为什么先进的RAG方法对AI的未来至关重要?
原文地址:Why Are Advanced RAG Methods Crucial for the Future of AI?
检索增强生成(RAG)是生成式人工智能领域的一大进步,它将高效的数据检索与大型语言模型的强大功能结合在一起。
RAG 的核心工作是利用向量搜索挖掘相关的现有数据,将这些检索到的信息与用户的查询结合起来,然后通过类似 ChatGPT 的大型语言模型进行处理。
这种 RAG 方法可确保生成的响应不仅精确,而且还能反映当前的信息,从而大大减少输出中的不准确或 "幻觉"。
然而,随着人工智能应用领域的不断扩大,对 RAG 提出的要求也变得更加复杂多样。基本的 RAG 框架虽然强大,但可能已不足以满足不同行业和不断发展的使用情境的细微需求。这就是高级 RAG 技术发挥作用的地方。这些增强的方法被量身定制以解决特定的挑战,在信息处理中提供更高的精度、适应性和效率。
了解 RAG 技术
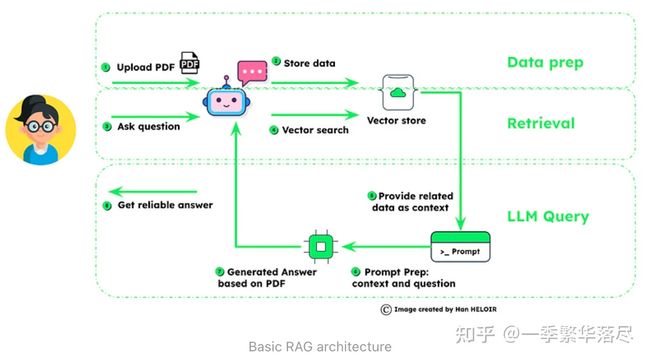
基本RAG的实质
检索增强生成(RAG)将数据管理与智能查询相结合,以提高人工智能的响应精度。
- 数据准备:首先是用户上传数据,然后对数据进行分块并用嵌入式技术存储,为检索奠定基础。
- 检索:一旦提出问题,系统就会利用矢量搜索技术对存储的数据进行挖掘,找出相关信息。
- LLM 查询:检索到的信息被用于为语言模型 (LLM) 提供上下文,语言模型通过将上下文与问题相结合来准备最终的提示。结果是根据所提供的丰富的上下文数据生成答案,这证明 RAG 能够生成可靠、明智的答案。
整个过程如图所示,强调了 RAG 对可靠数据处理和根据上下文生成答案的重视,这对于高级人工智能应用至关重要。
随着人工智能技术的发展,RAG 的能力也在不断提高。先进的 RAG 技术层出不穷,不断突破这些模型所能达到的极限。这些进步不仅仅是更好的检索或更流畅的生成。它们包含一系列改进,包括增强对上下文的理解、更复杂地处理细微查询,以及无缝集成各种数据源的能力。
技术 1:Self-Querying Retrieval(自查询检索)
自查询检索器,具有对自身进行查询的能力。给定任何自然语言查询,检索器使用一个构造查询的LLM链来编写一个结构化查询,然后将该结构化查询应用到其底层的VectorStore上。这使得检索器不仅能够使用用户输入的查询进行语义相似性比较,与存储的文档内容进行对比,而且还能从用户查询中提取对存储文档元数据的过滤条件,并执行这些过滤器。(来自LangChain 官网:Self-querying | ️ Langchain)
自查询检索是人工智能驱动的数据库系统中的一项前沿技术,它通过自然语言理解来增强数据查询功能。例如,如果您有一个产品目录数据集,您想搜索 "a black leather mini skirt less than 20 dollars",您不仅要对产品描述进行语义搜索,还可以对产品的子类别和价格进行过滤。


- Natural Language Query Processing(自然语言查询处理):首先由 LLM 解释用户的自然语言查询,提取意图和上下文。
- Metadata Field Information(元数据字段信息):要实现这一点,必须预先提供文档中的元数据字段信息。这些元数据定义了数据的结构和属性,为构建有效的查询和筛选提供指导,确保搜索结果的准确性和相关性。
- Query Construction(查询构建):接下来,LLM 会构建一个结构化查询,既包括用于向量搜索的语义元素,又包括用于提高精度的元数据过滤器。
- Executing the Query(执行查询):该结构化查询应用于 MongoDB 的向量搜索,根据语义相似性和元数据相关性过滤结果。
通过从自然语言中构建结构化查询,自查询检索可同时考虑语义元素和元数据,从而确保数据获取的效率和精度。
import openai
import pymongo
from bson.json_util import dumps
# OpenAI API key setup
openai.api_key = 'your-api-key'
# Connect to MongoDB
client = pymongo.MongoClient('mongodb://localhost:27017/')
db = client['your_database']
collection = db['your_collection']
# Function to use GPT-3.5 for interpreting natural language query and outputting a structured query
def interpret_query_with_gpt(query):
response = openai.Completion.create(
model="gpt-3.5-turbo",
prompt=f"Translate the following natural language query into a MongoDB vector search query:\n\n'{query}'",
max_tokens=300
)
return response.choices[0].message.content
# Function to execute MongoDB vector search query
def execute_query(query):
structured_query = eval(query) # Caution: Use eval carefully
results = collection.aggregate([structured_query])
return dumps(list(results), indent=4)
# Example usage
natural_language_query = "Find documents related to AI advancements"
structured_query = interpret_query_with_gpt(natural_language_query)
results = execute_query(structured_query)
print(results)
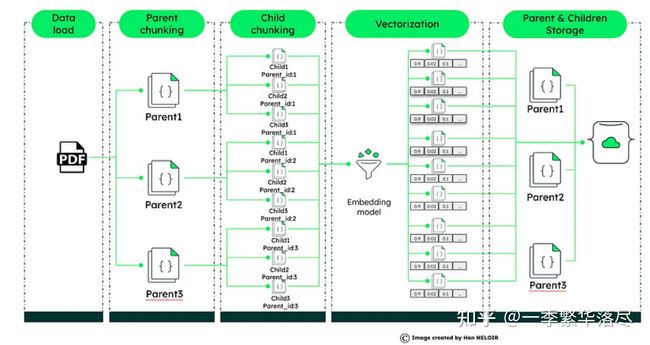
技术 2:Parent-Child Relationship in Advanced RAG (aka auto merging)(先进 RAG 中的父子关系(又称自动合并))
在先进的 RAG 系统中,父子关系的概念将数据检索提升到了一个新的水平。这种方法是将大型文档分割成更小的、易于管理的部分--父文档及其相应的子文档。
- Parent-Child Document Dynamics(父子文档动态):大型文档被拆分为父文档和子文档。父文档提供更广泛的上下文,而子文档提供具体的细节。
- Vectorization for Precision(精确的向量化):每个子文件都经过向量化处理,创建独特的数字档案,有助于精确检索数据。
- Query Processing and Contextual Responses(查询处理和上下文响应):收到查询后,系统会将其与这些向量化子文档进行匹配。系统不仅会检索最相关的子文档,还会引入父文档以获取更多上下文信息。这种方法不仅能确保回复的准确性,还能提供丰富的上下文信息。
- Enhanced LLM Integration(增强 LLM 集成):子文档和父文档中的详细信息会被输入大语言模型(LLM),如 ChatGPT,以生成既准确又能感知上下文的响应。
- Implementation in MongoDB(MongoDB 的实现):利用 MongoDB 的向量搜索,这种技术提供了一种精炼的方法来浏览大型数据集,确保快速且具有丰富上下文的响应。
这种技术通过提供更微妙和具有上下文丰富度的数据检索方法来解决基本RAG的局限性,对于理解更广泛上下文至关重要的复杂查询非常关键。
这项技术解决了基本 RAG 的局限性,为数据检索提供了一种更细致入微、上下文更丰富的方法,对于理解更广泛上下文至关重要的复杂查询非常关键。
import os
from dotenv import load_dotenv
from pymongo import MongoClient
from langchain.llms import OpenAI
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Load environment variables from .env file
load_dotenv(override=True)
# Set up MongoDB connection details
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
MONGO_URI = os.environ["MONGO_URI"]
DB_NAME = "pdfchatbot"
COLLECTION_NAME = "advancedRAGParentChild"
# Initialize OpenAIEmbeddings with the API key
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# Connect to MongoDB
client = MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
# Initialize the text splitters for parent and child documents
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)
# Function to process PDF document and split it into chunks
def process_pdf(file):
loader = PyPDFLoader(file.name)
docs = loader.load()
parent_docs = parent_splitter.split_documents(docs)
# Process parent documents
for parent_doc in parent_docs:
parent_doc_content = parent_doc.page_content.replace('\n', ' ')
parent_id = collection.insert_one({
'document_type': 'parent',
'content': parent_doc_content
}).inserted_id
# Process child documents
child_docs = child_splitter.split_documents([parent_doc])
for child_doc in child_docs:
child_doc_content = child_doc.page_content.replace('\n', ' ')
child_embedding = embeddings.embed_documents([child_doc_content])[0]
collection.insert_one({
'document_type': 'child',
'content': child_doc_content,
'embedding': child_embedding,
'parent_ref': parent_id
})
return "PDF processing complete"
# Function to embed a query and perform a vector search
def query_and_display(query):
query_embedding = embeddings.embed_documents([query])[0]
# Retrieve relevant child documents based on query
child_docs = collection.aggregate([{
"$vectorSearch": {
"index": "vector_index",
"path": "embedding",
"queryVector": query_embedding,
"numCandidates": 10
}
}])
# Fetch corresponding parent documents for additional context
parent_docs = [collection.find_one({"_id": doc['parent_ref']}) for doc in child_docs]
return parent_docs, child_docs
# Initialize the OpenAI client
openai_client = OpenAI(api_key=OPENAI_API_KEY)
# Function to generate a response from the LLM
def generate_response(query, parent_docs, child_docs):
response_content = " ".join([doc['content'] for doc in parent_docs if doc])
chat_completion = openai_client.chat.completions.create(
messages=[{"role": "user", "content": query}],
model="gpt-3.5-turbo"
)
return chat_completion.choices[0].message.content
# Bringing It All Together
with gr.Blocks(css=".gradio-container {background-color: AliceBlue}") as demo:
gr.Markdown("Generative AI Chatbot - Upload your file and Ask questions")
with gr.Tab("Upload PDF"):
with gr.Row():
pdf_input = gr.File()
pdf_output = gr.Textbox()
pdf_button = gr.Button("Upload PDF")
with gr.Tab("Ask question"):
question_input = gr.Textbox(label="Your Question")
answer_output = gr.Textbox(label="LLM Response and Retrieved Documents", interactive=False)
question_button = gr.Button("Ask")
question_button.click(query_and_display, inputs=[question_input], outputs=answer_output)
pdf_button.click(process_pdf, inputs=pdf_input, outputs=pdf_output)
demo.launch()
技术 3:Interactive RAG — Question-Answering(互动式 RAG ——问答)
由 MongoDB 销售创新项目负责人 Fabian Valle 开发的交互式 RAG 代表了 AI 驱动搜索能力的前沿。这项技术允许用户实时主动影响检索过程,从而增强了传统 RAG 的功能,使信息发现更加量身定制和精确。

- Dynamic Retrieval Strategy(动态检索策略):用户可以随时调整检索参数,如块大小或来源数量,以优化特定查询的结果。
- Function Calling for Enhanced Interactivity(功能调用增强互动性):功能调用 API 的集成使 RAG 系统能够与外部数据源和服务互动,提供最新的相关信息。
- Interactive Question-Answering(交互式问答):该功能使用户能够用自然语言提问,然后系统会使用向量搜索来处理这些问题,找到最相关的信息,然后使用 GPT-3.5 或 GPT-4 等语言模型生成有依据的答复。
- Continuous Learning(持续学习):互动式 RAG 系统会从每次互动中学习,不断完善其知识库,从而确保后续回答更加准确,更符合实际情况。
第三项技术展示了先进的 RAG 方法如何对未来的人工智能应用至关重要,它提供了一种动态、自适应和以用户为中心的信息检索和处理方法。
技术 4:Contextual compression in Advanced RAG(先进 RAG 中的上下文压缩)
上下文压缩解决了从充斥着无关文本的文档中检索相关信息的挑战。它通过根据查询上下文压缩文档来适应查询的不可预测性,确保只有相关信息才会通过语言模型,从而提高响应质量并降低成本。
- 上下文压缩机制:这种方法根据查询的上下文压缩检索到的文档,即只返回与用户请求最相关的信息,从而优化检索过程。
- 高效的数据处理:通过根据上下文压缩文件,系统可最大限度地减少语言模型的负荷,从而实现更快、更具成本效益的操作。
- 实现文档压缩器:利用基础检索器和文档压缩器(如 Langchain 的 LLMChainExtractor),系统会根据文档与查询的相关性对初始文档进行过滤,以缩短内容或完全省略文档。
- 增强查询相关性:结果是一组压缩文档,其中包含高度相关的信息,语言模型可利用这些信息生成精确的答案,而无需筛选无关内容。
结论
最后,我们探索了先进的 RAG 方法,探讨了它们在人工智能革命中的关键作用。自我查询检索、父子关系、交互式 RAG 和上下文压缩等技术向我们展示了将人类的理解力与机器的精确性相融合的艺术。有了人工智能思想领袖的指导和他们开创的实际应用,我们站在了未来的风口浪尖上,人工智能不仅能回答我们的问题,还能理解我们的问题,包括上下文。这就是未来,先进的 RAG 将引导我们走向更直观、反应更迅速、更准确的人工智能。
参考
[1] Interactive RAG with MongoDB Atlas + Function Calling API | MongoDB
[2] Semantic Search Made Easy With LangChain and MongoDB