【优化器】(三) RMSProp原理 & pytorch代码解析
1.简介
在上一篇文章里,我们介绍了AdaGrad,引入了二阶动量来调整不同参数的学习速率,同时它的缺点就是不断地累加二阶动量导致最终学习率会接近于0导致训练提前终止,RMSProp主要针对这个问题进行了优化。
2.RMSProp
AdaGrad的二阶动量计算公式为
![]()
其中,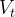 为当前时刻的二阶动量,
为当前时刻的二阶动量,![]() 是某一时刻的梯度,
是某一时刻的梯度,![]() 表示迄今所有梯度的平方和。问题就在于这个求和上,不断地累加导致学习率为0。
表示迄今所有梯度的平方和。问题就在于这个求和上,不断地累加导致学习率为0。
RMSProp在AdaGrad的基础上,对二阶动量的计算进行了改进:我想有历史梯度的信息,但是我又不想让信息一直膨胀,那么只要让历史信息一直衰减就好了。因此得到RMSProp的二阶动量计算公式:
![]()
其中,为当前step的二阶动量,![]() 为上一个step的二阶动量,
为上一个step的二阶动量, 为历史二阶动量的衰减率,这是二阶动量会更加注重于近期的梯度,同时也不会叠加到无穷大。
为历史二阶动量的衰减率,这是二阶动量会更加注重于近期的梯度,同时也不会叠加到无穷大。
3.思考
看到RMSProp的二阶动量公式会觉得似曾相识,这个是不是和SGD的Momentum很像呢?但是这两者其实是不同的东西。
不加Momentum的RMSProp更新梯度公式为:
![]()
![]()
加了Momentum的RMSProp更新梯度公式为:
![]()
![]()
可以看到RMSProp的惯性公式主要针对二阶动量,而Momentum的惯性公式主要针对更新的梯度参数,两者可以同时应用。
4.pytorch代码
RMSProp的伪代码流程如下,可以看到除了weight_decay和刚才我们说的Momentum之外,还多了一个centered的参数,其主要是对梯度通过估计方差来进行归一化,主要操作就是让二阶动量去减去平均梯度的平方,这样会使得结果更加平稳:

以下代码为pytorch官方RMSProp的代码。
def _single_tensor_rmsprop(
params: List[Tensor],
grads: List[Tensor],
square_avgs: List[Tensor],
grad_avgs: List[Tensor],
momentum_buffer_list: List[Tensor],
*,
lr: float,
alpha: float,
eps: float,
weight_decay: float,
momentum: float,
centered: bool,
maximize: bool,
differentiable: bool,
):
for i, param in enumerate(params):
grad = grads[i]
grad = grad if not maximize else -grad
square_avg = square_avgs[i]
if weight_decay != 0:
grad = grad.add(param, alpha=weight_decay)
is_complex_param = torch.is_complex(param)
if is_complex_param:
param = torch.view_as_real(param)
grad = torch.view_as_real(grad)
square_avg = torch.view_as_real(square_avg)
square_avg.mul_(alpha).addcmul_(grad, grad, value=1 - alpha)
if centered:
grad_avg = grad_avgs[i]
if is_complex_param:
grad_avg = torch.view_as_real(grad_avg)
grad_avg.mul_(alpha).add_(grad, alpha=1 - alpha)
avg = square_avg.addcmul(grad_avg, grad_avg, value=-1).sqrt_()
else:
avg = square_avg.sqrt()
if differentiable:
avg = avg.add(eps)
else:
avg = avg.add_(eps)
if momentum > 0:
buf = momentum_buffer_list[i]
if is_complex_param:
buf = torch.view_as_real(buf)
buf.mul_(momentum).addcdiv_(grad, avg)
param.add_(buf, alpha=-lr)
else:
param.addcdiv_(grad, avg, value=-lr)业务合作/学习交流+v:lizhiTechnology
如果想要了解更多优化器相关知识,可以参考我的专栏和其他相关文章:
优化器_Lcm_Tech的博客-CSDN博客
【优化器】(一) SGD原理 & pytorch代码解析_sgd优化器-CSDN博客
【优化器】(二) AdaGrad原理 & pytorch代码解析_adagrad优化器-CSDN博客
【优化器】(三) RMSProp原理 & pytorch代码解析_rmsprop优化器-CSDN博客
【优化器】(四) AdaDelta原理 & pytorch代码解析_adadelta里rho越大越敏感-CSDN博客
【优化器】(五) Adam原理 & pytorch代码解析_adam优化器-CSDN博客
【优化器】(六) AdamW原理 & pytorch代码解析-CSDN博客
【优化器】(七) 优化器统一框架 & 总结分析_mosec优化器优点-CSDN博客
如果想要了解更多深度学习相关知识,可以参考我的其他文章:
【损失函数】(一) L1Loss原理 & pytorch代码解析_l1 loss-CSDN博客
【图像生成】(一) DNN 原理 & pytorch代码实例_pytorch dnn代码-CSDN博客