RapidMiner数据挖掘2 —— 初识RapidMiner
本节由一系列练习与问题组成,这些练习与问题有助于理解多个基本概念。它侧重于各种特定步骤,以进行直接的探索性数据分析。因此,其主要目标是测试一些检查初步数据特征的方法。大多数练习都是关于图表技术,通常用于数据挖掘。
为此,我们将使用RapidMiner软件。请求的工作包括发现应用程序的图形用户界面(GUl),以及检查和处理示例数据集的不同元素。本支持文件中提供的补充解释旨在定义:
0. 文本说明
所有应用程序操作的名称和编程说明都以黄色背景书写,问题以蓝色背景书写,以方便他们在文本中识别。 在整个教程中中,请逐步遵循拟议序列中的所有说明,并确保获得预期结果,然后再继续下一部分或问题。
通过在Ubuntu中运行RapidMiner工作环境开启软件,如下所示:
a.打开一个终端窗口,并在您的工作区中创建一个新目录:
mkdir Rapidb.初始化RapidMiner应用程序类型:
SETUP RAPIDMINER9c.要在同一终端窗口中运行RapidMiner,请输入指令:
RapidMinerGUI如果要求,请接受许可证条款,但不要要求更新当前版本。
1. 初识RapidMiner
在 Welcome to RapidMiner Studio!窗口,在Start选项卡上,单击Blank Process(左上角)。

1.1 初始界面按钮的功能
RapidMiner GUI(图形用户界面)然后在屏幕上显示多个子窗口,左上角显示8个菜单 (File, Edit, Process, View, Connections, Settings, Extensions, and Help) ,下面显示10个按钮图标(从左到右)。如果在几秒钟内将鼠标放在这些图标上,将显示一个简短的功能描述。
问题1:说明这些按钮的功能。
![]()
其中一些功能将在稍后应用,随着您的进步,它们的含义将变得清晰。
1.2 了解视图
选择 Settings → Preferences → User Interface 菜单。在显示的 RapidMiner Studio Preferences 窗口中验证以下项目未选中:
Automatically wire operator input ports 和 Automatically wire operatin output ports。如果有必要就取消选中这些项目,请单击OK,或者如果不需要,请关闭 RapidMiner Studio Preferences窗口。请注意,RapidMiner可以显示两个不同的接口,称为视图(由GUl中间顶部的两个按钮标识):Design 视图和 Results视图。也可以使用views菜单选择这些视图来选择views项。本教程中不会使用其他视图,即Tuzbo Prep、Auto Model和Deployments。
视图是一组预配置的应用程序组件,组织在一个单独的GUI中。请不要关闭任何显示的子窗口
问题2:检查 Design视图屏幕,从左上到右,从左下到右列出显示的子窗口名称。

问题3:检查Results视图,并从左上至右和从左下至右列出显示的子窗口名称。
1.3 Operators —— Read CSV
在Design视图中的Operators子窗口的搜索行中键入Read。在显示的列表中确定要读取逗号分隔值(csv)文件的operator:Data Access → Files → Read → Read CSV.
问题4:双击Read CSV operator或将其拖放到Process子窗口中。描述发生了什么?
在Read CSV 这个operator 的Parameters子窗口中验证以下项目已选中:use quotes, parse numbers, first row as names, read not matching values as missing。将Iris_Data Missing.txt复制到RapidMiner目录中的。
然后单击Read CSV这个operator 的Parameters子窗口顶部的Import Configuration Wizard…按钮。
确保在Import Data -Select the data location的Select the data location底部选择了All Files。在复制的目录中选择Iris_Data Missing.txt数据文件。然后单击NEXT按钮。
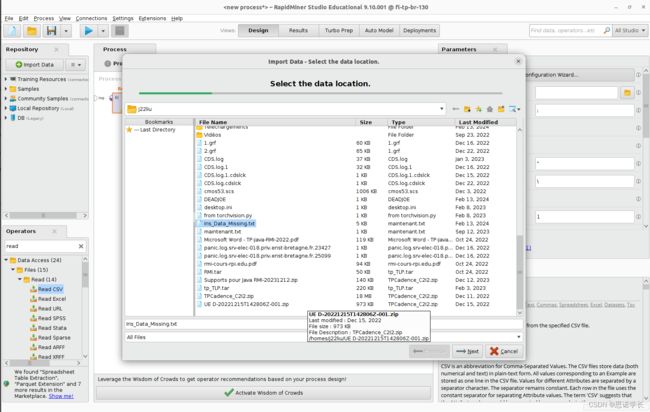
问题5:显示多少列,指示的文件编码格式是什么?
5列,UTF-8格式
更改显示的文件 encoding format 为 UTF-8,并在Import Data - Specify your data format window 窗口选择 Comma ","
问题6:每一列都是什么样的?
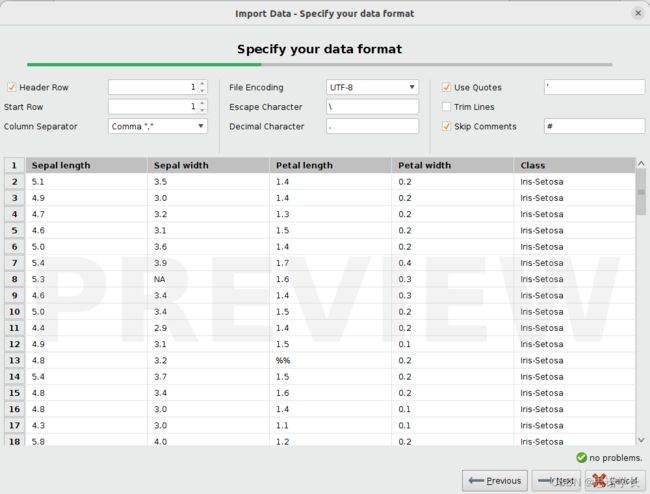
问题7:关于读取的数据是否有其他指示?
如果显示了5个数据列,请单击NEXT。观察显示的数据表中发生了哪些变化。
问题8:检查(通过向下滚动)显示的表,以验证集合中是否有任何缺失数据的指示符。如果是这样的话,可以确定哪些指标?
,
NA
%%
NAN问题9:描述在属性名称下面添加了什么?

polynominal请注意,在每个列中,除了属性名之外,还有一个数据类型标签。修改数据类型标签如下(从左到右),在每个列的右上角显示箭头的菜单来选择:对于前4列Change Type > real 替换polynominal,在第5个Change role中,然后在显示的Change role窗口中 写入label 。单击Import Data - Format your columns窗口右下角的Ignore errors 。单击Finish按钮。

通过单击Read CSV的out端口(鼠标左键),然后单击res端口(Process右上方的res),将Read CSV操作符的out端口连接到Process子窗口右上方的res端口。
1.4 运行数据模型并进行初步分析
使用运行按钮运行该进程(或F11)。Results视图是自动显示(如果不是,在Read CSV操作符上单击鼠标右键并选择Show Exampleset Result选项)。
问题10:描述在Results视图的 Example Set (Read CSV) 选项卡中选择Data面板(左上方)时显示的内容。
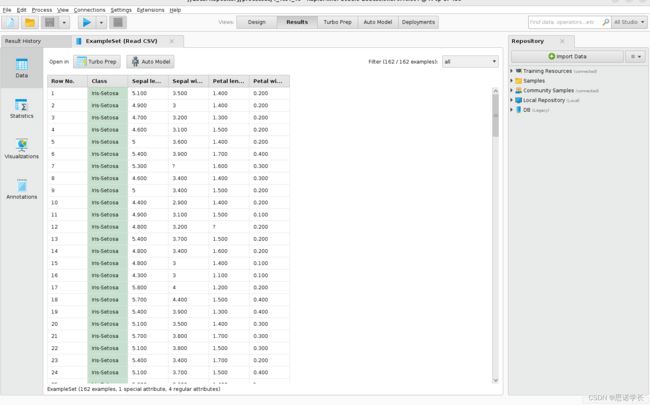
问题11:检查Data面板显示的表,以查看构成数据集的记录。读取了多少数据记录?当你检查记录时,是否有缺失数据的迹象?如果是这样的话,是什么?
162条记录,有缺失的值,是?
使用所显示表格右上方的Filter按钮删除那些没有缺失值的数据记录(选择no_missing_attributes),以及那些有缺失属性(选择missing_attributes)和缺失标签(选择missing_labels)的数据记录。

问题12:每种类型显示多少条记录?
no_missing_attributes:150
missing_attributes:12
missing_labels:0
no_missing_labels:162
问题13:描述“统计”面板显示的内容。这是关于什么的?

问题14:在此数据集的情况下,有哪些可能的方法来处理缺失值?
用平均值替代?,或者直接删除带有缺失值的数据1.5 Operators —— Filter
返回Design视图。在Operators子窗口搜索字段中键入Filter。在显示的列表中,双击或拖放过Filter Examples到过程子窗口(Blending → Examples → Filter → Filter Examples)。将Read CSV运算符的输出连接到Filter Example运算符的输入。

问题15:应在FilerExamples操作符的Parameters子窗口 (屏幕右侧)中选择哪个condition class,以保持数据记录没有缺失值?
no_missing_attributes

点击您的选择并运行该过程。验证过滤值的结果数量和特征。

1.6 Operators ——WriteExcel
在Design视图的Operators搜索字段中键入Write。双击或拖移显示列表的WriteExcel操作符到Process子窗口。将FilterExamplet操作符的exa输出连接到WriteExcel的inp输入和将write Excel运算符的第一个trh输出连接到Process子窗口右上方的res端口。
问题16:描述已组装的完整过程。

检查右侧的Write Excel操作符Parameters子窗口,以确保文件格式file format为xls (如果使用xlsx,生成的文件可能无法读取) ,编码encoding为UTF-8。单击文件夹图标(excel file那一行),选择生成的文件(命名为Iris_Data.xls) 将保存在其中的目录。验证Open Fil窗口底部显示的文件类型是excel file (*xls) ,输入文件名并单击Open。
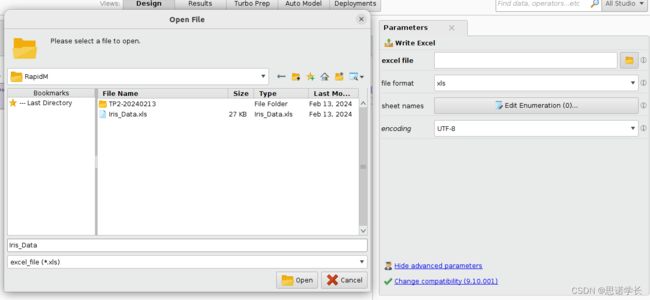
然后运行该过程。此外,检查文件是否已正确创建,并使用Libre Office软件读取该文件。
你目前正探索分析的是著名的lris数据集。这是一个多变量数据集的三个鸢尾花种,包含50个例子,每种类型的花和4测量属性每个记录。因此,数据集的每个记录包含一个类定义(lris-setosa、Iris-versicolor或lris-virginica) 和4个属性均以厘米为单位 :尊片长、萼片宽、花瓣长和花瓣宽。
1.7 保存进程process
一旦一个进程被定义并正常工作,您就可以保存它以供进一步使用。要保存此过程,您可以使用File菜单 (Design视图左上方)的Save process as...选项,或者选择Save按钮 (Design视图左上方菜单栏下方) 的Save process as...选项。
2. 利用RapidMiner的图表分析数据
删除Design视图中的当前进程及其关联的Results选项卡,只需要创建一个新进程 (File menu—>New Process) 。读取之前创建的Iris_data.xls文件。为此,请使用Read Excel操作符并激活其导入配置向导。应用与Read CSV所示相同的参数,连接相应的端口,然后运行该进程。如果您不使用导入配置向导和给定的参数,或者不完成导入配置向导,则加载的文件的值将不正确。
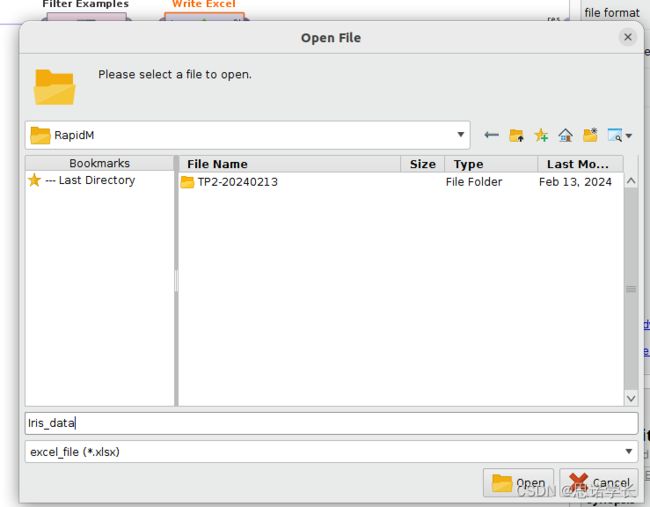
点击Open后,点击NEXT,然后在点击Finish。在Process里连接相应的端口。
2.1 认识图像显示界面
问题17:在Result视图中,选择Example Set (Read Excel) 选项卡的Visualizations面板,然后单击屏幕左上方的Plot type按钮。描述显示的内容。
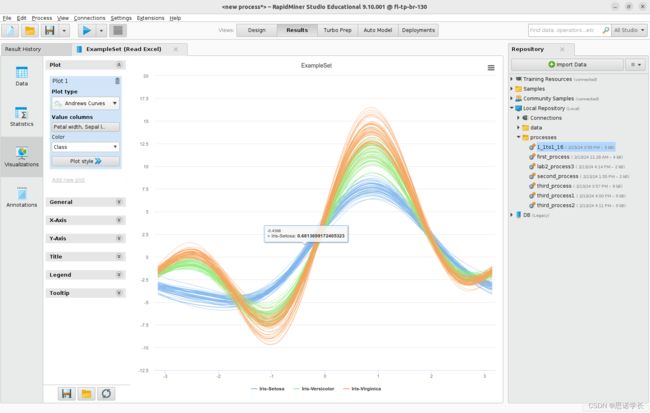
2.2 散射/气泡绘图仪scatter/Bubble
选择散射/气泡绘图仪scatter/Bubble,然后定义配置数据绘图仪的属性。首先指定x-Axis —>Sepal length,然后指定Value column —>Sepal length, Color —> -, size —> -
问题18:最初包含数据集的Sepal长度值有多少?图上显示了多少? 为什么?
最初是150个,但图上显示为15个,这是由于这个图像是缩略图,可以通过Jitter调整图像大小来
观测其他值。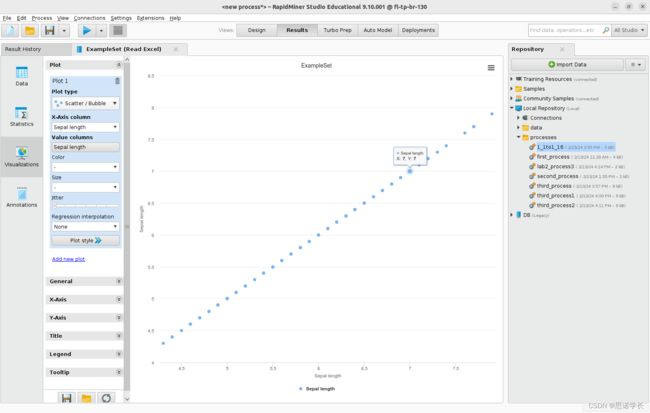
问题19:缓慢移动Jitter抖动滑块 (中间左侧)。这个结果和你之前的分析一致吗?
通过移动Jitter能够观察更多的点。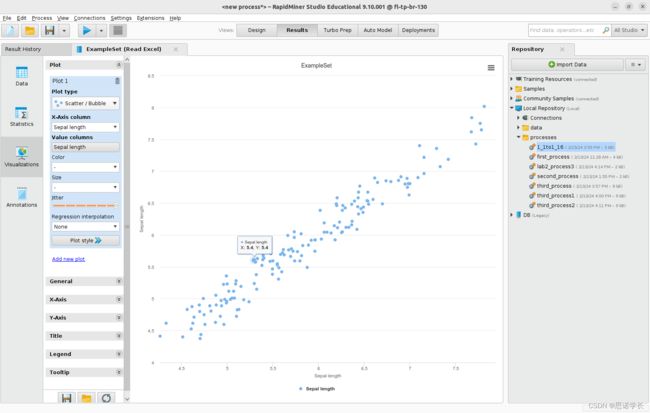
将抖动滑块Jitter返回到其初始位置。保留散射/气泡绘图仪scatter/Bubble并将Color参数更改为Class。可视化4个属性 (萼片长,萼片宽,花瓣长,花瓣宽)中的每一个,每次选择一个属性,同时分配给两个轴。
问题20:四个属性中的任何一个是否允许正确地分离三个Iris类(分离三种花)?
问题21:是否有可能使用一个属性清晰地可视化至少一个单独的类? 如果是这样的话,对应的类和属性是什么?
Petal width
问题22:将一个属性分配给x轴列,依次将其他三个属性分配给值列。留下Color —> Class, size —> -。有没有对应于同一类或不同类的叠加点? 怎么解释呢?
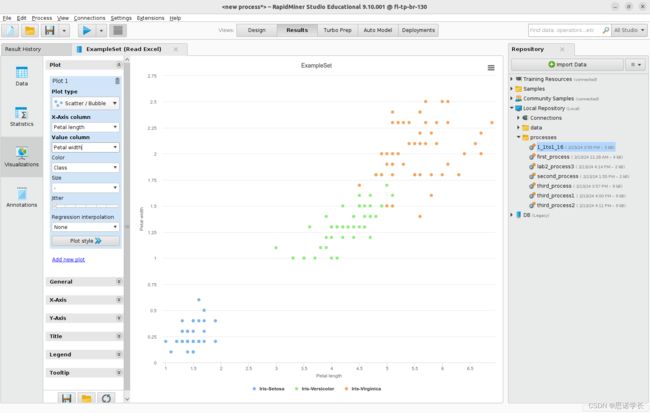
修改Scatter/Bubble散点图/气泡图,将X-Axis column > Class,值列分配每个属性的名称 (萼片长度、萼片宽度、花瓣长度和花瓣宽度Sepal length, Sepal width, Petal length, and Petalwidth) ,每次分配一个用于检验,Color > Class。可视化并比较四个图。
问题23:是否有可能使用一个属性清晰地可视化至少一个单独的类? 在该例子中对应的类和属性是什么? 将问题21的答案联系起来,并描述它们的不同之处。
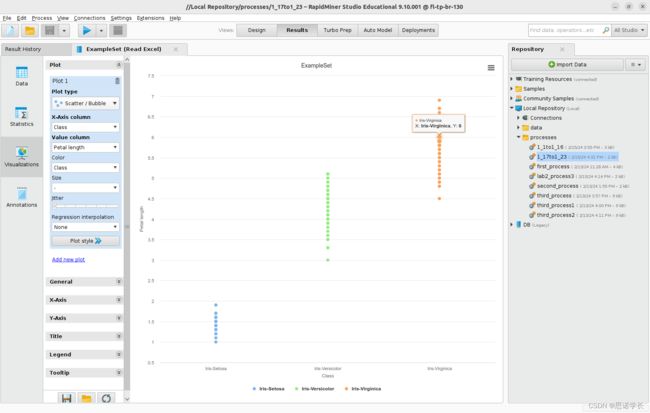
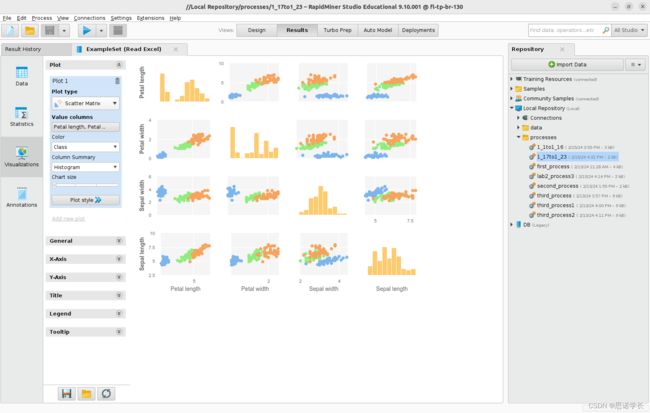
2.3 散射矩阵Scatter Matrix
将Plot type改为Scatter Matrix类型。显示的选项中至少需要有两个数值列Value columns。将所有属性放入Selected Attributed (按Ctrl键可以同时选择所有属性) 并分配Color > Class。
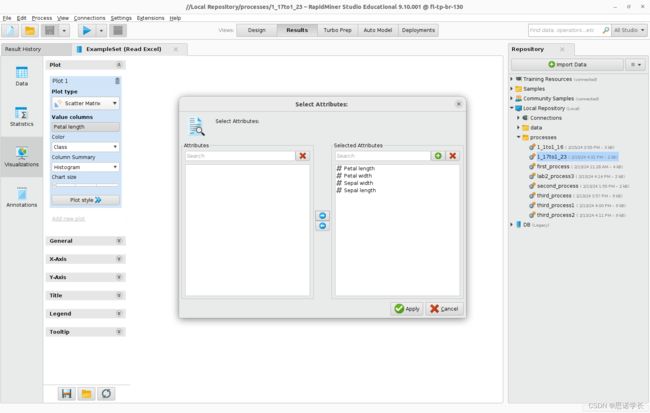
通过选择Histogram 作为Column Summary并移动Chart size滑块以增加其大小,可以修改显示的图。
问题23:根据散射矩阵的结果,是否可以清楚地分离三个lris。
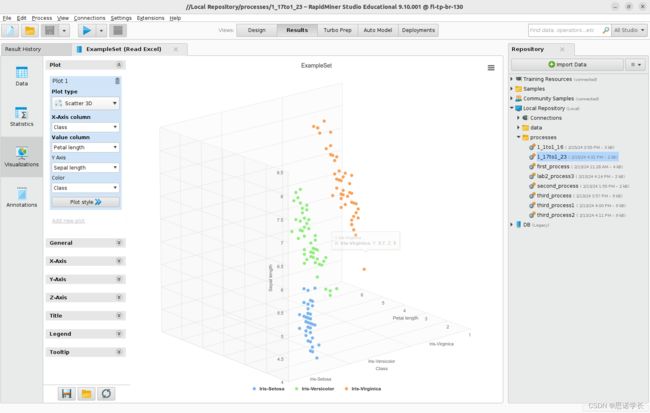
2.4 Scatter 3D
使用Scatter 3D(Plot type中)并定义相应的参数,以获得数据集的不同三维表示。
问题25:您是否能够确定能够补充2D数据探索洞察力的其他信息?
 2.5 再次分析散点图/气泡图scatter/Bubble
2.5 再次分析散点图/气泡图scatter/Bubble
再次选择散点图/气泡图scatter/Bubble类型并设置x-Axis column > Sepal length,Value column Class, Color > Class, size > Sepal width。找出这种类似气泡的表示给予的信息。
问题26:检查生成的图表,确定哪一个种类的唇瓣长度sepal length,变化最大,哪一个的唇瓣宽度sepal width变化较小,以及哪一个的唇瓣宽度sepal width变化最大?
Virginica唇瓣长度变化最大
Versicolor唇瓣宽度变化最小
Setosa唇瓣宽度变化最大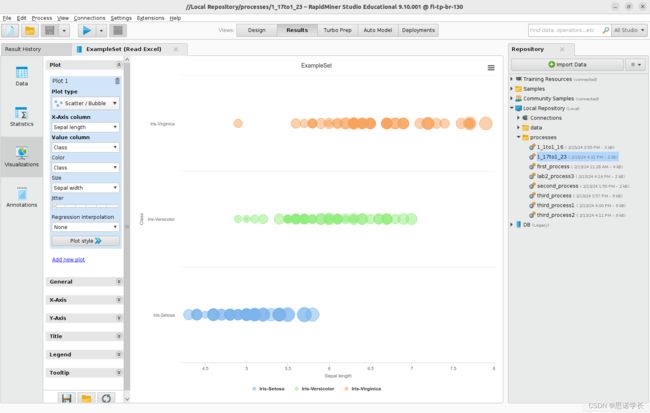
修改前一个图的一些参数:设置 Value column > Petal width,Size > Petal length.保持 x-Axis > Sepal length 和Color > Class.
问题27:观察生成的图,确定哪一个类的花瓣长度最短,哪一个类花瓣长度最大,哪一个类花瓣宽度最短。
Setosa花瓣长度最短,Virginica花瓣长度最大,Setosa花瓣宽度最短。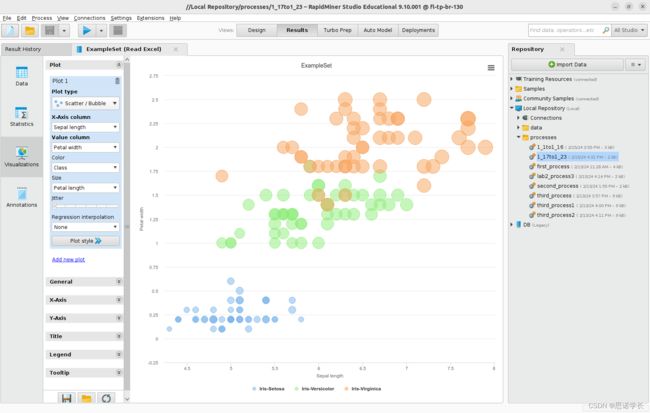
2.6 填充气泡Packed Bubble
在图类型Plot type按钮显示的选项中选择填充气泡Packed Bubble。设置以下参数: Value column —>sepal width, Name > -, Category > Class.
问题28:知道指定的颜色对应于数据集的三个已知类,描述和解释显示的图形。
这种图形类型用于以气泡的形式展示数据,每个气泡的大小可以代表数据点的值。
鸢尾花数据集通常包含三种鸢尾花(Iris setosa、Iris versicolor和Iris virginica)的150个样本
在图中,我们可以看到三种颜色的气泡:橙色、绿色和蓝色,这些颜色对应于三种不同的鸢尾花物种。
气泡上标有物种的名称,它们的大小可能与数据集中的某个值成比例,这个值可能是萼片长度、萼片宽度、花瓣长度或花瓣宽度。
视化图形显示的是每个类别(鸢尾花种类)的萼片宽度,并且相应的气泡按萼片宽度的大小进行了大小设置。
直观比较三种鸢尾花萼片宽度分布和典型值的视觉表示。紧凑气泡图布局有助于发现模式,例如哪些物种的萼片通常更大或更小,这可以通过代表每个物种的气泡的平均大小来识别。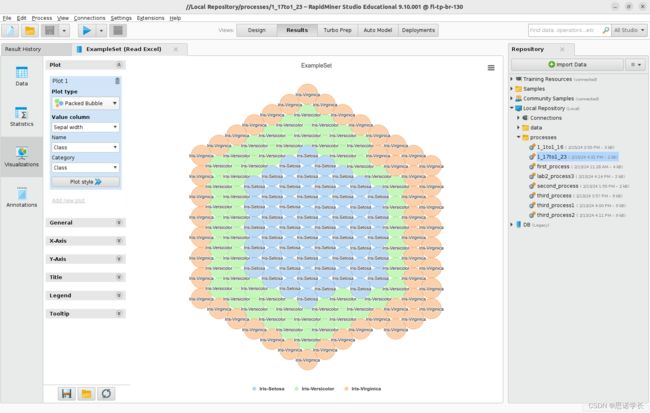
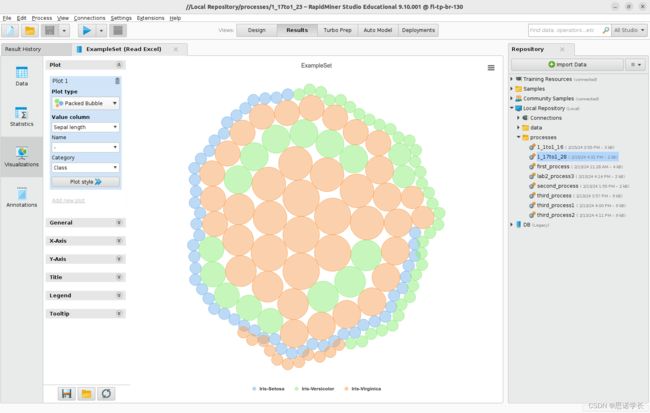
要观察填充气泡图的其他配置,请Value column —>Sepal length
问题29:现在如何解释填充气泡Packed Bubble?
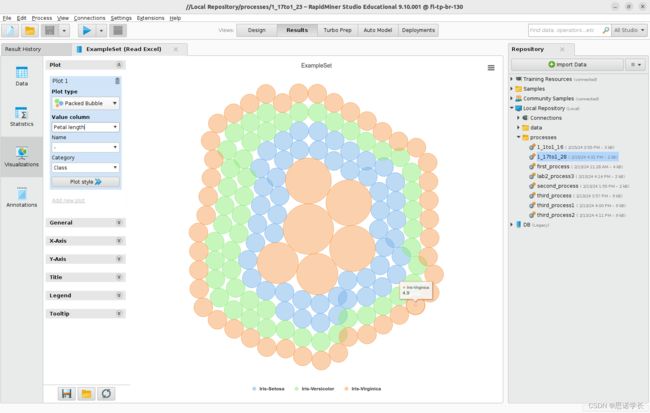
观察”填充气泡”图的第三个显示,修改Value column >Petal length.,Category >-
问题30:总结填充气泡Packed Bubble图的特征和用途。
2.7 Parallel Coordinates(平行坐标)
在一个二维空间上可视化超过三个属性是一项复杂的任务。另一种技术是将数据集的多个属性投影到平行轴上。
为了达到这个目的,需要将属性的名称分配给x轴,而属性的值则表示在y轴上。一个代表相应类别的彩色线条将一条记录的各个点连接起来。
在Plot type(图表类型)的选项中选择Parallel Coordinates(平行坐标)。如果没有至少两个属性,可能会显示错误信息,提示至少需要两个属性来创建图形。点击“Value columns”(值列)下的按钮(这里应该已经有一个属性名称),然后分别选择其他三个属性(在点击选择每个属性前按下Ctrl键)。

将Color > Class(类别)。这样设置后,每个类别的数据记录将以不同颜色的连线在平行坐标图中表示。

问题31:从这个表象可以得到什么样的结论?
2.8 Deviation
选择Deviation来可视化不同LRIS类的每个属性的平均值和标准偏差。设置Group by > class
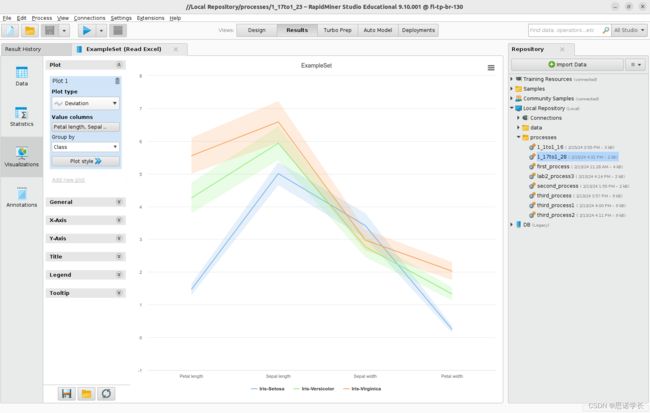
问题32:哪些属性显示最小的标准差,哪些类别?
2.9 直方图Histogram
设置直方图:为了可视化每个属性的直方图,请选择Histogram(直方图)作为“Plot type”(图表类型)。确保一次只显示一个属性的直方图。将“Color”(颜色)设置为“-”,表示不通过颜色区分类别,然后点击“Value columns”(值列)下的按钮来选择对应的属性。将“Number of Bins”(分组数)设置为20,这是直方图中柱状分组的数量。也可以同时可视化所有四个属性的直方图。此外,为了显示每个属性对于三个类别的直方图,需要将“Color”(颜色)设置为“Class”(类别)。
问题33:识别哪些属性具有最高和最低的分布宽度。指出哪些分布是不连续的。
最高和最低的分布宽度:黄色(Virginica)蓝色(setosa)。都不连续


问题34:统计面板与观察结果的一致性,检查“Example Set (Read Excel)”(示例集(读取Excel))标签中的“Statistics”(统计)面板为每个属性提供的详细信息。然后,将这些结果的变异性与问题33中指出的观察结果进行比较。判断这两组结果是否一致。
结果一致
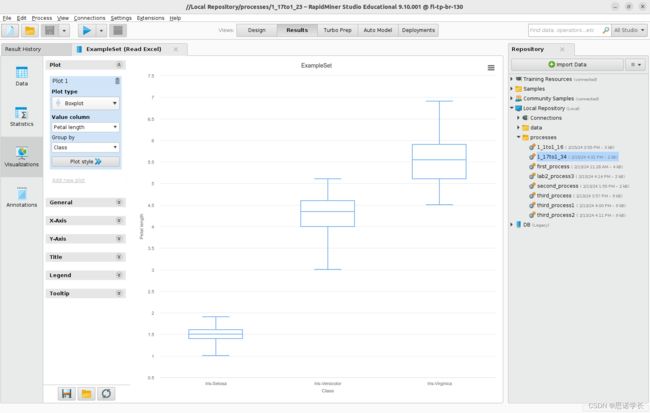
2.10 Boxplot(箱形图)
设置箱形图:在Plot type(图表类型)选项中选择Boxplot(箱形图)。为了同时显示四个属性,请将Group by > -,表示不进行分组,然后在点击Value columns(值列)下的按钮后(可能已经有一个属性被分配了),按住Ctrl键选择每个属性。
箱形图则用于展示数据的中位数、四分位数和异常值,这些都是数据分析中的重要工具。
箱形图(Boxplot),也称为盒须图或箱线图,是一种标准化的方式来展示数据分布的图表。这个图表可以很方便地展示数据的中位数、四分位数和异常值等统计量。下面是这些统计量的定义:
中位数(Median):数据集排序后位于中间位置的值。如果数据集有奇数个数据点,中位数就是中间那个数;如果有偶数个数据点,则中位数是中间两个数的平均值。在箱形图中,中位数通常由箱子内的一条线表示。
四分位数(Quartiles):
第一四分位数(Q1,下四分位数):位于数据集下25%位置的值。它将数据集中最小的25%的数据与其余部分分开。
第三四分位数(Q3,上四分位数):位于数据集上25%位置的值。它将数据集中最大的25%的数据与其余部分分开。
第二四分位数(Q2):其实就是中位数。
箱形图中的“箱子”部分展示了从Q1到Q3的范围,也就是中间50%的数据范围。
异常值(Outliers):通常被定义为小于Q1减去1.5倍的四分位距(IQR,即Q3减去Q1)或大于Q3加上1.5倍IQR的值。在箱形图中,这些值通常由单独的点或星号表示,位于“须”之外。
须(Whiskers):箱形图的“须”部分延伸至数据的最小值和最大值,但不包括异常值。在许多箱形图的构造方法中,须延伸至Q1减去1.5倍IQR和Q3加上1.5倍IQR的范围内的最小值和最大值。
通过分析箱形图,可以快速识别数据的分布模式,包括对称性、偏斜程度以及是否存在潜在的异常值。

问题35:属性值范围的大小,哪些属性有最大和最小的值范围?
都有
问题36:属性的分布是否倾斜,哪些属性显示出倾斜的分布?
Petal length
prtal width
倾斜的分布是指数据分布不对称,数据的一侧尾部更长,另一侧尾部更短。在统计学中,分布的倾斜方向通常根据长尾部分所在的方向来定义:
在箱形图中,倾斜可以通过观察中位数(箱形图中的线)与箱子(代表四分位数范围)的位置关系来判断。如果中位数线偏向箱子的一端,那么分布可能是倾斜的。此外,如果须线(代表数据范围的线)的一侧明显更长,这也是倾斜的一个迹象。
在直方图中,倾斜通常通过观察柱形的高度变化来识别。如果柱形在一侧逐渐变高,而在另一侧突然降低,这可能表明分布是倾斜的。
倾斜度是数据分布的一个重要特性,因为它影响数据的平均值、中位数和众数之间的关系,并可能影响统计测试和分析结果的解释。
问题37:哪些属性显示某种程度上的均衡分布?
分别可视化数据集中四个属性的箱线图,设置Group by →Class。观察四个属性中每个属性的单独结果。
问题38:哪一个属性可以用来标识一个类?
2.11 Bell Curve
在 Plot type按钮的选项中选择Bell Curve ,以显示数据集属性的估计近似正态分布。设置Color → Class.分别可视化估计的正态分布。
问题39:验证是否存在可以使用一个属性预测的类。哪个类和属性?为什么?
PL,PW
2.12 安德鲁斯曲线(Andrews Curves)
在Plot type按钮的选项中选择安德鲁斯曲线(Andrews Curves),可将每个观测值可视化 为属性集在曲线上的投影。将显示一条错误信息,提示由于必须选择至少两个数字列,因此无法创建绘图设置Color >Cass。 然后将建议的属性集可视化。
安德鲁斯曲线(Andrews Curves)是一种数据可视化技术,用于将每个观察结果作为属性集在曲线上的投影来可视化。这种方法特别适用于探索和识别数据集中的模式和潜在异常值。在使用安德鲁斯曲线时,每条曲线代表数据集中的一行,而曲线的形状由该行中的数值属性决定。
问题40: 选择Sepal length和Sepal width(从上到下依次选择)作为数值列Value columns。是否有任何曲线看起来与其他曲线不同,可以确定为潜在异常值?
你会得到一组曲线,每条曲线代表数据集中的一个观察结果。在这种设置下,你需要寻找那些与其他曲线明显不同的曲线,这些曲线可能代表潜在的异常值。异常值的曲线可能会在形状、振幅或频率上有显著差异。
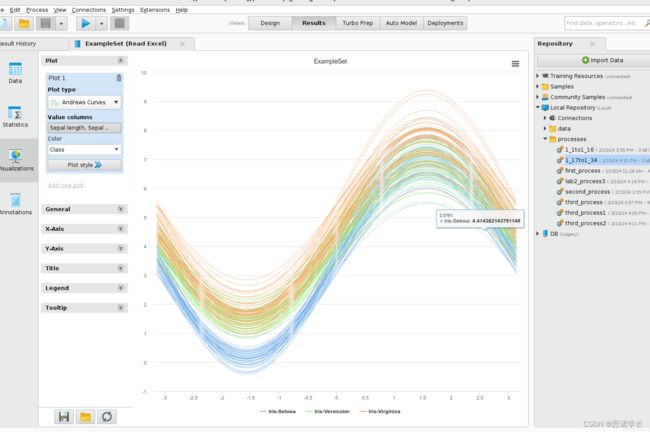
问题41: 颠倒所选属性的顺序,首先分配 Sepal width,然后分配 Sepal length 作为值列。与 1.40 的结果相比,有哪些修改?
这种变化影响了曲线的构造方式,因为安德鲁斯曲线是基于属性值的函数来生成的。改变属性的顺序会改变这些函数的组成部分,从而改变曲线的外观。

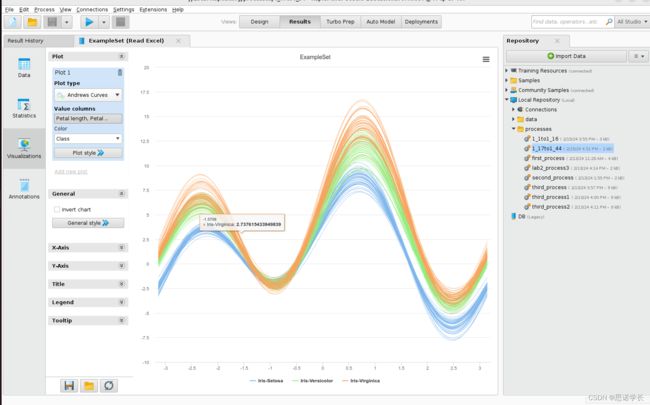
问题42:选择花瓣长度Petal length 与花瓣宽度 petal width(从上到下的顺序)作为value columns值列。考虑到可能会识别出异常值和不相干的类别,描述这种表示方法。

问题43:颠倒所选属性的顺序,首先指定花瓣宽度 Petal width ,然后指定花瓣长度Petal length作为Value columns值列。与 1.42 的结果相比,有哪些修改?

问题44:在之前的表示中,添加Sepal width 和Sepal lengthas花瓣宽度和花瓣长度属性作为Value columns值列。如何解释曲线的变化?
3.Operators —— Aggregate
3.1 聚合运算符(Aggregate)的功能
聚合运算符(Aggregate)在数据处理和分析中扮演着非常重要的角色,其主要功能是对一组值执行计算,从而产生单个值。聚合运算通常用于统计分析、数据挖掘、数据库管理等领域,以便对数据集进行概括性的描述或提取有价值的信息。以下是聚合运算符的一些主要功能和应用:
a.求和(Sum):对一组数值进行加总,得到它们的总和。
b.平均值(Average):计算一组数值的平均数,反映这组数值的中心点。
c.计数(Count):计算一组数据中的元素数量,可以是总数也可以是满足特定条件的元素数量。
d.最大值(Max)和最小值(Min):找出一组数据中的最大值和最小值,用于了解数据的范围或极值。
e.标准差(Standard Deviation)和方差(Variance):计算数据的标准差和方差,用于衡量数据的离散程度。
f.分组(Grouping):在执行聚合操作之前,通常会根据一个或多个属性将数据分组,然后在每个分组内部独立地执行聚合操作。这允许用户对数据集进行细分分析。
g.复杂统计(Advanced Statistics):在一些高级应用中,聚合运算符也可以用来执行更复杂的统计计算,如百分位数、累积分布等。
聚合运算符的使用使得用户能够从大量数据中快速提取关键信息和统计指标,从而支持决策制定、趋势分析、性能评估等多种应用场景。在数据库查询语言(如SQL)中,聚合函数是构建复杂查询和报告的基础。在数据分析和数据科学领域,聚合运算同样是数据预处理和特征工程中不可或缺的一部分。
3.2 具体操作
将聚合运算符Aggregate (Blending > Table > Grouping > Aggregate) 添加到Design 视图中。将聚合运算符Aggregate的exa输入端口连接到ReacExcel运算符的输出端口,将exa输出端口连接到Process子窗口的第一个res端口
在聚合运算符Aggregate参数Parameters子窗口中,单击聚合属性aggregation attributes右侧的Edit List按钮。在显示的Edit Parameter List:aggregation attributes窗口中选择#Petal length作为aggregation attribute,并选择count作为aggregation function。然后单击应用APPLY按钮。这意味着将对Petal length属性进行计数操作,以统计其出现的次数。
接下来,在Aggregate operator的 Parameters子窗口中,单击group by attributes标签右侧的Select Attributes按钮。在显示的Select Attributes:group by attributes窗口中,选择#Patal length 到Selected attribute中,方法是首先在Attributes列的左侧选择它,然后单击带有指向右侧箭头的蓝色按钮。然后单击应用Apply按钮。与前文描述的聚合属性一致。
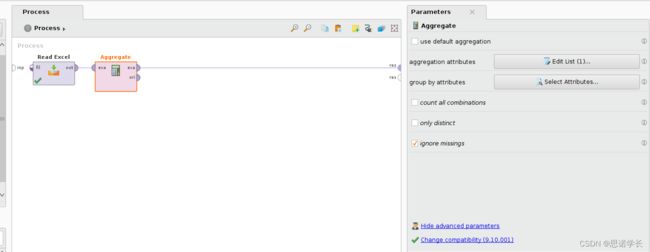
问题45:运行该过程,确定有多少个不同的值与属性Petal length相关联,有多少个是单一的和重复的值,以及哪一个是重复最多的值。
43个,1.5

问题46: 在之前的设置中用花瓣宽度Petal width替换花瓣长度Petal length并运行流程。确定有多少不同的值与花瓣宽度 Petal width属性相关联,有多少是单一值和重复值,哪个是重复最多的值。
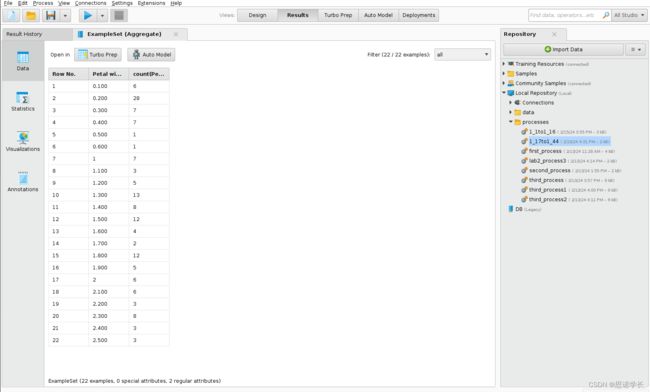
问题47:将之前设置中的花瓣宽度Petal width 替换为花瓣长度Sepal length,然后运行程序,找出与花瓣长度Sepal length,属性相关的不同值有多少,其中有多少是单一值和重复值,以及哪个值重复最多。

问题48: 在之前的设置中用萼片宽度Sepal width替换萼片长度Sepal length并运行流程。
确定有多少不同的值与花瓣宽度Sepal width属性相关联,有多少是单一值和重复值,以及哪个是重复最多的值。
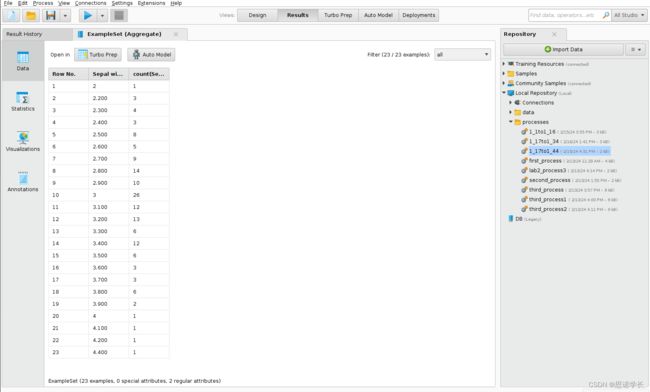
问题49:已知 lris 数据集中的四个属性中的每个属性都有 150 个值,那么像问题 1.45 至 1.48 中那样对这些值进行替代统计会有什么意义?
问题50: 考虑到各种测试工具之间的差异,总结一下本教程吧!