在训练数据中已经有关于演员教育的信息。
Sub Questions(子问题)
子问题技术采用分而治之的方法来处理复杂的问题。它首先分析问题并将其分解为更简单的子问题。每个子问题针对不同的相关文件,这些文件可以提供部分答案。
然后,引擎收集中间回复,并将所有部分结果合成最终回复。
# setup base query engine as tool
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="Sub-question query engine",
description="Questions about actors",
),
),
]
query_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools,
service_context=service_context,
use_async= False
)
问题 1


没有办法将这个问题分解成更简单的子问题,使其更容易回答。该模型试图生成一个子问题,但除了原始查询外,没有提供任何额外的上下文,从而将计算浪费在无效的转换上。
问题 2


这次,生成子问题非常有用,因为我们需要比较两个不同的信息--两个不同的人的教育背景。每个子问题都可以利用检索到的上下文独立回答。
Multi-Step Query Transformation (多步查询转换)
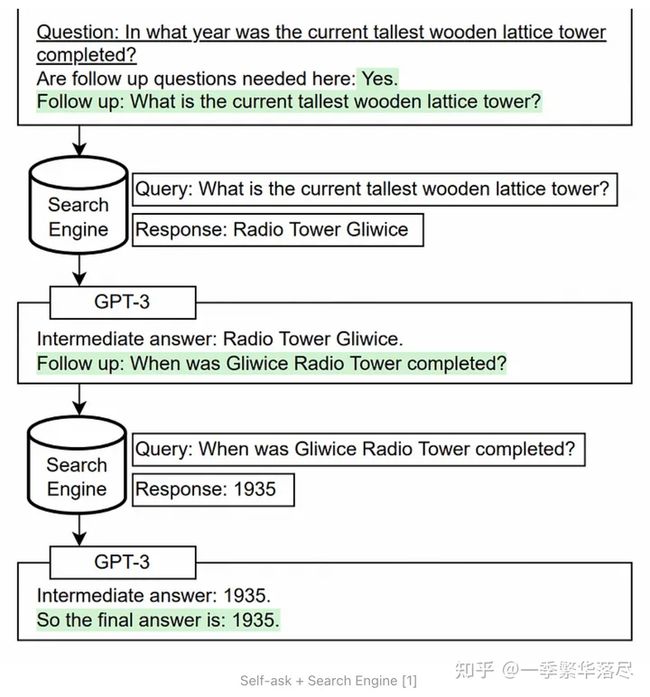
多步查询转换方法以自我提问法为基础,即语言模型在回答原始问题之前向自己提出并回答后续问题。这有助于模型将其在预训练期间分别学到的事实和见解结合起来。
原始论文表明,LLMs 往往无法将两个事实组合在一起,即使它们知道每个独立的事实。例如,一个模型可能知道事实 A 和事实 B,但却无法推导出 A 和 B 在一起的蕴涵。
自我提问法旨在克服这一局限性。测试时,我们只需向模型提供提示和问题。然后,它就会自动生成任何必要的后续问题,将事实联系起来,组成推理步骤,并决定何时停止[1]。
query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform_gpt3,
index_summary=index_summary
)
问题 1

这是我们第一次得到这个问题的正确答案!让我们看看中间的问题。

第一个子问题的结果如下:

在确定了节目名称之后,第二个小问题现在具体询问导演的情况:

这种多步骤方法有助于模型建立在前一个问题的额外背景之上,并引导我们找到正确答案。
问题 2


在这种情况下,多步查询方法也很有用。我们认为,对于第二个查询,之前的子问题技术更适合,因为它可以并行处理。这些问题是独立的,不需要相互叠加。但多步查询方法也很有用。
RouterQueryEngine
事实证明,每种查询转换都适用于不同的情况。对于可以分解成更简单子问题的问题,如比较 Nicolas Cage 和 Leonardo DiCaprio 的学历,子问题分解最有效。
多步转换最适合需要反复探索上下文的查询,如连接多个信息面。
简单的查询可能根本不需要任何转换,应用转换会浪费资源。
为了在所有这些情况中做出选择,我们可以使用路由器查询引擎(RouterQueryEngine)——我们为 LLM 提供了一系列查询转换工具,让它根据输入提示来决定应用哪种最佳工具。
query_engine = RouterQueryEngine(
selector=PydanticSingleSelector.from_defaults(),
query_engine_tools=[
simple_tool,
multi_step_tool,
sub_question_tool,
],
)
我们创建了一个路由器,允许根据每个独特查询的需要,在无转换、子问题分解或多步转换之间进行选择。让我们来看看路由器是如何决定采取哪种方法的。
首先,我们将选择一个非常简单的问题,不需要任何转换。
response_1 = query_engine.query("What is Nicolas Cage's profession?")

路由器认为该查询相对简单,因此做出了正确的选择。由于该问题直接询问有关 Nicolas Cage 职业的单一事实,因此无需进行查询转换来分解或扩展该问题。
response_2 = query_engine.query("Compare the education received by Nicolas Cage and Leonardo DiCaprio.")
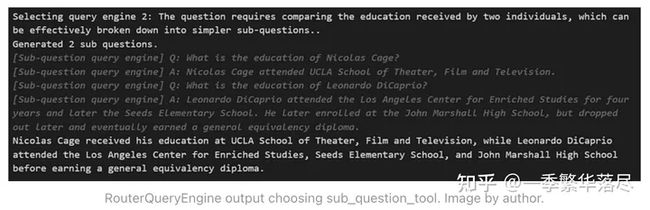
为了回答一个比较性问题,路由器准确地将其拆分为每个独立的更简单的子问题。
response_3 = query_engine.query("Who directed the pilot that marked the acting debut of Nicolas Cage?")

对于第三个查询,路由器认识到,要正确回答问题,需要将多个上下文信息联系起来,具体来说,需要识别标志着 Cage 演艺处女作的电影,然后确定谁执导了该电影。
结论
正如我们所探索的那样,通过高级查询转换增强 RAG 可以显著提高模型性能。
虽然查询转换只是改进检索的众多技术之一,但它显示了将检索与 LLM 固有的推理能力相结合的定制分析的潜力和需求。
完整代码可参考:https://github.com/partycia/query_transformations
参考
[1] Measuring and Narrowing the Compositionality Gap in Language Models
[2] Lost in the Middle: How Language Models Use Long Contexts
[3] Precise Zero-Shot Dense Retrieval without Relevance Labels