ClickHouse分析效率翻倍提升,揭秘奇点云对归因分析场景的优化实践

「在100万用户、1亿事件量数据的性能测试中,效率提升超220%。」
奇点云DataKun是大数据集群管理系统,负责企业大数据底层存算及运维,对接并管理离线、实时、图、时序等不同引擎,确保数据能得到高效处理和分析。
因此,DataKun技术团队的日常工作除了不断打磨产品功能、提升产品性能,也持续关注各开源社区对存算引擎的更新迭代,并自主优化核心引擎,以降低上层数据应用对底层技术的使用难度,满足各种业务场景的进阶需要。
例如,对ClickHouse在用户行为的归因分析、漏斗分析、留存分析等场景表现,DataKun技术团队已完成诸多优化。
本文将聚焦归因分析场景,分享ClickHouse of DataKun的优化实践。
(一)“归因分析”对ClickHouse的三大挑战
简单理解归因分析:从用户“点击”到“提交订单/支付”,借助数据拆解各运营位的“贡献”,找到与购买行为关联度高的环节,以便及时调整投放及运营策略。在归因分析中,“点击”被称为“触点事件”,“提交订单/支付”被称为“目标事件”。
常见的归因分析模型包括“首次触点归因”、“末次触点归因”、“线性归因”、“位置归因”等等。

企业进行归因分析流程
以使用GrowingIO-增长分析(UBA)进行分析为例
伴随企业积累的用户数据增长、归因分析日益精细,底层数据技术的实现也随之面临着更高难度挑战:
1、海量数据处理的性能挑战
单个用户的行为数据是有时序的。在用户规模较大的情况下,随着回溯期和归因窗口期拉长,需要计算的数据量将呈指数级增长。
然而,使用SQL对大规模数据集进行分析,耗时过长;分析维度不固定,也就无法做预计算,不能减轻即席查询的压力。
2、支持交互式分析的易用性挑战
归因分析常常需要从多维度进行分析,在分析过程中进行动态调整和探索,来深入研判不同因素对业务指标的影响。
而如果按照传统思路实现归因分析,假设触点事件和目标事件各有十几个维度,加上“直接转化”参与计算、维度对比等条件,归因分析的计算逻辑就已经复杂到无法用SQL实现。
3、归因模型的拓展性挑战
当要构建更灵活甚至定制化的归因模型,就需要使用更复杂的统计方法、机器学习模型或其他算法,超出了标准SQL的能力范围。
应对上述挑战,目前业内最适宜的引擎是ClickHouse(为支撑点击流数据分析而生),但“还不够”。日趋碎片化的用户行为、不断增长的数据规模、持续迭代的分析模型,要求ClickHouse具备更高性能——支持海量数据高效查询,架构高可用;具备易用性——支持动态组合任意维度、任意指标,呈现即席查询的分析结果;具备扩展性——支持更灵活、简便地添加新影响因素,或调整算法。
(二)编写Attribution函数,提效超220%
基于ClickHouse的UDF(User Defined Function,用户自定义函数)特性,DataKun团队编写了“Attribution函数”(直译为归因函数),高效实现复杂的归因计算。
- Attribution函数的设计思路
- 对触点事件和目标事件进行过滤和排序,形成每个用户的事件序列。
- 扫描事件序列,对触点事件进行条件判定和标记。其中,目标事件归因窗口期内的触点事件,标记为有效触点事件;若归因窗口期内没有触点事件,则标记目标事件为直接转化。
- 计算有效触点事件在归因模型下的贡献值。

Attribution函数定义(简化版)
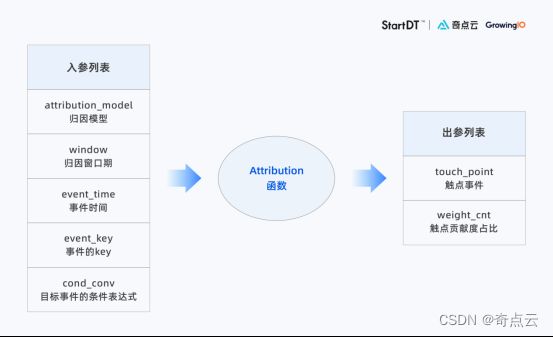
Attribution函数定义(简化版图示)
以电商场景为例,当需要测算点击、评论等站内行为对用户成交的贡献度时,进行归因分析的SQL如下:
在SQL中引用Attribution函数,并传入Attribution函数需要的参数,即返回贡献度。

代码片段部分截图(篇幅有限,未完全展现)
- 基于Attribution函数方案的实践效果
DataKun技术团队构建了100万用户、1亿事件量的数据用于性能测试。使用ClickBench多次测试后,结果表明,归因分析场景下,基于Attribution函数的方案相较传统的标准SQL实现,提效超220%。

性能测试结果
相比ClickHouse提供的方案(调用Script来实现UDF),Attribution函数没有进程调用的开销,性能更为优秀;
相比开发者手写SQL,必须分别实现不同模型(例如前文介绍的“首次触点归因”、“末次触点归因”、“线性归因”等等)的逻辑,Attribution函数只需要设置触点事件、目标事件,选择不同计算模型即可,易用性更强;
此外,在ClickHouse UDF体系下,开发者还可以基于Attribution函数拓展更多自定义的归因模型,且函数输出结果统一,无需修改对接逻辑。
目前,GrowingIO增长分析(UBA,用户行为分析产品)就调用了ClickHouse of DataKun,基于性能更好、易用性和扩展性更强的Attribution函数,高效满足归因分析场景所需。
(三)更适合企业级规模化数据分析的
ClickHouse of DataKun
除了本文介绍针对归因分析场景编写的Attribution函数,DataKun技术团队还对流批一体、个性化分析等场景进行了优化,形成ClickHouse of DataKun。
具体实践包括但不限于:
- 使用ClickHouse的MergeTree引擎,高效实现小文件合并,优化流批一体的处理场景,支持实时数据5秒内在各分析工具中可见。
- 编写漏斗分析、事件流分析等UDF,以优化多种个性化分析场景的技术实现,减少重复工作(拓展自定义UDF的原因与前文归因分析场景类似)。例如,基于事件流UDF,比基于ClickHouse标准SQL分析提效了500%。
- 通过Bitmap改写SQL,实现ClickHouse上的高效Join,让用户分析领域常见的“按人Join”效率更高。
奇点云与国内分析云领军者GrowingIO并购重组,并完成数据云和分析云的技术融合后,GrowingIO分析云产品的海量数据场景和极限业务要求为DataKun提供了完美的“高压测试”机会,也敦促DataKun团队持续深入ClickHouse等引擎的研究和优化。
企业客户可以直接通过SimbaOS Kernel,使用DataKun调用及管理ClickHouse of DataKun及其他各类引擎,享受经过“千锤百炼”的增强能力;无需自行部署或升级社区版本,通过DataKun即可完成扩容、管理及维护配置参数。
此外,相较分别对接社区版引擎并逐一进行自维护,DataKun提供大数据集群智能运维能力,更满足企业级客户对安全稳定、自主可控、运维成本可控、系统可观测性等需要,告别传统人肉运维,护航规模化“数据生产—消费”。

· 关于DataKun
大数据集群管理系统DataKun,具备安全稳定、智能运维、云原生、自主可控等特性,支持对接离线、实时、图、时序等不同类型引擎,为企业大数据存算及运维管理降本增效。
