jnu第一大混子的训练纪录3:基础图论和基础数论
Part 1 :图论
(接训练纪录2 part 3)
图的着色问题
泛指把图的相邻顶点染成不同颜色的问题,没有深究,以简单题为例:洛谷2819
#include
#include
#include
#include
#include
#include
#include
#include 数据较小,用邻接矩阵保存了,然后对每个点dfs搜索并填色判断,如果dfs到了n,说明所有点都填上了色,答案;就可以++了
给我自己的提示:注意回溯
最短路问题
图论中最基础的问题,涉及多种算法
1.单源最短路问题(bellman-ford算法,spfa算法)
单源指固定起点,求到其他点的最短路,为了简便将终点也固定的问题归到这里来。
算法原理参考:csdn
需要注意的是这个算法可以解决带负权的图
代码参考:
#include
#include
#include
#include
#include
#include
#include
#include 这个代码含有比较初级的bellman-ford算法和负圈判断。
bellman-ford的队列优化-spfa算法
不同于dijkstra算法优化当d[i]不是最短距离的时候,spfa算法着眼于d[j]在一个循环中没有发生变化的时候,对最短路径发生变化的点进行松弛操作即可。使用了队列来维护这些点
struct Edge{
int v;//每条边的终点
int w;//每条边的权重
int next;//这条边的上一条边的编号(同一个起点)
}ed[Max];
int head[Max]={0};//head[u]表示以u作为起点的最后一条边的编号
int cnt=0;//边的编号
void add(int u,int v,int w) {//起点,终点,权重
cnt++;//注意从1开始
ed[cnt].v=v;//同上文
ed[cnt].w=w;
ed[cnt].next=head[u];
head[u]=cnt;
}
//-----------------
int dis[Max];
int in[Max];
bool vis[Max];//以vis纪录是否在队列中
bool spfa(int n,int s){
memset(vis,false,sizeof(vis));//记录此点是否在队列中
memset(in,0,sizeof(in));//记录此点入队次数
memset(dis,inf,sizeof(dis));//从初始点到当前点的最短路
dis[s]=0;//除了自己,即起点赋值为0
queueq;
q.push(s);//1号点入列
in[s]=1;
vis[s]=true;
while(!q.empty()){
int u=q.front();//对以出队列的点为弧尾的边对应的弧头顶点做松弛操作,即以1为起点的边
q.pop();
vis[u]=false;
for(int i=head[u];i!=-1;i=ed[i].next){//遍历与此点连接的边
int v=ed[i].v;
if (dis[v]>dis[u]+ed[i].w){//判断是否可以借助当前边缩短距离
dis[v]=dis[u]+ed[i].w;
if(!vis[v]){//如果被松弛后且不在队列中,需要加入队列
q.push(v);
vis[v]=true;
in[v]++;
if(in[v]>n)//如果此点进入队列大于n次 说明有负环
return false;
}
}
}
}
return true;
} 较详细的原理参考:csdn
2.单源最短路问题2(dijkstra算法):
前提:图没有负边。
对于bellman-ford算法中,用一下等式来松弛点的距离:
d[j]=min{ d[i] + 从i到j的cost | e=(j,i) ∈ E }
当d[i]不是最短距离的时候,这一步就是无效的,显然很浪费时间。因此考虑修改算法:
1.找到最短距离确定的点,从它更新相邻点的最短距离
2.此后不用关心1中已经确定了最短距离的点。
那么问题的关键就是如何找到已经确定最短距离的顶点,显然是要从起点出发,找到一个离起点最短且没用过的点,然后对这个点松弛一次找到下一个最短的点,这样可以保证每次找到的点一定是最短的(不会有其他路径到这个点并且更短),具体可以画一个简单松弛一次的图想一下。同时由于没有负边,这个最短距离不会因为负边的存在而再次缩短。因此可以实现找到最短路的目的(同时说明不能存在负边)这里可以画一个松弛两次的图想一下。
int cost[Max][Max];//不存在设为inf
int d[Max];
bool use[Max];
int V;//顶点数
void dij(int s){
fill(d,d+V,inf);
fill(used,used+V,false);
d[s]=0;
while(true){
int v=-1;
//从尚未使用过的顶点中选择一个距离最小的顶点
for(int u=0;udij的队列优化:因为每次都要枚举顶点来查找下一个距离最小的顶点,因此考虑使用堆来维护这些点。
struct edge{
int to,cost;
};
typedef pair P;//最短距离与顶点编号
int V;
vector G[Max];//邻接表
int d[Max];
void dij(int s){
priority_queue,greater > que;
fill(d,d+V,inf);
d[s]=0;
que.push(P(0,s));
while(!que.empty()){
P p=que.top(); que.pop();
int v=p.second;
if(d[v]d[v]+e.cost){
d[e.to]=d[v]+e.cost;
que.push(P(d[e.to],e.to));
}
}
}
}
3.任意两点之间的最短路问题(floyd算法)
核心思想是dp,记只使用0到k顶点的情况下i点到j点的最短路:d[k+1][i][j],状态转移方程:
d[k][i][j]=min( d[k-1][i][j],d[k-1][i][k]+d[k-1][k][j]),同样可以使用一维数组
复杂度为O(V^3),可以处理边有负路的情况。而判断负路只需要检查是否有d[i][i]<0即可
优点是实现简单,可储存负数,缺点是复杂度高,在复杂度可承受的范围下是不错的选择
多来点好懂的
int d[Max][Max];//d[i][i]=0,不存在时为inf
int V;
void floyd(){
for(int k=0;k4.路径还原
顾名思义,要求最短路径怎么走。以dijkstra算法为例,因为d[u] = min( d[u] , d[v]+ cost[v][u]),那么更新时使用一个prev[u]数组纪录最短路上顶点u的前驱,每次式更新时同时更新pre[u]=v即可。以上提到的三种路径都可以类似还原
for(int u=0;u要求s到顶点t的路径,不断求prev[t]即可,不过注意求出来的是t到s,记得反转
最小生成树
生成树的概念:给定一个无向图,如果它某个子图中任意两个顶点都互相连通并且是一棵树,那么这棵树就是生成树
而最小生成树就是在边上有权值的话,使边权和最小的生成树(MST,minimum spanning tree)
有点抽象,给个例子:有n个村庄,为了在村庄间通行,要建最少n-1条路,那么村庄和点就组成了生成树,而使得修建费用最小的生成树就是最小生成树(费用即边权值)
很明显是否存在生成树的前提是图是否为连通图,为了叙述方便假定图是连通的。下面叙述求最小生成树的方法。
1.Prim算法
与dijkstra算法十分类似:从某点出发,不断添加边。
算法思路:假设有一颗只包含顶点v的树T,然后选取T和其他顶点之间相连的最小权值,并把它加入到T中,不断操作就可以得到一棵最小生成树。
对于算法思路的证明:
假设已经求得的生成树的顶点集合:X(属于V),并存在V上的最小生成树使得T是它的子图
设连接X和V \ X(剔除X的部分)的权值最小的一条边为e
·如果e在这颗最小生成树上,思路得证
·如果e不在这颗最小生成树上,则一定存在一条边连接着X和V \ X,记为f,f在最小生成树上
最小生成树本质上是一棵树,如果把e也加入的话会形成一个圈。现在把f删除,加上e形成一个新的生成树,而根据e的定义,这颗树的总权值不会超过f连接的最小生成树,思路得证
其他问题:如何得到X和其他顶点相连的边的最小权值:把X和顶点v连接的边的最小权值记为mincost[v],添加新顶点u时,只需要利用u连接的边进行更新即可。容易证明这样得到的mincost是树与顶点相连的最小权值
复杂度为v^2。
int cost[Max][Max];//不存在设为inf
int mincost[Max];
bool use[Max];
int V;//顶点数
int prim(){
for(int i=0;i2.kruskal算法
类似于prim算法,不过prim加的是点,kruskal加的是边,以边的权值从小到大,以不产生圈为前提加入到生成树中去。证明这个算法正确的思路与prim证明类似。
对于判断不产生圈的思路是:如果边e的两个顶点u,v不在同一个连通分支中,那么加入e就不会产生圈,反之就会产生。判断u,v是否在同一组里面,就请出我们高效的并查集了(代码略)
int par[Max];
int ranK[Max];
void init(int n)
int find(int x)
void unite(int x,int y)
bool same(int x,int y)
struct edge{
int u,v,cost;
};
bool cmp(edge e1,edge e2){
return e1.cost练题环节
poj3255
次短路模板,给出两种算法:
1.对起点和终点跑两边最短路(较快的spfa),然后枚举每条边,设这条边为e,起点终点是u,v
则如果d1[u]+w[u,v]+d2[v]=最短路,则跳过,否则以ans=min(ans,d1[u]+w[u,v]+d2[v])进行更新,这里不给代码了
2.基于dijkstra的优化算法,在队列中同时保存每个点的次短和最短距离,同时对最短距离和次短距离进行更新,代码如下:
#include
#include
#include
#include
#include
#include
#include
#include 可以作为次短路模板
poj3723
求最大权森林,可以将权值取负转化为求最小生成树问题。
#include
#include
#include
#include
#include
#include
#include
#include 注意prim算法不加修改无法解决给出的图不连通的问题,而kruskal算法核心在于使用并查集检查图,如果存在多个连通子图则在各自的图中形成集合(有共同父亲),还可以对并查集检查有多少连通子图。另外存值的时候取负就可以不加修改的求出最大连通子图(负的最多就是最大嘛)
poj3169
题目有点长,给出链接3169
题目的分析涉及到一个叫差分约束系统的知识点:
差分约束系统
差分约束系统,是求解关于一组变数的特殊不等式组之方法。如果一个系统由n个变量和m个约束条件组成,其中每个约束条件形如xj-xi<=bk(i,j∈[1,n],k∈[1,m]),则称其为差分约束系统。即,差分约束系统是求解关于一组变量的特殊不等式组的方法。
通俗一点地说,差分约束系统就是一些不等式的组,而我们的目标是通过给定的约束不等式组求出最大值或者最小值或者差分约束系统是否有解。
差分约束系统的求解可以转化为图论,请看一下证明:(引用)
B-A<=c ①
C-B<=a ②
C-A<=b ③
①+②与③比较:即C-A ≤min( b,a+c)
对应到图论,对于x-y<=z,即从y到x拉一条权值为z的路。
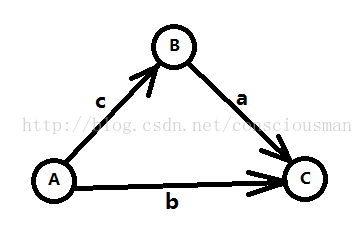
求a-c最大路即从a到c的最短路,求a-c最大路即从a到c的最长路。(最大路可以通过取负转化为最最小路,跟上一个题一样的思路)
最后可能存在正负环需要判断,即对应题目的不同输出
简化于csdn
太强了!
回到题目,根据题意整理出一下不等式:
d[i] - d[i+1] <=0
d[B] - d[A] <= D (最长)
d[B] - d[A] <= -D (最短)
然后连图就可以了
#include
#include
#include
#include
#include
#include
#include
#include 图论暂时告一段落,进入同样难顶的数论。。
顺便放一个邻接表的模板以供参考
//cout<4 (3,4):五号边,权重14
//-----------------------------
for(int i=1;i<=5;i++){
cout< Part 2:数论
1.辗转相除法
1.辗转相除法求最大公约数(又叫欧几里得算法)
最大公约数简称gcd
引例:给定平面坐标上两点,求在线段上有有多少个点(除给定的两点)
法1:检查以两个点围起来的矩形内所有的点,复杂度高(O(长×宽))
法2:答案即两点之间长和宽的最大公约数-1(都等于0时要特判答案为0),证明很简单,即以给出的斜边上的点和点之间作直角三角形,例如1,11和5,3之间可以作四个高为2,宽为1的三角形。而三角形的边一定是整数,因此长和宽的最大公约数-1就是三角形个数。
辗转相除法:
int gcd(int a,int b){
if(b==0)
return a;
return gcd(b,a%b);
}非常简单,需要证明gcd(a,b)=gcd(a,a%b),证明略^ ^
粗略估计复杂度为O(log(Max(a,b)));相当 搞笑 高效
小学生都知道的最小公倍数:lcm(a,b)=a*b/gcd(a,b)
2.扩展的欧几里得算法
扩欧简称ex(t)gcd
引例:
双六:有一个前后无限延伸的格子,即-∞......,-4,-3,-2,-1,0,1,2,3,4,.....∞,0是起点,1是终点,有一个骰子上有a,b,-a,-b四个整数,问掷出四个整数各几次可以到达终点?
人话翻译:求整数x,y使得 ax + by = 1成立。显然,如果gcd(a,b)≠ 1,则无解,反之可以通过扩展辗转相除法来求解。在这个问题的解继续扩展给出以下定义:
如果a和b都是整数,则ax+by是a和b的线性组合,其中数x和y是整数,对于给定的正整数 a
,b,方程 ax+by=c 有解的充要条件为 c 是 gcd(a, b) 的整数倍。
int exgcd(int a,int b,int &x,int &y){
if(b==0){
x=1;
y=0;
return a;
}
int ans;
ans=exgcd(b,a%b,x,y);
int r;
r=x;
x=y;
y=r-(a/b)*y;
return ans;
}求出的返回值是gcd(a,b)
且:
求出的x是方程ax+by=gcd(a,b)的解,x*(c/gcd)才是ax+by=c的解,同理y=y*(c/gcd);
求出x,y后求的通解:x=x+kx*n,y=y+ky*n(kx=b/gcd,ky=-a/gcd)
求出x后再求x的最小非负整数解式子:cout<<(x%(b/d)+b/d)%(b/d),d=gcd
具体证明从略,数论长篇大论的证明太多了
有关素数的算法
素数的定义就不多说了,注意1不是素数
1.素数测试
即给一个数,判断是不是素数。
法1:枚举,检查小于n的数是否能整除n。但是要聪明的枚举。假设d是n的约数,则n/d也是n的约数。d与n/d有不等式:min (d,n/d) ≤ n,所以只需要枚举2到根号n即可。复杂度O(n^1/2),大多数情况下已经足够了。以下同时还给出整数分解(即n等于几个m相乘),约数枚举(枚举n的约数)的方法,时间复杂度都相同
bool is_prime(int n){
for(int i=2;i*i<=n;i++){
if(n%i==0)
return false;
}
return n!=1;//1不是素数
}
//约数枚举
vector divisor(int n){
vector res;
for(int i=1;i*i<=n;i++){
if(n%i==0){
res.push_back(i);
if(i!=n/i)
res.push_back(n/i);
}
return res;
}
}
//整数分解
map prime_factor(int n){
map res;
for(int i=2;i*i<=n;i++){
while(n%i==0){
res[i]++;
n/=i;
}
}
if(n!=1)
res[n]=1;
return res;
} 法2:Rabin-Miller 素数测试
csdn暂时超出了我的理解范围,先放着
2.埃氏筛法
算法目的是枚举n内所有素数
原理很简单,先写下2到n中所有的整数,再把表中没删除过的,最小的数的所有倍数(除了自己)删去,重复步骤就能得到n以内的素数。
bool isprime[Max];//纪录每个数是否为素数,1既不是因数也不是素数
void solve(int n){
memset(isprime,true,sizeof(isprime));
for(int i=2;i*i<=n;i++)
if(isprime[i])
for(int j=i*i;j<=n;j+=i)
isprime[j]=false;
}稍作修改就可以得到总数和所有素数的和
复杂度基本可以看作线性的(O(nloglog n))
3.区间筛法
指得到区间[a,b)之间的素数
是埃氏筛法的小变种,因为b以内的合数的最小质因子一定不会超过 根号b ,那么使用埃氏筛法在[2,b^1/2 ] 筛得素数的同时把这个素数的倍数从[a,b)中划去,就能得到区间素数了。这里涉及到一个素因式分解的唯一性定理,即任何大于等于1的数都可以表示为素数的乘积,即每个数都拥有质因子。
题外话,表示区间的时候用左闭右开比较方便。
#include
#include
#include
#include
#include
#include
#include
#include (a+i-1)/i)意思是i为比a大的第一个数至少是i的多少倍
2ll是把2转换成长整型,惭愧c预言没学好
顺便放一个质因子分解的模板
#include
#include
#include
#include
#include
#include
#include
#include 模运算
1.为什么要取模:
在程序竞赛中,如果计算结果超出了64位整数的范围,就可能要求结果对某值取模。作为c++用户,就需要靠自己解决,其他算法如java有专门计算大数的类。
2.基本的模运算
(mod m)表示同时取模 ,a ≡ b(mod m)表示a和b对m取模结果相同, 设 a ≡ c (mod m),b ≡ d (mod m) 则有以下式子成立:
a+b ≡ c+d (mod m)
a-b ≡ c-d (mod m)
a*b ≡ c*d (mod m)
当a为负数时,在某些编译器里取模后是负数,为了保证0 ≤ a mod m ≤ m,可以将a%m改成a%m+m。
在取模运算中,可以看出加减乘可以随意计算,但除法不行,对除法有个特殊的例子,
若 a*c ≡ b*c (mod m),c≠0 则 a ≡ b ( mod m/gcd(c,m) )
另还有幂运算:a ≡ b (mod m),那么 a^n ≡ b^n (mod m)
快速幂运算
ll pow(ll x,ll n,ll mod){//快速求a^b,同时对mod取余
ll res=1;
x=x%mod;
while(n>0){
if(n&1)
res=(res*x)%mod;
x=(x*x)%mod;
n>>=1;
}
return res;
}算法解释:当n为偶数(n&1==0),x^n=( (x^2) ^(n/2) ),递归为n/2的状态,当n为奇数时, x^n=( (x^2) ^(n/2) )*x,则先乘x再操作。类似于折半查找,复杂度为 O(log n)
组合数运算
先看一下组合数运算的基础模板:
int cb(int n, int m){
int ans=1;
for(int i=n;i>=(n-m+1);i--)
ans*=i;
while(m)
ans/=m--;
return ans;
}利用了C(n,m)=C(n−1,m)+C(n−1,m−1)的性质,复杂度为 O(n^2),较高
如何优化呢,利用组合数的定理:C(n,m)= n ! / m ! ( n − m ) ! ,预先在O(n)的复杂度内预处理出所有阶乘,就可以用O(1)的时间算出组合数了。但是有个问题,阶乘是非常大的,20!差不多就能爆longlong,所以需要取模(一般求组合数的题都会求结果对某数取模),而前面我们知道了除法是不能直接取模的,怎么办呢?使用乘法逆元,除以一个数等于乘以这个数的逆元,证明不会
乘法逆元
对于一个整数a,如果a ∗ b ≡ 1 ( mod p ),则在模p 的意义下:
a是b的逆元,b是a的逆元。但此条件成立的前提是a,p 互质,即gcd(a,p)=1
不做证明。太菜不感兴趣
怎么求乘法逆元?又来个费马小定理
费马小定理
如果a和p互质,则有:a^(p-1) ≡ 1(mod p)
现作等式变换
a^(p-1) ≡ 1(mod p)
a*a^(p-2) ≡ 1(mod p)
那么就可以用快速幂求逆元了。
以上是对逆元的浅层理解,仅为了运算组合数。
#include
#include
#include
#include
#include
#include
#include
#include 另外还有中国剩余定理和欧拉函数等知识,先缓一下
练题放在下一次博客,有好多题呢。。