二叉搜索树(BSTree)
文章目录
-
- BST性质
- BST实现
-
- BST类接口
- 构造函数
- 拷贝构造函数
- 赋值运算符重载
- 析构函数
- 插入元素
- 查找元素
- 删除元素
- 参考源码
- BST 的应用
-
- K模型
- KV模型
BST性质
二叉搜索树(Binary Search Tree,BST)是一种二叉树数据结构,也叫二叉排序树其中每个节点最多有两个子节点,通常称为左子树和右子树。二叉搜索树具有以下性质:
- 若左子树不为空,左子树所有结点的值都比根节点值小
- 若右子树不为空,右子树 所有结点的值都比根节点值大
- 根结点的左右子树也是二叉搜索树
比如下图是搜索二叉树

下图不是搜索二叉树(左子树值比根结点值大,不符合性质)

BST实现
实现BST,先构建一个结点类。结点需要三个成员变量,结点的值,左孩子和右孩子
template<class K>
struct BStreeNode
{
BStreeNode<K>* _left;//左孩子
BStreeNode<K>* _right;//右孩子
K _key;//结点值
//构造
BStree(const K& key = K())
:_left(nullptr)
, _right(nullptr)
, _key(key)
{}
};
BST类接口
template<class K>
class BSTree
{
typedef BStreeNode<K> Node;
public:
//构造
BSTree();
//拷贝构造
BSTree(const BSTree<K>& bst);
//赋值运算符
BSTree<K>& operator=(BSTree<K> t);
//析构
~BSTree();
//插入
void Insert(cosnt K& key);
//删除
void Erase(cosnt K& key);
//查找
Node* Find(cosnt K& key);
private:
Node _root;
};
构造函数
初始化一个空的BST
BSTree()
:_root(nullptr)
{}
拷贝构造函数
拷贝构造需要完成深拷贝,将现有的BST拷贝给一个新的BST即可,需要递归进行拷贝。而拷构造函数是成员函数
C++成员函数递归时,一般在套一层子函数进行递归

Node* _Copy(Node* root)
{
if (root == nullptr)
{
return nullptr;
}
Node* node_copy = new Node(root->_key);
node_copy->_left = _Copy(root->_left);//拷贝左子树
node_copy->_right = _Copy(root->_right);//拷贝右子树
return node_copy;
}
BSTree(const BSTree<K>& bst)
{
_root = _Copy(bst._root);
}
赋值运算符重载
- 赋值时,如果当前对象有内容,应该先删除当前对象
- 在完成深拷贝
//释放时要自底向上释放,否则找不到左右孩子结点了
void _Destoy(Node* root)
{
if (nullptr == root)
{
return;
}
_Destoy(root->_left);
_Destoy(root->_right);
delete root;
}
BSTree<K>& operator=(BSTree<K> t)
{
if (&t != this)//防止自己给自己赋值
{
_Destory(this->_root);//删除当前对象
_root = _Copy(t._root);
}
}
析构函数
自底向上依次删除,最后置空即可
~BSTree()
{
_Destory(_root);
_root = nullptr;
}
插入元素
插入时,可以分为以下两种情况:
- 空树:直接将待插入元素做为根节点
- 非空:根据二叉树得性质进一步细分情况
非空:
1. 待插入元素小于根节点的值。
将待插入元素插入到根节点左子树中,在根据其性质继续判断,当遇到叶子结点时,就可以确定插入元素最终的位置
比如对下面二叉搜索树插入0
- 0比根节点8小,需要将其插入到左子树中
- 0和左子树3比较,还是小,继续向3的左子树插入
- 0和左子树1比较,还是小,继续向1的左子树插入。此时1是叶子结点,也就确定了插入元素的最终位置。

2.待插入元素大于根节点的值
将待插入元素插入到根节点右子树中,在根据其性质继续判断,当遇到叶子结点时,就可以确定插入元素最终的位置
比如对下面二叉搜索树插入20
- 20比根节点大,需要将其插入到根节点右子树中。
- 20比右子树10大,需要将其插入到10的右子树中。
- 20比右子树14大,需要将20插入到14的右子树中。
- 20比右子树18大,需要将20插入到18的右子树中。此时18是叶子节点,也就确定了20最终插入的位置

- 待插入元素等于根节点的值
默认的二叉搜索树不允许数据冗余,当和根节点值相等时,则插入失败。如果和跟结点不相等,则继续判断。如果和树中任意一个结点的值相等,就不允许插入。
根据上述的思路,实现BST插入的代码如下
递归实现:
bool _Insert(Node* &root, const K& key)//注意 参数要传引用
{
//空树 or 叶子结点
if (root == nullptr)
{
root = new Node(key);
return true;
}
//非空
if (root->_key > key)//小于根节点
{
return _Insert(root->_left, key);
}
else if (root->_key < key)//大于根节点
{
return _Insert(root->_right, key);
}
else //等于根节点
{
return false;
}
}
//插入
bool Insert(const K& key)
{
return _Insert(_root, key);//调用子函数进行递归
}
非递归实现
bool Insert(const K& key)
{
//空树
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
//非空
Node* cur = _root;
Node* parent = nullptr;
while (cur != nullptr)
{
if (cur->_key > key)//小于插入到左树
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)//大于插入到右树
{
parent = cur;
cur = cur->_right;
}
else//相等插入失败
{
return false;
}
}
//经过上面的比较 以及确定插入的位置,下面申请结点进行连接
cur = new Node(key);
//根据BST性质确定插入到父结点的左边还是右边
if (parent->_key > key)
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;
}
查找元素
按照BST性质,比根节点大就去右子树进行查找,比根节点小,就去左子树中查找
递归实现:
//递归查找
Node* _Find(Node* root, const K& key)
{
if (root == nullptr)
return nullptr;
if (root->_key == key)
{
return root;
}
if(root->_key < key)
{
return _Find(root->_right, key);
}
else
{
return _Find(root->_left, key);
}
}
Node* Find(const K& key)
{
return _Find(_root, key);
}
非递归实现:
Node* Find(const K& key)
{
if (_root == nullptr)
{
return nullptr;
}
Node* cur = _root;
while (cur != nullptr)
{
if (cur->_key == key)
{
return cur;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
cur = cur->_right;
}
}
//无
return nullptr;
}
删除元素
删除结点之后,仍然需要这棵树保持二叉搜索树的特征。需要考虑多种情况。相对就很复杂。
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情况:
1. 要删除的结点是叶子结点(没有左孩子和右孩子)
比如删除下面树的1

对于叶子结点来说,可以直接删除,删除并不会影响二叉搜索树的性质
2. 要删除的结点只有左孩子结点
比如对下面这棵树删除14。
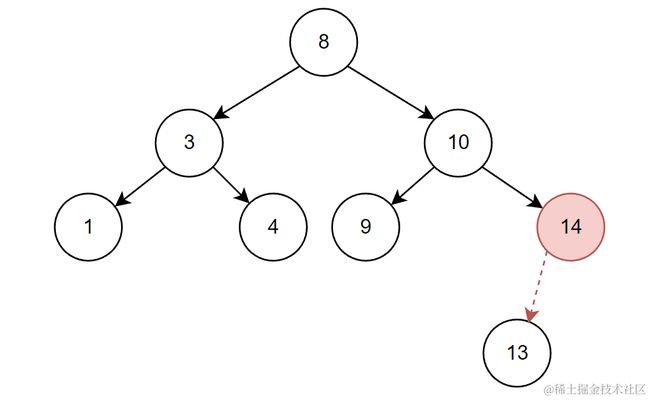
结点14只有左孩子,并不能直接删除。这种情况相对也比较好解决,可以直接将删除结点的左子树移动到父结点的位置上。这种方法也叫托孤法。将自己的左孩子结点托孤给自己的父结点。
删除后,如下
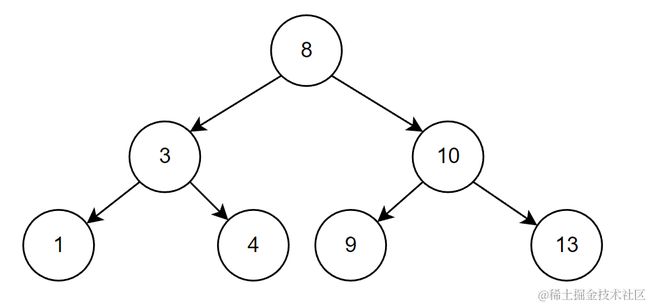
3. 要删除的结点只有右孩子结点
比如删除下图树中的3
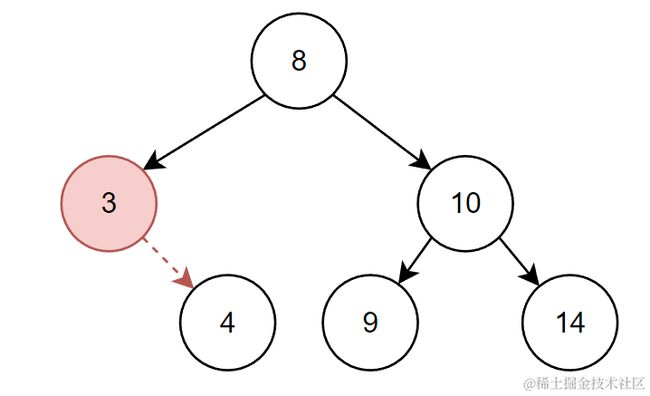
结点3只有右孩子,也不能直接删除。这里的解决方法也采用托孤法。直接将右子树移动到父结点的位置
删除后如下

4. 要删除的结点既有左孩子又有右孩子
比如删除10,既有左子树,又有右子树。甚至还有子孙节点。

解决这种情况,可以使用替换法进行删除。
可以将让待删除结点左子树当中值最大的结点,或是待删除结点右子树当中值最小的结点覆盖待删除结点进行删除
删除10。
右子树值最小节点为13。直接让13移动到10的位置进行覆盖删除即可。

总结: 可以将上面的第1种和第2、3种情况合并一下,删除节点是可以划分为三种情况。
- 删除该节点,使被删除的节点父结点指向被删除结点的左孩子结点。(直接删除)
- 删除该结点,使被删除结点的父节点指向被删除结点的右孩子结点。(直接删除)
- 替换法删除,在它的右子树中寻找值最小的结点进行覆盖删除
非递归实现:
bool Erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur != nullptr)
{
//确定要删除结点的位置以及父结点
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else//已经确定好位置,进行删除
{
if (cur->_left == nullptr)//左子树为空(直接删除)
{
//判断是否为根节点 对根节点进行特殊处理
if (cur == _root)
{
_root = _root->_right;
}
else if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
delete cur;
}
else if (cur->right == nullptr)//右子树为空(直接删除)
{
//判断是否为根节点
if (cur == _root)
{
_root = _root->_left;
}
else if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
delete cur;
}
else//左右都不为空(替换法删除)
{
//找到右子树最小结点替换
Node* minRight = cur->_right;
Node* pminRight = cur;
while (minRight->_left != nullptr)
{
pminRight = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key;
if (pminRight->_left == minRight)
{
pminRight->_left = minRight->_right;
}
else
{
pminRight->right = minRight->_right;
}
delete minRight;
}
return true;
}
}
return false;
}
递归法删除:
bool _Erase(Node* &root, const K& key)
{
if (root == nullptr)
{
reutrn false;
}
//确定删除位置
if (root->_key < key)
{
return _Erase(root->_right, key);
}
else if (root->_key > key)
{
return _Erase(root->_left, key);
}
else
{
//已经确定位置 进行删除
Node* del = root;
if (root->_right == nullptr)
{
root = root->_left;
}
else if (root->_left == nullptr)
{
root = root->_right;
}
else
{
Node* maxleft = root->_left;
while (maxleft->_right)
{
maxleft = maxleft->_right;
}
swap(root->_key, maxleft->_key);
return _EraseR(root->_left, key);
}
delete del;
return true;
}
}
bool Erase(const K& key)
{
return _Erase(_root, key);
}
参考源码
- gitee 二叉搜索树模拟实现
BST 的应用
BST主要应用在两个大模型下,分别是
- K模型
- KV模型
K模型
K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到值。
比如:给定一个单词,检查单词是否拼写正确
- 将词库中的所有单词作为key构建一颗二叉搜索树。
- 然后在这棵二叉搜索树中检索这个单词是否在这棵树上,在则拼写正确,不在则拼写错误。
K模型主要是判断在不在的场景
KV模型
KV模型即型:每一个关键码key,都有与之对应的值Value,即
比如:英汉词典就是英文与中文的对应关系。通过英文快速找到中文,英文单词与其对应的中文
在比如统计单词出现的次数,通过指定的单词快速找到出现的次数。单词与其对应出现的次数
将上述的二叉搜索树改造为KV模型
#pragma once
#include 主要就是修改结点类和插入函数构造新节点时将value也构造进去。其余都不用修改。
用简单的例子更好的认识KV 模型,
比如将英文翻译为中文
int main()
{
//简单模拟构建一个字典
BSTree<string, string> dict;
dict.Insert("string", "字符串");
dict.Insert("BST", "二叉搜索树");
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
//输入单词进行查找并翻译
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret != nullptr)
{
cout << str << ':' << ret->_value << endl;
}
else
{
cout << str << ':' << "无此单词" << endl;
}
}
return 0;
}
运行结果
在比如统计单词的个数
int main()
{
//统计下面字符串数组中每个字符串出现的次数
string arr[] = { "BST","string","insert","BST","erase","string","string","insert" };
BSTree<string, int> countTree;
//遍历arr统计单词个数
for (auto& e : arr)
{
auto ret = countTree.Find(e);
if (ret == nullptr)//不在BST中 第一次出现,插入,数量+1
{
countTree.Insert(e, 1);
}
else//在BST中,数量+1
{
ret->_value++;
}
}
//中序遍历打印结果
countTree.Inorder();
return 0;
}
运行结果:
