py3_VSCode 配置 Python 环境以及初识 Python 正则表达式
##################################################
目录
活动简介
VSCode 配置 Python 环境
怎么获取及安装 VSCode 官方包
VSCode 配置 Python 环境
编写解释运行一个 Python 脚本
初识 Python 正则表达式
什么是 正则表达式/re/匹配模式
正则表达式运算优先级
简单字符匹配
预定义字符和特殊字符
匹配方法和匹配对象的方法
##################################################
活动简介
活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰;一个人摸索学习很难坚持,想组团高效学习;想写博客但无从下手,急需写作干货注入能量;热爱写作,愿意让自己成为更好的人…
…
欢迎参与CSDN学习挑战赛,成为更好的自己,请参考活动中各位优质专栏博主的免费高质量专栏资源(这部分优质资源是活动限时免费开放喔~),按照自身的学习领域和学习进度学习并记录自己的学习过程,或者按照自己的理解发布专栏学习作品!
##################################################
VSCode 配置 Python 环境
——————————
怎么获取及安装 VSCode 官方包
请看小爷的这篇博客 上过热榜的哦!~~
[C# SDK/IDE]-VSCode 搭建 C# 开发环境_燃吹的博客-CSDN博客_vscode 开发c#获取安装 Visual Studio Code 汉化及插件配置官网下载安装.NET Code SDK初识 .NET SDK 的一些命令基本 C# 程序编译和运行命令行单独利用 SDK 命令初始化工作空间并编译运行 C# 程序在 VSCode 中搭配 SDK 编译运行 C# 程序安装配置 Code Runner 插件更方便地编译运行以及本节资源下载...............https://blog.csdn.net/m0_67268286/article/details/125529352
——————————
VSCode 配置 Python 环境
启动 VSCode 编辑器:

快捷键
Ctrl Shift x
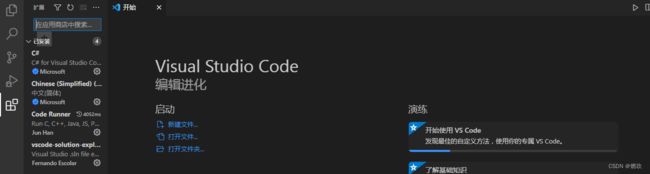
在扩展中搜索
Python安装 Python 环境:

第一个就是:
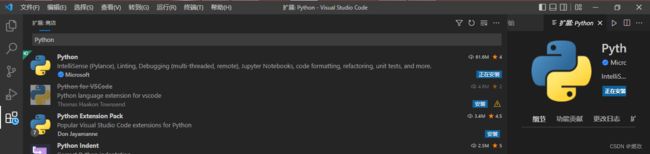
正在安装:

快捷键
Ctrl Shift p打开命令面板:
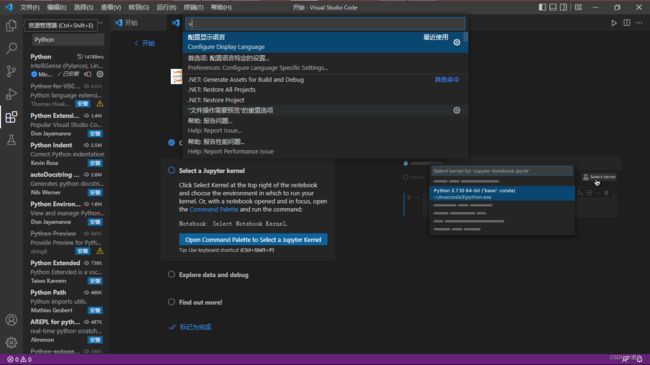
搜索:
Python: Select Interpreter已经自动帮我们选择好了:

如果没有 请选择安装路径下的 python.exe 程序!
——————————
编写解释运行一个 Python 脚本
打开一个 .py 脚本:

提示我们此时处于受限模式:

点击管理 点击信任:


此时有没有看到右下角:

这表示激活扩展成功!
点击运行按钮 开始解释了:

解释后运行成功:
Windows PowerShell
版权所有 (C) 2014 Microsoft Corporation。保留所有权利。
PS C:\Users\byme> python -u "e:\PY\test.py"
Hello, World!
PS C:\Users\byme> 
##################################################
初识 Python 正则表达式
——————————
什么是 正则表达式/re/匹配模式
正则表达式经常用于验证和查找符合规则的文本
广泛用于各种搜索引擎、账户密码的验证等
或者
数据开发
文本检索
数据筛选
爬虫爬取数据
时来检索字符串
正则表达式已经内嵌入 Python 中 所以 re 模块也被称为正则表达式
使用正则表达式需要导入 re 模块:
C:\>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> ——————————
正则表达式运算优先级
相同优先级的正则表达式从左到右进行计算
不同优先级的运算符从高到低进行计算
下面是正则表达式从高到低的运算优先级:
转义符号
\
圆括号和方括号
()
[]
限定符
*
+
?
{n}
{n,}
{n,m}
定位点/位置 和 序列/顺序
^
$
\任何元字符
任何字符——————————
简单字符匹配
[Pp]ython 匹配 "Python" 或 "pthon"
Jav[ac] 匹配 "Java" 或 "Javc"
[abcde] 匹配中括号内的任意一个字母
[0-9] 匹配 0、1、2、3、4、5、6、7、8、9 任何数字
[a-z] 匹配任何小写字母
[A-Z] 匹配任何大写字母
[a-zA-Z0-9] 匹配任何字母及数字
[^love] 匹配除了 l、o、v、e 这些字母以外的所有字符
[^0-9] 匹配除了数字外的字符——————————
预定义字符和特殊字符
预定义字符:
\d 匹配所有的十进制数字 也就是 0 ~ 9
\D 匹配所有的非数字 包含下划线
\s 匹配所有空白字符 例如 空格 湖泊 TAB 键等
\S 匹配所有非空白字符 包含下划线
\w 匹配所有字母、汉字、数字 即 a 到 z 和 A 到 Z 以及 0 到 9
\W 匹配所有非字母、汉字、数字 包含下划线
/A 匹配字符串开始
/z 匹配字符串结束
/Z 匹配字符传结束 如果存在换行 则只匹配到换行前的结束字符串
/G 匹配最后匹配完成的位置
/b 匹配一个单词边界 也就是指单词和空格间的位置 例如 'er\b' 可以匹配 "never" 中的 "er" 但不能匹配 "verb" 中的 "er"
/N 匹配非单词边界 "er/B" 能匹配 "verb" 中的 "er" 但不能匹配 "never" 中的 "er"
\n 匹配一个换行符 匹配一个制表符 等等
\t 等同于 \n特殊字符:
$ 匹配一行的结尾 必须放在正则表达式最后面
^ 匹配一行的开头 必须放在正则表达式最前面
* 前面的那个字符可以出现 0 次或多次 0 ~ 无限
+ 符号前面的字符可以出现 1 次或多次 1 ~ 无限
? 将 贪婪模式 切换为 勉强模式 前面的字符可以出现 0 次或 1 次 也称之为非贪婪模式或惰性匹配
+? + 或 * 后跟 ? 表示非贪婪匹配 即尽可能少的匹配 这里的 +? 表示重复任意次但尽可能少重复
*? 表示匹配任意数量的重复 但是在能使整个匹配成功的前提下使用最少的重复 例如 a.*?b 匹配最短的以 a 开始以 b 结束的字符串 例如 "aabab" 这个字符串会匹配 "aab" 和 "ab"
. 匹配除了换行符 "\n" 之外的任意单个字符
| 两项都进行匹配
[] 代表一个集合
[abc] 表示能匹配其中的单个字符 a 和 b 和 c
[a-z0-9] 表示匹配指定范围的字符 可以在最前面加入 ^ 取反
[2-9] [1-3] 还能够组合匹配
{} 用于标记前面的字符出现的频率
{n,m} 代表前面字符最少出现了 n 次最多出现了 m 次
{n,} 代表前面字符最少出现 n 次而最多不受限制
{,m} 代表前面字符最多出现 n 次最少不受限制
{n} 前面的字符必须出现了 n 次——————————
匹配方法和匹配对象的方法
匹配方法:
match() 在目标文本的开头进行匹配
search() 在整个目标文本中进行匹配
findall() 扫描整个目标文本 返回所有与规则匹配的子串组成的列表 如果没有匹配的返回空列表
finditer() 扫描整个目标文本 返回所有与规则匹配的子串组成的迭代器
fullmatch() 要求目标文本要完全匹配规则 否则返回 None
sub() 将与规则匹配的子串替换为其她文本
split() 从与规则匹配的子串进行切割 返回切割后子串组成的列表匹配对象的方法 对匹配到的对象使用:
group() 用于查看指定分组匹配到的内容
groups() 返回一个元组 组内为所有匹配到的内容
groupdict() 返回一个字典 包含分组的键值对 需要为分组命名
start() 返回匹配到的内容在文本中的起始索引 end 返回匹配到的内容在文本中的结束索引 span 返回由起始索引和结束索引组成的元组