Metropolis Hasting算法
Metropolis Hasting Algorithm:
MH算法也是一种基于模拟的MCMC技术,一个非常重要的应用是从给定的概率分布中抽样。主要原理是构造了一个精妙的Markov链,使得该链的稳态 是你给定的概率密度。它的优点,不用多说,自然是能够对付数学形式复杂的概率密度。有人说,单维的MH算法配上Gibbs Sampler差点儿是“无敌”了。
今天试验的过程中发现,MH算法想用好也还不简单,里面的转移參数设定就不是非常好弄。即使用最简单的高斯漂移项,方差的确定也是个头疼的问题,须要不同问题不同对待,多试验几次。当然你也能够始终选择“理想”參数。
还是拿上次的混合高斯分布来做模拟,模拟次数为500000次的时候,概率分布逼近的程度例如以下图。尽管几个明显的"峰"已经出来了,可是数值上还是 有非常大差异的。预计是我的漂移方差没有选好。感觉还是inverse sampling好用,迭代次数不用非常多,就能够达到相当的逼近程度。
试了一下MH算法,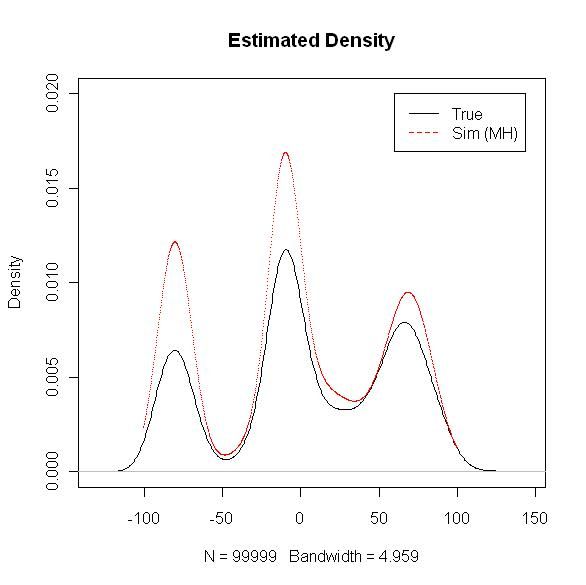
R Code:
p=function(x,u1,sig1,u2,sig2){
(1/3)*(1/(sqrt(2*pi)*15)*exp(-0.5*(x-70)^2/15^2)+1/(sqrt(2*pi)*11)*exp(-0.5*(x+80)^2/11^2)+1/(sqrt(2*pi)*sig1)*exp(-0.5*(x-u1)^2/sig1^2)+1/(sqrt(2*pi)*sig2)*exp(-0.5*(x-u2)^2/sig2^2))
}
MH=function(x0,n){
x=NULL
x[1] = x0
for (i in 1:n){
x_can= x[i]+rnorm(1,0,3.25)
d= p(x_can,10,30,-10,10)/p(x[i],10,30,-10,10)
alpha= min(1,d)
u=runif(1,0,1)
if (u<alpha){
x[i+1]=x_can}
else{
x[i+1]=x[i]
}
if (round(i/100)==i/100) print(i)
}
x
}
z=MH(10,99999)
z=z[-10000]
a=seq(-100,100,0.2)
plot(density(z),col=1,main='Estimated Density',ylim=c(0,0.02),lty=1)
points(a, p(a,10,30,-10,10),pch='.',col=2,lty=2)
legend(60,0.02,c("True","Sim (MH)"),col=c(1,2),lty=c(1,2))