SF-Net: Single-Frame Supervision for Temporal Action Localization
SF-Net
- Abstract
- 1 Introduction
- 3 Proposed Method
-
- 3.1 Problem Definition
- 3.2 Framework
- 3.3 Pseudo Label Mining and Training Objectives
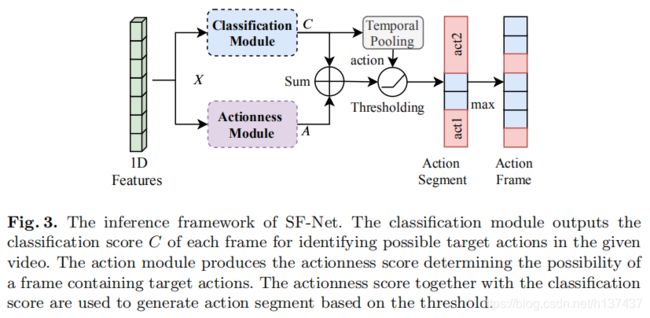
- 3.4 Inference
- Experiments
-
- Datasets
- Implementation Details
- Results
- Conclusion
备注: 机翻,如有侵权,立即删除
code: https://github.com/Flowerfan/SF-Net
source: ECCV2020
Abstract
在本文中,我们研究了一种中间形式的监督,即单帧监督,用于时间动作定位(TAL)。 为了获得单帧监督,注释器被要求只识别动作时间窗口内的单个帧。 这可以显著降低获得充分监督的人工成本,这需要对行动边界进行注释。 与仅注释视频级标签的弱监督相比,单帧监督引入了额外的时间动作信号,同时保持了较低的注释开销。 为了充分利用这种单帧监督,我们提出了一个统一的系统SF-Net。 首先,我们建议预测每个视频帧的动作得分。 随着典型的类别评分,动作评分可以提供关于潜在动作发生的全面信息,并有助于推理过程中的时间边界细化。 其次,基于单帧注释挖掘伪动作和背景帧。我们通过自适应地将每个注释的单个帧扩展到其附近的上下文帧来识别伪行为帧,并从跨多个视频的所有未注释帧中挖掘伪背景帧。 与地面真实标记帧一起,这些伪标记帧被进一步用于训练分类器。 在THUMOS14、GTEA和BEOID的广泛实验中,SF-Net在分段定位和单帧定位方面对最先进的弱监督方法有了显著的改进。 值得注意的是,SF-Net取得了与其完全监督的对应结果相当的结果,这需要更多的资源密集型注释。
1 Introduction
最近,弱监督时间动作定位(TAL)引起了人们的广泛兴趣。 给定一个只包含视频级别标签的训练集,我们的目标是在长的、未修剪的测试视频中检测和分类每个动作实例。在完全监督的注释中,注释器通常需要回滚用于重复观看的视频,当他们在观看视频[41]时注意到一个动作时,给出动作实例的精确时间边界。对于弱监督的注释,注释者只需要观看一次视频就可以给出标签。 一旦他们注意到一个看不见的动作,他们就可以记录动作类。 这大大减少了注释资源:与在完全监督的设置中注释开始和结束时间相比,视频级别的标签使用的资源更少
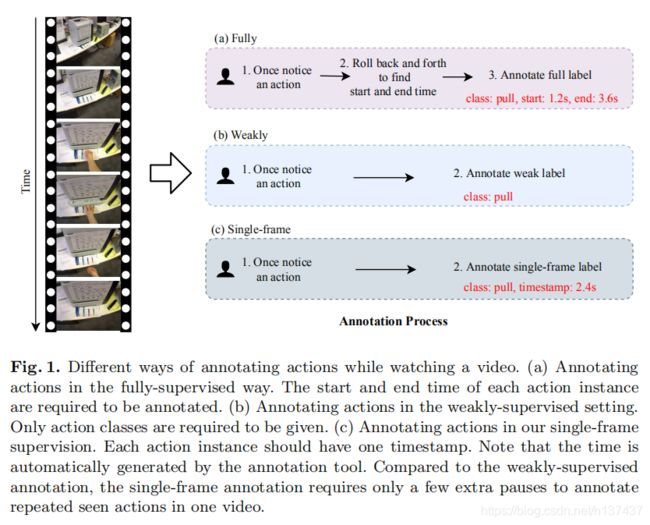
尽管最先进的弱监督TAL工作[25,27,29]取得了有希望的结果,但它们的定位性能仍然低于完全监督的TAL工作[6,18,28]。 为了弥补这一差距,我们有动力利用单帧监督[23]:对于每个动作实例,只指出一个单一的正帧。 单帧监督的注释过程与弱监督注释过程基本相同。 注释者只观看一次视频,以记录操作类和时间戳,当他们注意到每个操作时。 与全面监督相比,它大大减少了注释资源。
在图像域中,Bearman等人[2]是第一个提出图像语义分割的点监督。 在点级注释被Mettes等人扩展[22]到视频域进行时空定位,其中每个动作帧在训练过程中需要一个空间点注释。Moltisanti等人 [23]通过提出单一框架监督并且开发了一种选择置信度很高的帧作为伪动作帧的方法,进一步减少所需资源
在我们的TAL任务中使用单帧监督,定位行动的时间边界的独特挑战仍然没有解决。 为了解决TAL中的这一挑战,我们进行了三项创新,以提高定位模型区分背景帧和动作帧的能力。 首先,我们预测每个帧的“动作性”,它表示任何动作的概率。 其次,基于动作性,我们研究了一种新的背景挖掘算法来确定可能是背景的帧,并利用这些伪背景帧作为附加监督。 第三,在标记伪动作帧时,除了具有高置信度的帧外,我们的目标是确定更多的伪动作帧,从而提出一种动作帧展开算法。
此外,对于许多实际应用程序来说,检测精确的开始时间和结束时间是过分的。 考虑一个记者谁想找到一些车祸照片在一个档案的街道相机视频:它足以检索一个单一的帧为每次事故,记者可以很容易地截断剪辑所需的长度。 因此,除了评估TAL中的传统段定位外,我们还提出了一种新的任务,称为单帧定位,它只需要每个动作实例定位一个帧。
总之,我们的贡献有三个方面:
- (1)据我们所知,这是第一次使用单帧监督来解决具有挑战性的问题,即确定行动的时间边界。 与完全监督的注释相比,单帧注释显著地节省了注释时间。
- (2)我们发现单帧监督可以为背景提供强有力的线索。 因此,从没有注释的帧中,我们提出了两种新的方法来挖掘可能的背景帧和动作帧。 这些可能的背景和动作时间戳被进一步用作训练的伪地面真相。
- (3)我们在三个基准上进行了广泛的实验,在分段定位和单帧定位任务上的性能都得到了很大的提高。
3 Proposed Method
在这一部分中,我们定义了我们的任务,给出了SF-Net的体系结构,最后分别讨论了训练和推理的细节。
3.1 Problem Definition
训练视频可以包含多个动作类和多个动作实例。 与提供每个动作实例的时间边界注释的全监督设置不同,在我们的单帧监督设置中,每个实例只有一个由时间戳t和动作类y的注释器指出的帧。 注意,y∈{1,…,NC},其中NC是类的总数,我们使用索引0来表示背景类。
给定一个测试视频,我们执行两个时间定位任务:(1)Segment localization. 我们用其动作类预测来检测每个动作实例的开始时间和结束时间。 (2)Single frame localization. 我们输出每个检测到的动作实例的时间戳及其动作类预测。 这两个任务的评估指标在SEC. 4中解释。
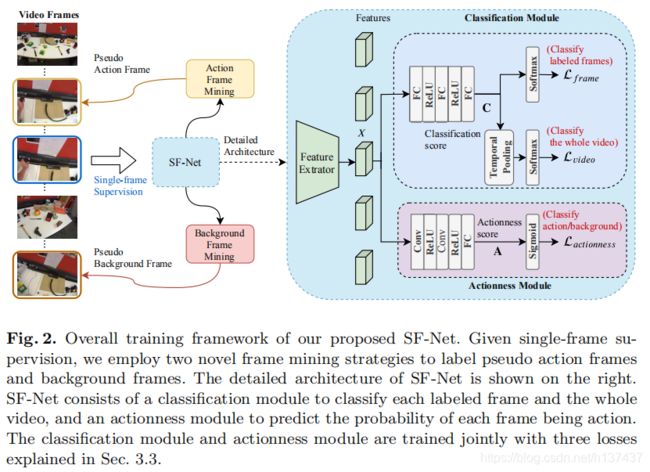
3.2 Framework
Overview. 我们的总体框架如图2所示。培训期间学习单帧监理,SF-Net挖掘假动作和背景图。基于标记帧,我们利用三个损失联合训练一个分类模块,对每个标记帧和整个视频进行分类,并使用一个动作模块来预测每个帧被动作的概率。 在下面,我们概述了框架,同时在SEC. 3.3 中描述了框架挖掘策略和不同损失的细节。
Feature extraction. 对于一批N个视频,提取所有帧的特征并存储在特征张量X∈RN×T中,其中D是特征维数,T是帧数。 由于不同的视频在时间长度上不同,当视频中的帧数小于T时,我们只需垫零。
Classification module. 分类模块输出输入视频中所有帧的每个动作类的分数。 为了对每个标记帧进行分类,我们将X输入到三个全连接(FC)层中,得到分类评分C∈RN×T×Nc1。 然后利用分类评分C计算帧分类损失Lframe。 我们还在时间上池C,如[24]中所描述的,以计算视频级分类损失Lvideo。
Actionness module. 如图所示。 我们的模型有一个动作分支,即识别积极的动作框架。 与分类模块不同的是,actionness模块只为每个帧产生一个标量来表示包含在动作段中的概率。 为了预测动作评分,我们将X输入两个时间卷积层,然后是一个FC层,得到一个动作评分矩阵A∈RN×T。 我们在A上应用乙状结肠,然后计算二元分类损失Lactionness。
3.3 Pseudo Label Mining and Training Objectives
Action classification at labeled frames. 我们使用交叉熵损失进行动作帧分类。 由于视频输入批次中有NT帧,并且大多数帧都是未标记的,我们首先对标记的帧进行过滤,以便进行分类。 假设我们有K标记帧,其中KNT。 我们可以从C中得到K标记帧的分类激活。这些分数被馈送到Softmax层,以获得所有标记帧的分类概率pl∈RK×NC1。 批视频中标注帧的分类损失制定为: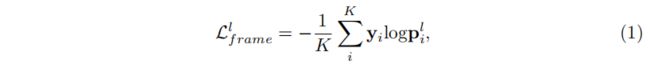
其中PLI表示I标记动作帧的预测。
Pseudo labeling of frames. 由于每个操作实例只有一个标签,所以正面示例的总数很小,可能很难学习。 虽然我们不使用完整的时间注释,但很明显,操作是跨越连续帧的较长事件。 为了增加模型可用的时间信息,我们设计了动作帧挖掘和背景帧挖掘策略,将更多的帧引入到训练过程中。
- (a)行动框架挖掘:我们将每个标记的行动框架视为每个行动实例的锚框架。 我们首先设置扩展半径r,以限制在t处的最大扩展距离到锚框。然后分别从t1帧扩展过去和t1帧扩展未来。 假设锚框的动作类用yi表示。 如果当前扩展帧与锚帧具有相同的预测标签,并且易类的分类分数高于锚帧乘一个预定义值ξ的分数,则我们用标签易对该帧进行注释,并将其放入训练池。 否则,我们停止当前锚框的扩展过程。
- (b)背景框架挖掘:背景框架也很重要,广泛用于本地化方法,[19,26]提高模型的性能。 由于在单帧监督下没有背景标签,我们提出的模型设法从N个视频中的所有未标记帧定位背景帧。 在开始的时候,我们没有监督背景框架在哪里。 但是明确地引入背景类可以避免强制将框架分类为一个操作类。 我们提出的背景帧挖掘算法可以为我们提供训练这种背景类所需的监督,从而提高分类器的可鉴别性。 假设我们试图挖掘ηK的背景帧,我们首先从C中收集所有未标记帧的分类分数。η是背景帧与标记帧的比率。 然后沿着背景类对这些分数进行排序,以选择最高ηK分数PB∈RηK作为背景帧的分数向量。 伪背景分类损失是通过,
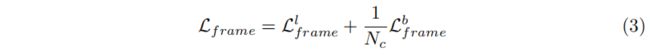
背景帧分类损失协助模型识别无关帧。 与背景挖掘不同的是,[19,26]需要额外的计算源来生成背景帧或采用复杂的损失进行优化,我们在多个视频中挖掘背景帧,并使用分类损失进行优化。 选择的伪背景帧在初始训练回合中可能会有一些噪声。 随着训练的发展和分类器判别能力的提高,我们能够更正确地减少噪声和检测背景帧。 以更正确的背景帧作为监督信号,可以进一步提高分类器的可鉴别性。 在我们的实验中,我们观察到这种简单的背景挖掘策略允许更好的动作定位结果。 我们将背景分类损失与标记帧分类损失相结合,制定了单帧分类损失

其中NC是利用背景类的影响的操作类的数量。
Actionness prediction at labeled frames. 在完全监督的TAL中,各种方法学会产生可能包含潜在活动[37,18,6]的行动建议。 为此,我们设计了动作模块,使模型集中在与目标动作相关的帧上。 我们的actionness模块不会在提案方法中产生时间段,而是为每个框架产生actionness评分。 动作模块与SF-Net中的分类模块并行。 它为时间动作定位提供了额外的信息。 我们首先在训练视频中收集标记帧的动作分数Al∈RK。 帧的值越高,该帧属于目标动作的概率就越高。 我们还利用背景帧挖掘策略得到动作评分AB∈RηK。 作用损失的计算方法是,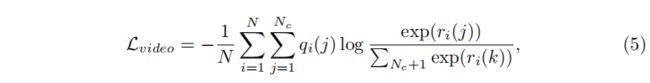
其中σ是sigmoid函数,将动作分数缩放到[0,1]。
Full objective. 我们采用[24]中描述的视频级损失来解决视频级的多标签动作分类问题。 对于第一个视频,选择分类激活C(I)的每个类别(其中k=Ti/8)的顶k激活,然后进行平均,以获得与[27,24]一样的特定于类的编码ri∈RC1。 我们平均所有的帧标签预测在视频vi,以获得视频级的地面真相气∈RNC1。 视频级损耗按

其中qi(J)是表示视频vi的概率质量的qi的第j个值,属于第j个类。
因此,我们提出的方法的总训练目标是
![]()
其中Lframe、Lvideo和Lactionness分别表示帧分类损失、视频分类损失和动作损失。 α和β是利用不同损失的超参数。
3.4 Inference
在测试阶段,我们需要给出每个检测到的动作的时间边界。 我们遵循先前的弱监督工作[25],通过对分类分数的临时池和阈值来预测视频级标签。 如图所示。 首先,通过将视频的输入特征输入到分类模块和动作模块中,得到分类评分C和动作评分A。 对于分段定位,我们[25,26]遵循阈值化策略,使动作帧保持在阈值以上,连续的动作帧构成动作段。 对于每个预测的视频级动作类,我们通过检测一个区间来定位每个动作段,该区间内的每个帧的分类分数和动作分数之和超过预设的阈值。 我们简单地将检测片段的置信度评分设置为其最高帧分类评分和动作评分之和。 对于单帧定位,对于动作实例,我们选择检测段中具有最大激活分数的帧作为定位动作帧。
Experiments
Datasets
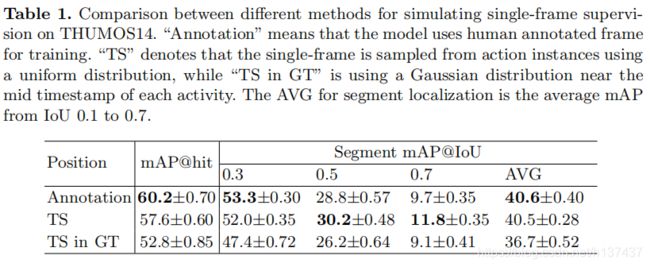
Implementation Details
我们使用I3D网络[4]在Kinects数据[5]上训练来提取视频特征。 对于RGB流,我们将帧的最小维数重新标度为256,并执行大小为224×224的中心裁剪。 对于流,我们[39]应用TV-L1光流算法。 我们遵循两流融合操作,[24]从外观(R GB)和运动(流)分支整合预测。 对I3D模型的输入是16帧的堆栈。
在所有数据集上,我们将所有实验的学习速率设置为10^-3,并使用Adam[14]对模型进行批量大小为32的训练。 减重超参数α和β设置为1。 模型性能对这些超参数不敏感。 对于用于挖掘背景帧的超参数η,我们在THUMOS14上将其设置为5,并在其他两个数据集上将其设置为1。 对于GTEA、BEOID和THUMOS14,迭代次数分别设置为500、2000和5000
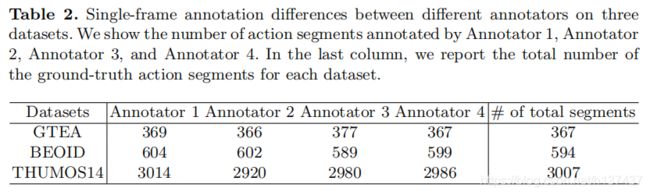
Results


Conclusion
在本文中,我们研究了如何利用单帧监督来训练时间动作定位模型,用于分段定位和推理过程中的单帧定位。 我们的SF-Net通过预测动作评分、伪背景帧挖掘和伪动作帧挖掘,充分利用了单帧监督。 在三个标准基准上,SF-Net在分段定位和单帧定位方面都明显优于弱监督方法。