python+keras如何自行简单搭建一个神经网路实现水果分类识别
1.引言
本文利用机器学习keras框架搭建简单的网络,通过训练实现对水果的自动识别和分类。首先,我们采集了苹果、香蕉、葡萄、橙子和梨等五种水果的图像,并对其进行分类。随后,我们按照7:3的比例将图像分割为训练集和测试集,并对每张图片及其类别进行编码处理。然后,我们使用keras框架搭建神经网络进行训练,以实现对水果的自动识别。最后也有相关的指标分析。
现在已经可以用很多成熟的神经网路结构很简单地去做分类任务了,但是大家也可以自己动手尝试编写代码、搭建网络结构,这样可以帮助大家更好地学习。
2.相关介绍
2.1 keras
本文采用Keras搭建神经网路。Keras是一个高级神经网络API,用于构建和训练深度学习模型。它是一个基于Python的开源库,可以在TensorFlow、CNTK或Theano等深度学习框架上运行。Keras的设计理念是用户友好、模块化和可扩展的,使得构建神经网络模型变得简单快捷。它提供了丰富的功能和工具,使得用户可以轻松地构建各种类型的神经网络模型,包括卷积神经网络、循环神经网络、自编码器等。它还提供了丰富的预训练模型和各种优化器、损失函数等,方便用户快速构建和训练模型。此外,Keras的模块化设计使得用户可以方便地组合不同的层和模型,构建复杂的神经网络结构。同时,Keras还提供了丰富的工具和函数,用于数据预处理、模型评估和可视化等,使得用户可以更加方便地进行模型的训练和调试。
2.2 数据集(已上传至资源可供下载)
本研究所采用的水果数据集是通过在线搜索收集而来的。数据集的构建如表1所示。其中,训练集(Train)和测试集(Test)是从同一个数据集中按照7:3的比例划分而来。而Testreal则是另一个数据集,用于测试本模型的泛化性能。在数据集中,各类水果的图像数量相对均衡。每种水果的图片都存放在相应的文件夹下。相关的图像展示如图1所示。
为了确保数据集的多样性和代表性,我们从多个来源收集了水果图像,并对其进行了严格筛选和整理。在构建数据集的过程中,我们特别注意确保每个类别的样本数量均衡,以避免数据不平衡对模型训练和测试结果的影响。此外,为了验证模型的泛化能力,我们特意准备了另一个独立的测试数据集Testreal,以更全面地评估模型在未知数据上的表现。
在图像的选择和整理过程中,我们力求保证图像的质量和多样性,以确保模型能够对不同种类和不同外观的水果进行准确识别。我们相信这样的数据集构建能够为本研究的实验结果提供可靠的基础,同时也为未来相关研究提供了具有挑战性和实用性的数据资源。
表1数据集构造
| 数据集 |
苹果 |
香蕉 |
葡萄 |
橙子 |
梨 |
| Train |
234 |
222 |
219 |
249 |
246 |
| Test |
97 |
100 |
101 |
105 |
108 |
| Testreal |
88 |
93 |
89 |
86 |
77 |

图1 数据集图片
2.3 机器学习指标介绍
当评估机器学习模型时,精确率、召回率、F1分数、混淆矩阵、PR曲线、AP、mAP是常用的评估指标。本文采用了这些指标来评估模型,接下来分别对它们简单介绍一下:
(1)精确率(Precision):精确率是指分类器预测为正例的样本中,确实为正例的比例。它的计算公式为:精确率 = 真正例 / (真正例 + 假正例)。精确率的高值表示分类器将正例标签预测正确的能力较强。
(2)召回率(Recall):召回率是指实际为正例的样本中,被分类器预测为正例的比例。它的计算公式为:召回率 = 真正例 / (真正例 + 假负例)。召回率的高值表示分类器将正例样本正确识别的能力较强。
(3)F1分数(F1-score):F1分数是精确率和召回率的调和平均值,它综合了精确率和召回率的性能。F1分数的计算公式为:F1 = 2 * (精确率 * 召回率) / (精确率 + 召回率)。F1分数的高值表示分类器在精确率和召回率之间取得了平衡。
(4)混淆矩阵(Confusion Matrix):混淆矩阵是一种用于评估分类模型性能的矩阵,它展示了模型在不同类别上的预测结果。混淆矩阵以实际类别和预测类别为坐标轴,将样本分为真正例、假正例、真负例和假负例四个部分,可以直观地反映分类器的性能。
(5)PR曲线(Precision-Recall Curve):PR曲线是用于评估二分类模型性能的曲线,横轴为召回率,纵轴为精确率。PR曲线展示了在不同阈值下精确率和召回率的变化情况,能够帮助用户选择合适的阈值来平衡精确率和召回率。
(6)AP(Average Precision):AP是用于评估目标检测模型性能的指标,它是PR曲线下的面积,表示为在不同召回率下的平均精确率。AP值越高,说明模型在不同召回率下的平均精确率越高,即模型的性能越好。
(7)mAP(mean Average Precision):mAP是多类别目标检测任务中常用的评估指标,它是所有类别AP值的平均值。在多类别目标检测任务中,每个类别都有一个AP值,mAP是这些AP值的平均值,用于综合评估模型的性能。
3. 模型设计
3.1 模型搭建训练
本文是在pycharm平台上利用keras2.4.3和tensorflow2.3.0进行训练的。总共训练了20个epochs,采用Adam优化,学习率为0.001。由于是多分类任务,所以我采用的损失函数为交叉熵损失函数categorical_crossentropy。训练过程如下图2所示。

图2 训练过程
最终在训练集上的loss值为0.0784,训练集准确率为0.9769,实际上在第19个epochs时才是最好的一次。
模型结构信息如下图3所示。第一层为3*3卷积,卷积核个数为8,激活函数为relu。第二层为2*2最大池化。第三层是16个卷积核的3*3卷积而后第四层再接一个2*2最大池化,第五层为dropout层,本文在实验过程发现dropout放在这个位置效果最好。第六层为flatten层,将多维输入一维化,过渡到全连接层。第七层为dense层,神经元个数为8。最后第八层为dense+softmax激活函数进行输出。
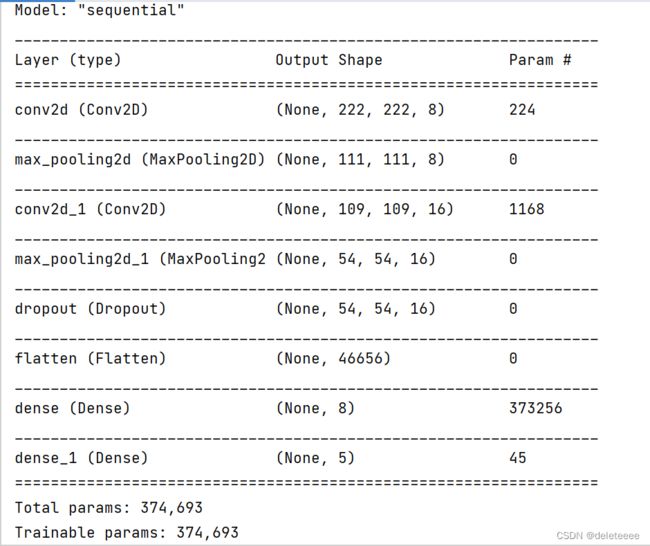
图3 模型结构
将模型的网络结构可视化结果如下图4所示。

图4 模型可视化
3.2 模型性能评估
接下来,我们将对已经训练好的模型进行测试评估。首先,我们将对测试集Test进行测试。图5展示了分类混淆矩阵,其中纵坐标表示真实类别,横坐标表示预测类别。从混淆矩阵中可以看出,橙子的预测效果最好,而苹果和梨的预测效果最差,有一半以上的预测结果是错误的。这也对模型的准确率产生了很大的影响。考虑到本模型较小,而训练集数据量较大,可能会出现训练集过拟合的情况,从而导致测试集效果较差。因此,后续我们需要重新评估数据集的选择,并思考在未来的模型训练中采取缓解过拟合的策略。此外,我们还需要对测试集效果较差的原因进行全面的调查,以制定可能的纠正措施。
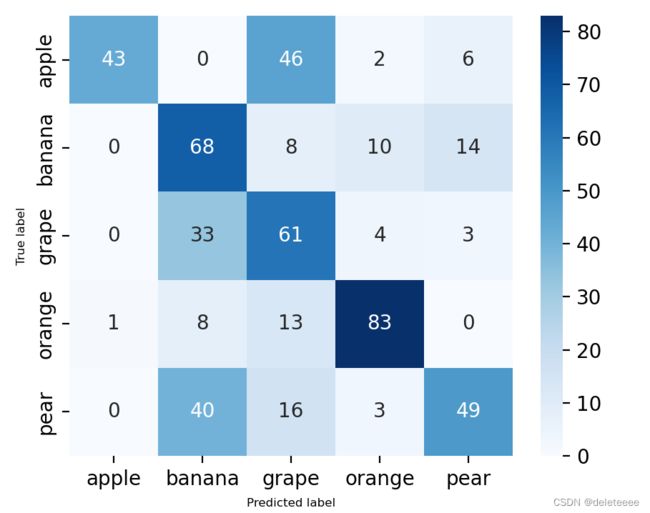
图5 混淆矩阵
在图6中,展示了PR曲线,其中包括每一类水果的PR曲线以及对应的平均精度(AP)值和总的平均精度(mAP)值。此外,每一类的AP值比较结果可以在表2中找到。橙子的AP值同样是最高的,但出人意料的是,苹果和梨的AP值也不低,这可能与在Python中用于计算多分类精度的算法有一定的关联。最终得到的mAP值为0.6,表明模型效果仍然可以接受。
PR曲线和AP值的结果为我们提供了关于每个类别在模型中的表现的详细信息。这些结果可以帮助我们更好地理解模型在不同类别上的性能,并为进一步优化模型提供了有价值的见解。此外,对AP值的比较还可以帮助我们确定模型在不同类别上的表现差异,进而指导我们制定针对性的改进策略,并为未来的研究和实践提供有益的指导。

图6 PR曲线
表2 Test数据集不同水果AP值比较
| 指标 |
苹果 |
香蕉 |
葡萄 |
橙子 |
梨 |
| AP |
0.80 |
0.51 |
0.56 |
0.88 |
0.63 |
| mAP |
0.60 |
||||
为了探究模型的泛化性能,本文对于Testreal数据集进行测试。测试后同样得到混淆矩阵如下图7所示。可以发现依然是苹果和梨的分类错误最多。

图7 Testreal混淆矩阵
图8展示了对应的PR曲线,我们可以观察到曲线的趋势都发生了变化。同时,表3中列出了各类水果的AP值比较结果。值得注意的是,葡萄的AP值呈现了明显的增长成为了最高,而苹果的AP值依然保持较高水平。最终,mAP值增长到了0.68。这表明本文所提出的模型具有较好的泛化性能,能够适应不同的数据集。
进一步分析显示,在不同数据集上进行测试,PR曲线的变化为我们提供了有关模型在不同类别上性能变化的重要信息。AP值的增长和降低也表明了模型在不同类别上的性能提升,这为我们提供了改进模型的方向和策略。

图8 testreal数据集测试PR曲线
表3 Testreal数据集不同水果AP值比较
| 指标 |
苹果 |
香蕉 |
葡萄 |
橙子 |
梨 |
| AP |
0.79 |
0.57 |
0.83 |
0.81 |
0.50 |
| mAP |
0.68 |
||||
最后,我们将模型在两个数据集上的测试结果进行了综合性能指标比较,具体数据见表4。我们发现模型在Testreal数据集上的测试结果反而表现更佳,各项指标均有显著提升。这表明了本模型具有较强的泛化能力,能够在不同的数据集上保持良好的性能。
为了更全面地评估模型的泛化性能,我们对不同数据集上的测试结果进行了深入比较和分析。通过对比不同数据集上的性能表现,我们得出结论:本模型不仅在训练集和测试集上表现出色,而且在未知的Testreal数据集上也能够取得令人满意的结果。这为模型在实际应用中的鲁棒性和可靠性提供了有力支持,同时也证实了我们所提出的水果识别模型具有较强的泛化能力。这一发现将进一步推动嵌入式机器学习在水果识别领域的应用,并为相关领域的研究和实践提供有益的参考。
表4 Test和Testreal测试性能指标对比
| 数据集 |
精确率 |
召回率 |
F1-score |
准确率 |
mAP |
| Test |
0.670 |
0.594 |
0.600 |
0.595 |
0.60 |
| Testreal |
0.679 |
0.642 |
0.634 |
0.647 |
0.68 |
4.代码
完整模型搭建训练代码以及性能评估代码在主页资源中下载
5. 该模型可以部署至嵌入式端,后续会有介绍
希望大家多多支持!!!