【FAS Survey】《Deep learning for face anti-spoofing: A Survey》

PAMI-2022
最新成果:https://github.com/ZitongYu/DeepFAS
文章目录
- 1 Introduction & Background
-
- 1.1 Face Spoofing Attacks
- 1.2 Datasets for Face Anti-Spoofing
- 1.3 Evaluation Metrics
- 1.4 Evaluation Protocols
- 2 Deep FAS with Commercial RGB Camera
-
- 2.1 Hybrid (Handcraft + Deep Learning) Method
- 2.2 Traditional Deep Learning Method
-
- 2.2.1 Direct Supervision With Binary Cross Entropy Loss
- 2.2.2 Pixel-Wise Supervision
- 2.3 Generalized Deep Learning Method
-
- 2.3.1 Generalization to Unseen Domain
- 2.3.2 Generalization to Unknown Attack Types
- 3 Deep FAS with Advanced Sensors
-
- 3.1 Uni-Modal Deep Learning Upon Specialized Sensor
- 3.2 Multi-Modal Deep Learning
- 4 Discussion and Future Directions
-
- 4.1 Architecture, Supervision and Interpretability
- 4.2 Representation Learning
- 4.3 Real-World Open-Set FAS
- 4.4 Generic and Unified PA Detection
- 4.5 Privacy-Preserved Training
- Last but no least
1 Introduction & Background
人脸识别系统,automatic face recognition (AFR) system:
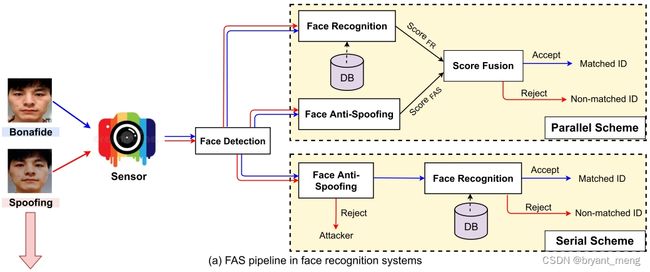
- parallel fusion,并行
- serial scheme,串联
人脸活检:
- face presentation attack detection or face liveness detection
人脸活检方法分类:
- 传统方法
- 深度学习
(1)传统方法
Most traditional algorithms are designed based on human liveness cues and handcrafted features
liveness cues 包括但不限于:
- eye-blinking
- face and head movement(nodding and smiling)
- gaze tracking
- remote physiological signals(rPPG)
- screen bezel(屏幕边框)
- irregular/limited geometric depth distribution
- abnormal reflection(the face surface of print/replay and transparent mask attacks are usually with irregular/limited geometric depth distribution and abnormal reflection, respectively.)
- moire pattern(摩尔条纹)
- illumination changes
- physiological signals
classical handcrafted descriptors designed for extracting effective spoofing patterns from various color spaces(RGB, HSV, and YCbCr)
- LBP
- SIFT
- SURF
- HOG
- DoG
- image quality
- optical flow motion
(2)深度学习的方法
是本文讨论的重点,作者总结如下
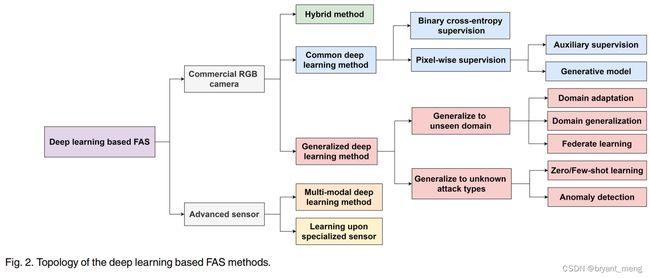
1.1 Face Spoofing Attacks
攻击类型,automatic face recognition (AFR) system 经常分为这两类
- digital manipulation(in the digital virtual domain)
- physical presentation attacks(PAs)
本文重点讨论 PAs——misleads the real-world AFR systems via presenting face upon physical mediums in front of the imaging sensors
PAs 不同切入角度有不同的分类形式

根据 attackers’ intention
- impersonation:entails the use of spoof to be recognized as someone else via copying a genuine user’s facial attributes to special mediums such as photo, electronic screen, and 3D mask(拿着别人的假脸攻击)
- obfuscation:hide or remove the attacker’s own identity using various methods such as glasses, makeup, wig, and disguised face.(在自己脸上作假来攻击)
根据 geometry property
- 2D attacks——Flat/wrapped printed photos, eye/mouth-cut photos, and digital replay of videos are common 2D attack variants
- 3D attacks——hard/rigid masks can be made from paper, resin, plaster, or plastic, flexible soft masks are usually composed of silicon or latex
- low-fidelity 3D mask(低仿 3D)
- high fidelity mask(高仿 3D)
根据 facial region covering
- whole attacks
- partial attacks
1.2 Datasets for Face Anti-Spoofing
Sensor:
- multispectral SWIR(短波红外,1400 - 2500 nm)
- NIR(750-1400 nm)
- RGB
- depth
- Thermal
- four-directional polarized
- other specialized sensors (e.g., Light field camera)
数据集(prevailing public FAS datasets):data amount, subject numbers, modality / sensor, environmental setup, and attack types.
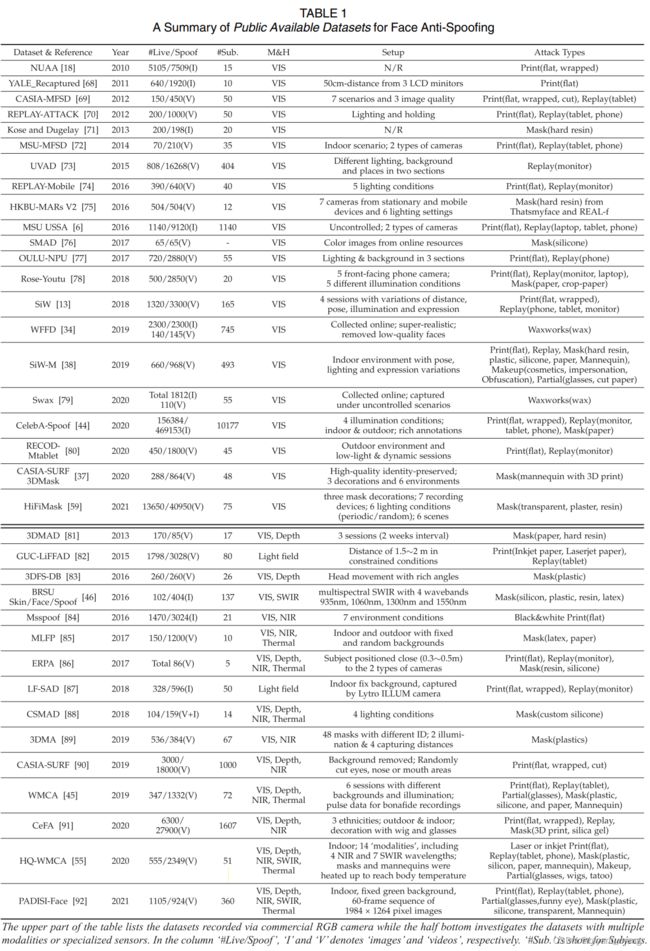
samples(图片数) and subjects(IDs)
公开数据发展的趋势:
- large scale data amount
- diverse data distribution
- multiple modalities and specialized sensors

1.3 Evaluation Metrics
评价指标
- Rejection Rate (FRR)
- False Acceptance Rate (FAR)
- Half Total Error Rate (HTER)
- Equal Error Rate (EER)
- Area Under the Curve (AUC)
- Attack Presentation Classification Error Rate (APCER),
- Bonafide Presentation Classification Error Rate (BPCER)
- Average Classification Error Rate (ACER) ,越低越好
1.4 Evaluation Protocols
测试方式(evaluation protocols):
- intra-dataset intra-type:with slight domain shift
- cross-dataset intra-type:train on source domains and test on shifted target domain
- intra-dataset cross-type(leave-one-type-out setting)
- cross-dataset cross-type(train on datasets A test on datasets B)

上图评价指标都是越低越好
open-set problem in practice,需要考虑 unseen domain generalization
2 Deep FAS with Commercial RGB Camera

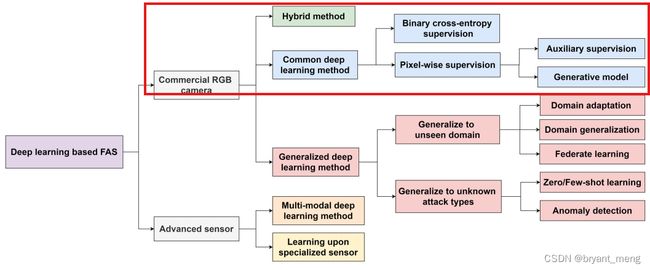
2.1 Hybrid (Handcraft + Deep Learning) Method
有如下三种混合形式
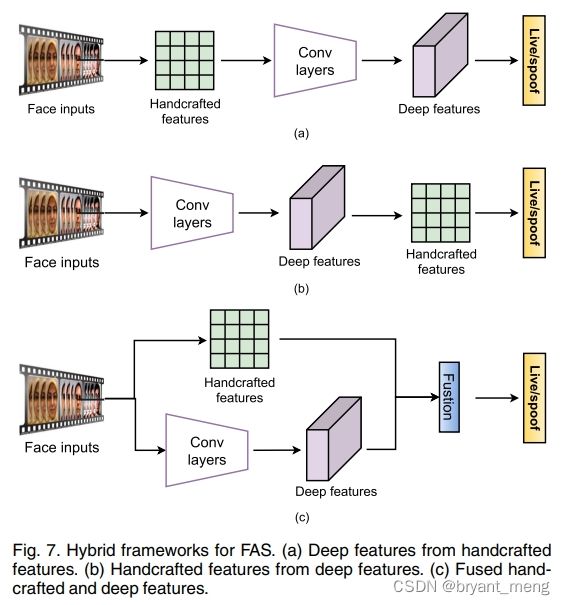
存在的缺点
(1)crafted features highly rely on the expert knowledge and not learnable, which are inefficient once enough training data are available;
(2)there might be feature gaps/incompatibility between handcrafted and deep features, resulting in performance saturation.
2.2 Traditional Deep Learning Method
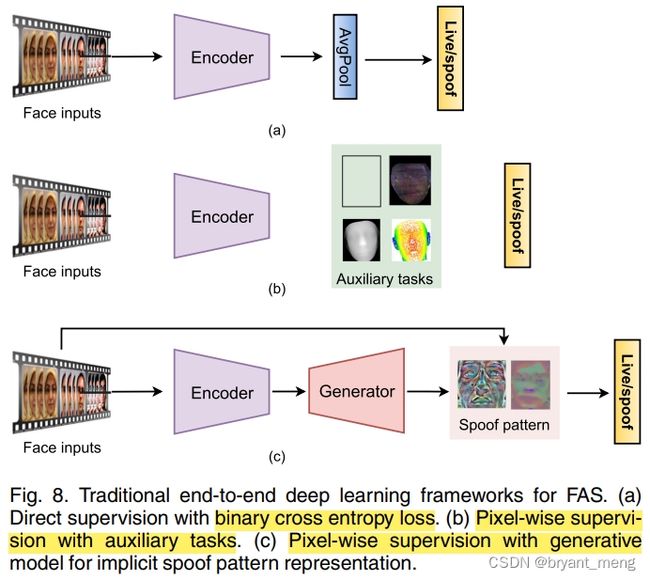
- 二分类的方法 supervision With Binary Cross Entropy Loss
- pixel-wise auxiliary/generative supervisions
下面展开说说
2.2.1 Direct Supervision With Binary Cross Entropy Loss
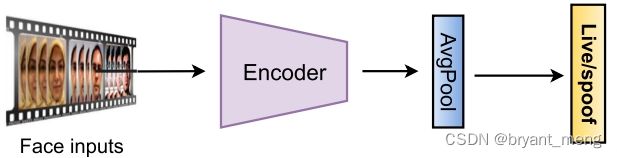
treat FAS as a binary classification problem (e.g., ‘0’ for live while ‘1’ for spoofing faces, or vice versa)
bonafide versus PA
与常见的二分类视觉任务的不同点在于
- self-evolving problem(attack vs. defense develop iteratively)
- content-irrelevant (e.g., not related to facial attribute and ID)
- subtle and with fine-grained details
very challenging to distinguish by even human eyes,性别二分类关注的是 semantic features,活检关注的是 arbitrary and unfaithful clues (e.g., screen bezel) for spoofing patterns,such intrinsic live/spoof clues are usually closely related with some position-aware auxiliary tasks.
存在的缺点:
-
these supervision signals only provide global (spatial/temporal) constraints for live/spoof embedding learning, which may causes FAS models to easily overfit to unfaithful patterns.
-
usually black-box and the characteristic of their learned features are hard to understand
2.2.2 Pixel-Wise Supervision
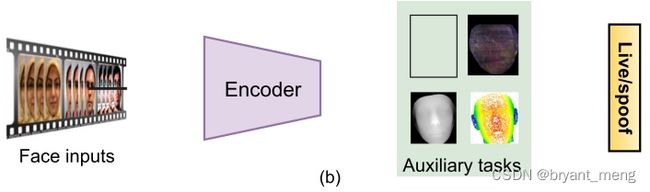
(1)Pixel-Wise Supervision With Auxiliary Task
provide more fine-grained and contextual task-related clues for better intrinsic feature learning,而不是 unfaithful patterns (e.g., screen bezel).
auxiliary supervision signals:
- pseudo depth labels
- binary mask labels——attack-type-agnostic and spatially interpretable
- 3D point cloud map
- Fourier spectra
- reflection maps
- ternary map
- original face input reconstruction
- pixel-wise reconstruction constraints
- LBP texture map
存在的缺点:
- usually relies on the high-quality (e.g., high-resolution) training data for fine grained spoof clue mining, and is harder to provide effective supervision signals when training data are too noisy and with low quality
- the pseudo auxiliary labels are either human-designed or generated by other off-the-shelf algorithms, which are not always trustworthy
(2)Pixel-Wise Supervision With Generative Model
usually relaxes the expert-designed hard constraints (e.g.,auxiliary tasks), and leaves the decoder to reconstruct more natural spoof-related trace.
The generated spoof patterns are visually insightful, and are challenging to manually describe with human prior knowledge.
缺点
such soft pixel-wise supervision might easily fall into the local optimum and overfit on unexpected interference (e.g., sensor noise),
解决方式之一
Pixel-Wise Supervision With Generative Model + Pixel-Wise Supervision With Auxiliary Task
2.3 Generalized Deep Learning Method
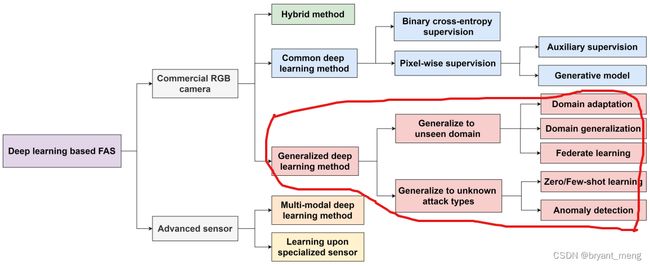
Traditional end-to-end deep learning 缺点,下面场景会翻车
- unseen dominant conditions——indicate the spoof irrelated external changes (e.g., lighting and sensor noise) but actually influence the appearance quality
- unknown attack types——mean the novel attack types with intrinsic physical properties (e.g., material and geometry) which have not occurred in the training phase
Generalized Deep Learning Method
- domain adaptation
- generalization techniques
- zero/few-shot learning
- anomaly detection
2.3.1 Generalization to Unseen Domain
Domain adaptation(DA) vs Domain Generalization(DG)
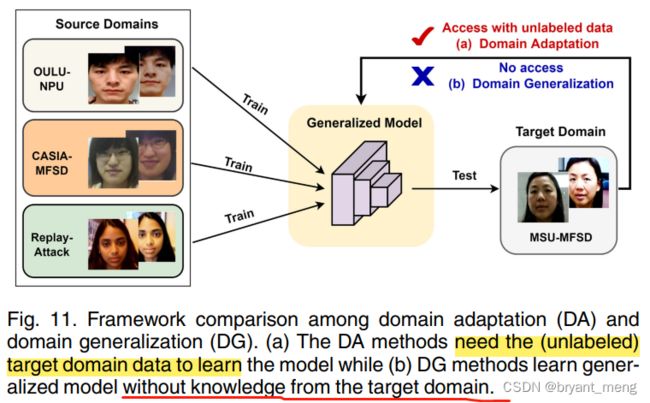
一个需要无标签的 target domain 数据,一个不需要 target domain 的数据
(1)Domain adaptation(DA)
The distribution of source and target features are usually matched in a learned feature space
minimize the distribution discrepancy between the source and the target domain by utilizing unlabeled target data,
缺点
- it is difficult and expensive to collect a lot of unlabeled target data
- the source face data are usually inaccessible when deploying FAS models on the target domain
(2)Domain Generalization(DG)
缺点
domain generalization benefits FAS models to perform well in unseen domain, but it is still unknown whether it deteriorates the discrimination capability for spoofing detection under the seen scenarios.
2.3.2 Generalization to Unknown Attack Types
(1)Zero/Few-Shot Learning
缺点
few-shot learning 在 zero-shot case 场景会翻车
the failed detection usually occurs in the challenging attack types (e.g., transparent mask, funny eye, and makeup), which share similar appearance distribution with the bonafide
(2)Anomaly Detection
first trains a reliable one-class classifier to accurately cluster the live samples. Then any samples (e.g., unknown attacks) outside the margin of the live sample cluster would be detected as attacks
缺点
suffer from discrimination degradation compared with conventional live/spoof classification in the real-world open-set scenarios (i.e., both known and unknown attacks).
3 Deep FAS with Advanced Sensors
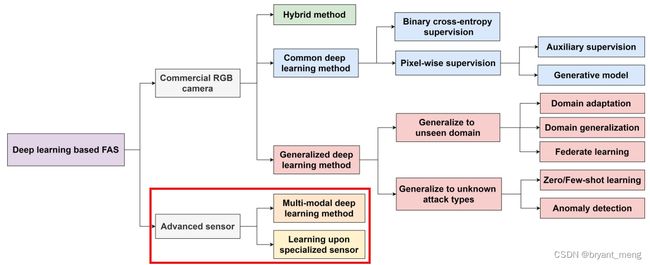
3.1 Uni-Modal Deep Learning Upon Specialized Sensor

绿色框还有个 medium 的评价,P < M < G < VG
NIR (900 to 1800nm), poor imaging quality in long distance
SWIR(940nm and 1450nm)
dynamic flash is sensitive under outdoor environments and is not user-friendly due to the long temporal activation time
3.2 Multi-Modal Deep Learning
(1)Multi-Modal Fusion
- feature-level fusions
modality features are usually extracted from separate branches with high computational cost - input-level fusions
- decision-level fusions
(2)Cross-Modal Translation
pseudo modalities could be generated via cross-modality translation
missing modal data for multi-modal FAS
4 Discussion and Future Directions
the limitations of the current development
- Limited live/spoof representation capacity with sub-optimal deep architectures, supervisions, and learning strategies
- Evaluation under saturating and unpractical testing benchmarks and protocols
- Isolating the anti-spoofing task on only the face area and physical attacks
- Insufficient consideration about the interpretability and privacy issues
4.1 Architecture, Supervision and Interpretability
automatically search and find the best-suited temporal architectures especially for multi-modal usage
rich temporal context vs binary or pixel-wise supervision
More advanced feature visualization manners and fine-grained pixel-wise spoof segmentation should be developed for interpretable FAS
4.2 Representation Learning
transfer learning——缓解过拟合
disentangled learning——disentangle the intrinsic spoofing clues from the noisy representation
metric learning
self-supervised and semi-supervised learning
4.3 Real-World Open-Set FAS
GrandTest
4.4 Generic and Unified PA Detection

AFR-aware and FAS-aware
digital and physical attack types
4.5 Privacy-Preserved Training
federated learning
Last but no least
向「假脸」说 No:用OpenCV搭建活体检测器
活体检测的方法有很多,包括:
-
纹理分析(Texture analysis),该方法计算了面部区域的局部二值模式(Local Binary Patterns,LBP),用 SVM 将面部分为真实面部和伪造面部;
-
频率分析(Frequency analysis),比如检查面部的傅立叶域;
-
可变聚焦分析(Variable focusing analysis),例如检查连续两帧间像素值的变化;
-
启发式算法(Heuristic-Based algorithms),包括眼球运动、嘴唇运动和眨眼检测。这些算法试图追踪眼球运动和眨眼行为,来确保用户不是拿着谁的照片(因为照片不会眨眼也不会动嘴唇);
-
光流算法(Optical Flow algorithm),即检测 3D 对象和 2D 平面产生的光流的属性和差异;
-
3D 面部形状(3D face shape),类似于 iPhone 上的面部识别系统,这种算法可以让面部识别系统区分真实面部和其他人的照片或打印出来的图像;
暂时下载不到的文章 for free
- Unknown presentation attack detection with face rgb images
- Fake iris detection using structured light
- FaceRevelio: a face liveness detection system for smartphones with a single front camera
- Meaningful adversarial stickers for face recognition in physical world
阅读笔记
-
【DDFD】《Multi-view Face Detection Using Deep Convolutional Neural Networks》(ICMR-2015)
-
【IoU Loss】《UnitBox: An Advanced Object Detection Network》(ACM MM-2016)
-
【FAS】《Face Anti-Spoofing Using Patch and Depth-Based CNNs》(IJCB-2017)
-
【MLFP】《Face Presentation Attack with Latex Masks in Multispectral Videos》(CVPRW-2017)
-
【Face Detection】《Face Detection using Deep Learning: An Improved Faster RCNN Approach》(Neurocomputing-2018)
-
【GDConv】《MobileFaceNets:Efficient CNNs for Accurate RealTime Face Verification on Mobile Devices》(CCBR-2018)
-
【CASIA-SURF】《A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing》(CVPR-2019)
-
【FAS-FRN】《Recognizing Multi-modal Face Spoofing with Face Recognition Networks》(CVPR-2019 workshop)
-
【FaceBagNet】《FaceBagNet:Bag-of-local-features Model for Multi-modal Face Anti-spoofing》(CVPR-2019 workshop)
-
【FeatherNets】《FeatherNets:Convolutional Neural Networks as Light as Feather for Face Anti-spoofing》(CVPR-2019 workshop)
-
【WMCA】《Biometric Face Presentation Attack Detection with Multi-Channel Convolutional Neural Network》(TIFS-2019)
-
【WebFace260M】《WebFace260M:A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition》(CVPR-2021)
-
【EMFace】《EMface: Detecting Hard Faces by Exploring Receptive Field Pyramids》(arXiv-2021)