LLM排行榜更新!谷歌Bard超过GPT-4,中国玩家未进前十
今天谷歌Bard的排名在Imsys的LLMs 排位赛上超过了GPT-4,直接跃居第二名(但没有超过OpenAI最新的 GPT-4 Turbo模型):
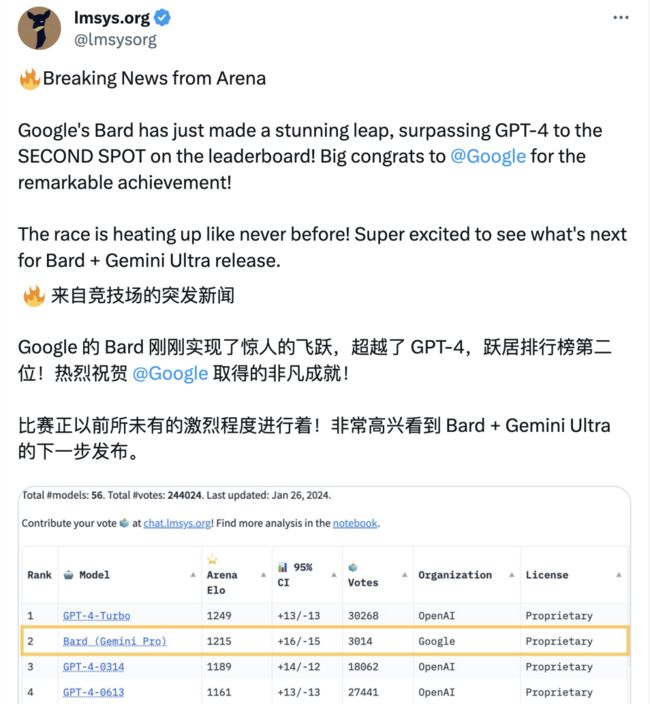
遇到这好事,谷歌首席科学家 Jeff Dean 当然是第一时间前来“炫耀”,并给自家的 Gemini Pro模型带货。

排行榜介绍
这个LLMs 排行榜(Chatbot Arena基准平台)是由 UC伯克利研究人员主导的LMSYS (Large Model Systems Organization)组织发起的。通过在LLMs 间进行随机匿名的 1V1 battle 方式,并基于 Elo 评级系统得出排名。
如下图所示,你可以随便问一个问题,左侧是模型A的回答,右侧是模型B的回答。然后你可以给这两个模型的回答打分,一共有四个选项「A更好;B更好;A和B一样好;A和B一样差」,如果一轮聊天判断不出来,你可以继续聊天,直到选出你认为更好的,但如果在聊天过程中暴露了大模型的身份,则投票将不被计算在内。

下图显示了模型A在对战模型B时获胜几率(不包含平局 )的比例分布图:

下图显示了每种模型组合的battle次数(无平局))

下图显示了单个模型相对于所有其他模型的平均胜率:

OpenAI霸榜,中国玩家未进前十
下图是该榜单目前排名的 Top 10,可以看出GPT-系列模型还是占据绝对优势的(前四名中占据了其三),而 Anthropic旗下的 Claude 系列模型则是在前十中占据了三席。号称是欧洲版OpenAI的 Mistral公司,这次也有两个模型进入前十。

另外请看上图最右侧一列,排名 Top 10的模型中,有9家都是闭源的私有模型,这说明开源模型还是有一段路要走。
遗憾的是中国玩家的大语言模型没有进入前十。
其中排名最高的是李开复创业公司零一万物旗下的 Yi-34B-Chat模型,位居13名。

其次是阿里旗下的 通义千问 Qwen-14B-chat模型,排名36:

再之后是清华教授唐杰创业公司智谱AI旗下的ChatGLM系列模型:
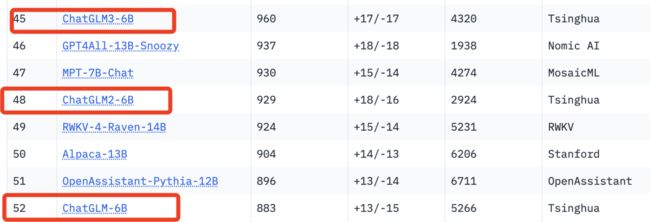
需要说明三点:
1、有很多中国大厂研发的模型可能没有参与到该榜单排名;
2、该榜单是面向全球公众的,所以选择用英文来聊天的用户要远比中文多,这可能对中国玩家研发的大语言模型不利;

3、该榜单仅仅统计了20w用户的随机提问和聊天,代表了用户和LLMs聊天的真实评价,但由于用户的提问和专业程度参差不齐,所以评价具有一定的主观性。
最后我们说回谷歌,在裁员和科学家离职创业的内忧外患之际(详情请移步谷歌危机大爆发!科学家纷纷离职创业、员工裁员不断...),谷歌24年究竟能不能完成“帝国反击战”呢?
让我们拭目以待吧!