机器学习入门--门控循环单元(GRU)原理与实践
GRU模型
随着深度学习领域的快速发展,循环神经网络(RNN)已成为自然语言处理(NLP)等领域中常用的模型之一。但是,在RNN中,如果时间步数较大,会导致梯度消失或爆炸的问题,这影响了模型的训练效果。为了解决这个问题,研究人员提出了新的模型,其中GRU是其中的一种。
本文将介绍GRU的数学原理、代码实现,并通过pytorch和sklearn的数据集进行试验,最后对该模型进行总结。
数学原理
GRU是一种门控循环单元(Gated Recurrent Unit)模型。与传统的RNN相比,它具有更强的建模能力和更好的性能。
重置门和更新门
在GRU中,每个时间步有两个状态:隐藏状态 h t h_t ht和更新门 r t r_t rt。。更新门控制如何从先前的状态中获得信息,而隐藏状态捕捉序列中的长期依赖关系。
GRU的核心思想是使用“门”来控制信息的流动。这些门是由sigmoid激活函数控制的,它们决定了哪些信息被保留和传递。
在每个时间步 t t t,GRU模型执行以下操作:
1.计算重置门
r t = σ ( W r [ x t , h t − 1 ] ) r_t = \sigma(W_r[x_t, h_{t-1}]) rt=σ(Wr[xt,ht−1])
其中, W r W_r Wr是权重矩阵, σ \sigma σ表示sigmoid函数。重置门 r t r_t rt告诉模型是否要忽略先前的隐藏状态 h t − 1 h_{t-1} ht−1,并只依赖于当前输入
x t x_t xt。
2.计算更新门
z t = σ ( W z [ x t , h t − 1 ] ) z_t = \sigma(W_z[x_t, h_{t-1}]) zt=σ(Wz[xt,ht−1])
其中,更新门 z t z_t zt告诉模型新的隐藏状态 h t h_t ht在多大程度上应该使用先前的状态 h t − 1 h_{t-1} ht−1。
候选隐藏状态和隐藏状态
在计算完重置门和更新门之后,我们可以计算候选隐藏状态 h ~ t \tilde{h}_{t} h~t和隐藏状态 h t h_t ht。
1.计算候选隐藏状态
h ~ t = tanh ( W [ x t , r t ∗ h t − 1 ] ) \tilde{h}_{t} = \tanh(W[x_t, r_t * h_{t-1}]) h~t=tanh(W[xt,rt∗ht−1])
其中, W W W是权重矩阵。候选隐藏状态 h ~ t \tilde{h}_{t} h~t利用当前输入 x t x_t xt和重置门 r t r_t rt来估计下一个可能的隐藏状态。
2.计算隐藏状态
h t = ( 1 − z t ) ∗ h t − 1 + z t ∗ h ~ t h_{t} = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_{t} ht=(1−zt)∗ht−1+zt∗h~t
这是GRU的最终隐藏状态公式。它在候选隐藏状态 h ~ t \tilde{h}_{t} h~t和先前的隐藏状态 h t h_t ht之间进行加权,其中权重由更新门 z t z_t zt控制。
代码实现
下面是使用pytorch和sklearn的房价数据集实现GRU的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 加载数据集并进行标准化
data = load_boston()
X = data.data
y = data.target
scaler = StandardScaler()
X = scaler.fit_transform(X)
y = y.reshape(-1, 1)
# 转换为张量
X = torch.tensor(X, dtype=torch.float32).unsqueeze(1)
y = torch.tensor(y, dtype=torch.float32)
# 定义GRU模型
class GRUNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GRUNet, self).__init__()
self.hidden_size = hidden_size
self.gru = nn.GRU(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.gru(x)
out = self.fc(out[:, -1, :])
return out
input_size = X.shape[2]
hidden_size = 32
output_size = 1
model = GRUNet(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10000
loss_list = []
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
loss_list.append(loss.item())
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 可视化损失曲线
plt.plot(range(100), loss_list)
plt.xlabel('num_epochs')
plt.ylabel('loss of GRU Training')
plt.show()
# 预测新数据
new_data_point = X[0].reshape(1, 1, -1)
prediction = model(new_data_point)
print(f'Predicted value: {prediction.item()}')
上述代码首先加载并标准化房价数据集,然后定义了一个包含GRU层和全连接层的GRUNet模型,并使用均方误差作为损失函数和Adam优化器进行训练。训练完成后,使用matplotlib库绘制损失曲线(如下图所示),并使用训练好的模型对新的数据点进行预测。
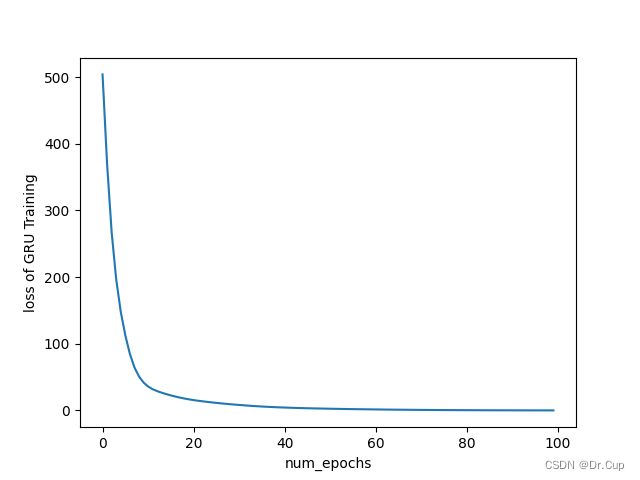
总结
GRU是一种门控循环单元模型,它通过更新门和重置门,有效地解决了梯度消失或爆炸的问题。在本文中,我们介绍了GRU的数学原理、代码实现和代码解释,并通过pytorch和sklearn的房价数据集进行了试验。