Google Megastore分布式存储技术全揭秘
导读:本文根据Google最新Megastore论文翻译而来,原作者为Google团队,团队人员包括:Jason Baker,Chris Bond,James C.Corbett,JJ Furman,Andrey Khorlin,James Larson,Jean-Michel Léon,Yawei Li,Alexander Lloyd,Vadim Yushprakh。翻译者为国内知名IT人士。
在上个月举行的创新数据系统研讨会上(CIDR),Google公开了其Megastore分布式存储技术的白皮书。
Megastore是谷歌一个内部的存储系统,它的底层数据存储依赖Bigtable,也就是基于NoSql实现的,但是和传统的NoSql不同的是,它实现了类似RDBMS的数据模型(便捷性),同时提供数据的强一致性解决方案(同一个datacenter,基于MVCC的事务实现),并且将数据进行细颗粒度的分区(这里的分区是指在同一个datacenter,所有datacenter都有相同的分区数据),然后将数据更新在机房间进行同步复制(这个保证所有datacenter中的数据一致)。
Megastore的数据复制是通过paxos进行同步复制的,也就是如果更新一个数据,所有机房都会进行同步更新,因为使用paxos进行复制,所以不同机房针对同一条数据的更新复制到所有机房的更新顺序都是一致的,同步复制保证数据的实时可见性,采用paxos算法则保证了所有机房更新的一致性,所以个人认为megastore的更新可能会比较慢,而所有读都是实时读(对于不同机房是一致的),因为部署有多个机房,并且数据总是最新。
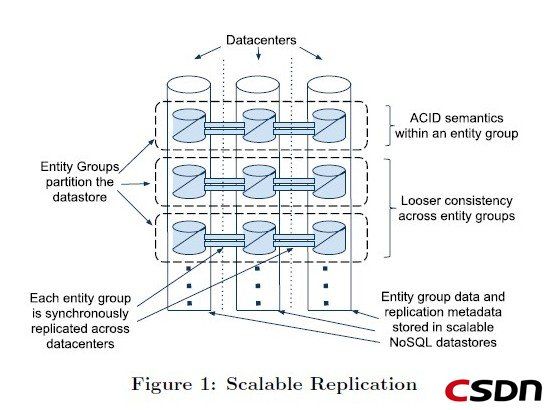
为了达到高可用性,megastore实现了一个同步的,容错的,适合长距离连接的日志同步器
为了达到高可扩展性,megastore将数据分区成一个个小的数据库,每一个数据库都有它们自己的日志,这些日志存储在NoSql中
Megastore将数据分区为一个Entity Groups的集合,这里的Entity Groups相当于一个按id切分的分库,这个Entity Groups里面有多个Entity Group(相当于分库里面的表),而一个Entity Group有多个Entity(相当于表中的记录)
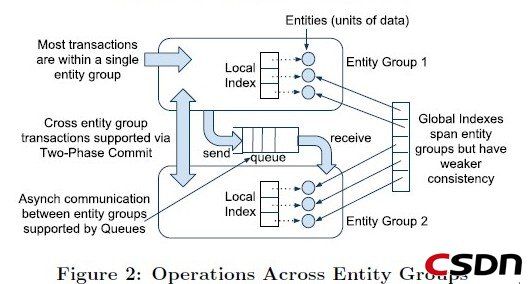
在同一个Entity Group中(相当于单库)的多个Entity的更新事务采用single-phase ACID事务,而跨Entity Group(相当于跨库)的Entity更新事务采用two-phase ACID事务(2段提交),但更多使用Megastore提供的高效异步消息实现。需要说明的一点是,这些事务都是在同一个机房的,机房之间的数据交互都是通过数据复制来实现的。
传统关系型数据库使用join来满足用户的需求,对于Megastore来说,这种模型(也就是完全依赖join的模型)是不合适的。原因包括
1.高负载交互性型应用能够从可预期的性能提升得到的好处多于使用一种代价高昂的查询语言所带来的好处。
2.Megastore目标应用是读远远多于写的,所以更好的方案是将读操作所需要做的工作转移到写操作上面(比如通过具体值代替外键以消除join)
3.因为megastore底层存储是采用BigTable,而类似BigTable的key-value存储对于存取级联数据是直接的
所以基于以上几个原因,Megastore设计了一种数据模型和模式语言来提供基于物理地点的细颗粒度控制,级联布局,以及申明式的不正规数据存储来帮助消除大部分joins。查询时只要指定特定表和索引即可。
当然可能有时候不得不使用到join,Megastore提供了一种合并连接算法实现,具体算法这里我还是没弄清楚,原文是[the user provides multiple queries that return primary keys for the same table in the same order; we then return the intersection of keys for all the provided queries.]
使用Megastore的应用通过并行查询实现了outer joins。通常先进行一个初始的查询,然后利用这个查询结果进行并行索引查询,这个过程我理解的是,初始查询查出一条数据,就马上根据这个结果进行并行查询,这个时候初始查询继续取出下一条数据,再根据这个结果并行查询(可能前面那个外键查询还在继续,使用不同的线程)。这种方法在初始查询数据量较小并且外键查询使用并行方式的情况下,是一种有效的并且具有sql风格的joins。
Megastore的数据结构介于传统的RDBMS和NoSql之间的,前者主要体现在他的schema表示上,而后者体现在具体的数据存储上(BigTable)。和RDBMS一样,Megastore的数据模型是定义schema中并且是强类型的。每一个schema有一个表集合,每个表包含一个实体集合(相当于record),每个实体有一系列的属性(相当于列属性),属性是命名的,并且指定类型,这些类型包括字符串,各种数字类型,或者google的protocol buffer。这些属性可以被设置成必需的,可选的,或者可重复的(一个属性上可以具有多个值)。一个或者多个属性可以组成一个主键。

在上图中,User和Photo共享了一个公共属性user_id,IN TABLE User这个标记直接将Photo和User这两张表组织到了同一个BigTable中,并且键的顺序(PRIMARY KEY(user_id,photo_id)?是这个还是schema中定义的顺序?)保证Photo的实体存储在对应的User实体邻接位置上。这个机制可以递归的应用,加速任意深度的join查询速度。这样,用户能够通过操作键的顺序强行改变数据级联的布局。其他标签请参考原文。
Megastore支持事务和并发控制。一个事务写操作会首先写入对应Entity Group的日志中,然后才会更新具体数据。BigTable具有一项在相同row/column中存储多个版本带有不同时间戳的数据。正是因为有这个特性,Megastore实现了多版本并发控制(MVCC,这个包括oracle,innodb都是使用这种方式实现ACID,当然具体方式会有所不同):当一个事务的多个更新实施时,写入的值会带有这个事务的时间戳。读操作会使用最后一个完全生效事务的时间戳以避免看到不完整的数据.读写操作不相互阻塞,并且读操作在写事务进行中会被隔离(?)。
Megastore 提供了current,snapshot,和inconsistent读,current和snapshot级别通常是读取单个entity group。当开始一个current读操作时,事务系统会首先确认所有之前提交的写已经生效了;然后系统从最后一个成功提交的事务时间戳位置读取数据。对于snapshot读取,系统拿到己经知道的完整提交的事务时间戳并且从那个位置直接读取数据,和current读取不同的是,这个时候可能提交的事务更新数据还没有完全生效(提交和生效是不同的)。Megastore提供的第三种读就是inconsistent读,这种读无视日志状态并且直接读取最后一个值。这种方式的读对于那些对减少延迟有强烈需求,并且能够容忍数据过期或者不完整的读操作是非常有用的。
一个写事务通常开始于一个current读操作以便确定下一个可用的日志位置。提交操作将数据变更聚集到日志,并且分配一个比之前任何一个都高的时间戳,并且使用Paxos将这个log entry加入到日志中。这个协议使用了乐观并发:即使有可能有多个写操作同时试图写同一个日志位置,但只会有1个成功。所有失败的写都会观察到成功的写操作,然后中止,并且重试它们的操作。咨询式的锁定能够减少争用所带来的影响。通过特定的前端服务器分批写入似乎能够完全避免竞争(这几句有些不能理解)[ Advisory locking is available to reduce the effects of contention. Batching writes through session affinity to a particular front-end server can avoid contention altogether.]。
完整事务生命周期包括以下步骤:
1.读:获取时间戳和最后一个提交事务的日志位置
2.应用逻辑:从BigTable读取并且聚集写操作到一个日志Entry
3.提交:使用Paxos将日志Entry加到日志中
4.生效:将数据更新到BigTable的实体和索引中
5.清理:删除不再需要的数据
写操作能够在提交之后的任何点返回,但是最好还是等到最近的副本(replica)生效(再返回)。
Megastore提供的消息队列提供了在不同Entity Group之间的事务消息。它们能被用作跨Entity Group的操作,在一个事务中分批执行多个更新,或者延缓工作(?)。一个在单个Entity Group上的事务能够原子性地发送或者收到多个信息除了更新它自己的实体。每个消息都有一个发送和接收的Entity Group;如果这两个Entity Group是不同的,那么传输将会是异步的。
消息队列提供了一种将会影响到多个Entity Group的操作的途径,举个例子,日历应用中,每一个日历有一个独立的Entity Group,并且我们现在需要发送一个邀请到多个其他人的日历中,一个事务能够原子地发送邀请消息到多个独立日历中。每个日历收到消息都会把邀请加入到它自己的事务中,并且这个事务会更新被邀请人状态然后删除这个消息。Megastore大规模使用了这种模式:声明一个队列后会自动在每一个Entity Group上创建一个收件箱。
Megastore支持使用二段提交进行跨Entity Group的原子更新操作。因为这些事务有比较高的延迟并且增加了竞争的风险,一般不鼓励使用。
接下来内容具体来介绍下Megastore最核心的同步复制模式:一个低延迟的Paxos实现。Megastore的复制系统向外提供了一个单一的,一致的数据视图,读和写能够从任何副本(repli ca)开始,并且无论从哪个副本的客户端开始,都能保证ACID语义。每个Entity Group复制结束标志是将这个Entity Group事务日志同步地复制到一组副本中。写操作通常需要一个数据中心内部的网络交互,并且会跑检查健康状况的读操作。current级别的读操作会有以下保证:
1.一个读总是能够看到最后一个被确认的写。(可见性)
2.在一个写被确认后,所有将来的读都能够观察到这个写的结果。(持久性,一个写可能在确认之前就被观察到)
数据库典型使用Paxos一般是用来做事务日志的复制,日志中每个位置都由一个Paxos实例来负责。新的值将会被写入到之前最后一个被选中的位置之后。
Megastore在事先Paxos过程中,首先设定了一个需求,就是current reads可能在任何副本中进行,并且不需要任何副本之间的RPC交互。因为写操作一般会在所有副本上成功,所以允许在任何地方进行本地读取是现实的。这些本地读取能够很好地被利用,所有区域的低延迟,细颗粒度的读取failover,还有简单的编程体验。
Megastore设计实现了一个叫做Coordinator(协调者)的服务,这个服务分布在每个副本的数据中心里面。一个Coordinator服务器跟踪一个Entity Groups集合,这个集合中的Entity Groups需要具备的条件就是它们的副本已经观察到了所有的Paxos写。在这个集合中的Entity Groups,它们的副本能够进行本地读取(local read)。
写操作算法有责任保持Coordinator状态是保守的,如果一个写在一个副本上失败了,那么这次操作就不能认为是提交的,直到这个entity group的key从这个副本的coordinator中去除。(这里不明白)
为了达到快速的单次交互的写操作,Megastore采用了一种Master-Slave方式的优化,如果一次写成功了,那么会顺带下一次写的保证(也就是下一次写就不需要prepare去申请一个log position),下一次写的时候,跳过prepare过程,直接进入accept阶段。Megastore没有使用专用的Masters,但是使用Leaders。
Megastore为每一个日志位置运行一个Paxos算法实例。[ The leader for each log position is a
distinguished replica chosen alongside the preceding log position's consensus value.] Leader仲裁在0号提议中使用哪一个值。第一个写入者向Leader提交一个值会赢得一个向所有副本请求接收这个值做为0号提议最终值的机会。所有其他写入者必需退回到Paxos的第二阶段。
因为一个写入在提交值到其他副本之前必需和Leader交互,所以必需尽量减少写入者和Leader之间的延迟。Megastore设计了它们自己的选取下一个写入Leader的规则,以同一地区多数应用提交的写操作来决定。这个产生了一个简单但是有效的原则:使用最近的副本。(这里我理解的是哪个位置提交的写多,那么使用离这个位置最近的副本做为Leader)
Megastore的副本中除了有日志有Entity数据和索引数据的副本外,还有两种角色,其中一种叫做观察者(Witnesses),它们只写日志,并且不会让日志生效,也没有数据,但是当副本不足以组成一个quorum的时候,它们就可以加入进来。另外一种叫只读副本(Read-Only),它刚刚和观察者相反,它们只有数据的镜像,在这些副本上只能读取到最近过去某一个时间点的一致性数据。如果读操作能够容忍这些过期数据,只读副本能够在广阔的地理空间上进行数据传输并且不会加剧写的延迟。
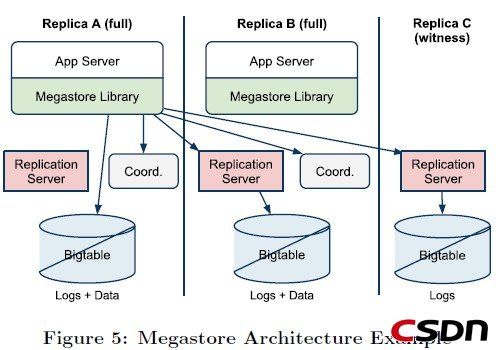
上图显示了Megastore的关键组件,包括两个完整的副本和一个观察者。应用连接到客户端库,这个库实现了Paxos和其他一些算法:选择一个副本进行读,延迟副本的追赶,等等。
Each application server has a designated local replica. The client library makes Paxos operations on that replica durable by submitting transactions directly to the local Bigtable.To minimize wide-area roundtrips, the library submits remote Paxos operations to stateless intermediary replication servers communicating with their local Bigtables.
客户端,网络,或者BigTable失败可能让一个写操作停止在一个中间状态。复制的服务器会定期扫描未完成的写入并且通过Paxos提议没有操作的值来让写入完成。
接下来介绍下Megastore的数据结构和算法,每一个副本存有更新和日志Entries的元数据。为了保证一个副本能够参与到一个写入的投票中即使是它正从一个之前的宕机中恢复数据,Megastore允许这个副本接收不符合顺序的提议。Megastore将日志以独立的Cells存储在BigTable中。
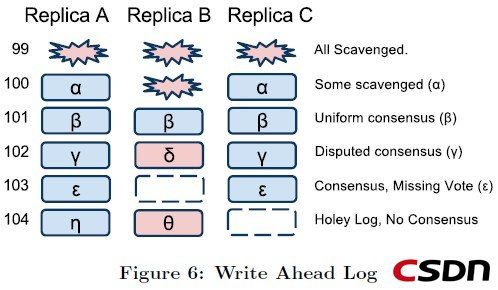
当日志的前缀不完整时(这个前缀可能就是一个日志是否真正写入的标记,分为2段,第一段是在写入日志之前先写入的几个字节,然后写入日志,第二段是在写入日志之后写入的几个字节,只有这个日志前缀是完整的,这个日志才是有效的),日志将会留下holes。下图表示了一个单独Megastore Entity Group的日志副本典型场景。0-99的日志位置已经被清除了,100的日志位置是部分被清除,因为每个副本都会被通知到其他副本已经不需要这个日志了。101日志位置被所有的副本接受了(accepted),102日志位置被Y所获得,103日志位置被A和C副本接受,B副本留下了一个hole,104日志位置因为副本A和B的不一致,复本C的没有响应而没有一致结果。
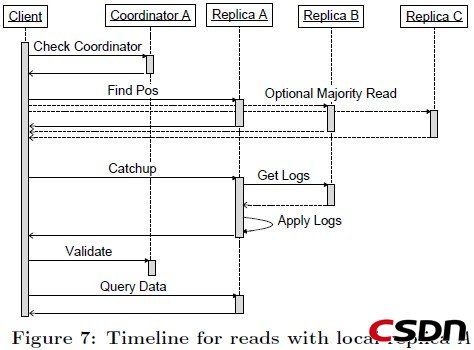
在一个current读的准备阶段(写之前也一样),必需有一个副本要是最新的:所有之前更新必需提交到那个副本的日志并且在该副本上生效。我们叫这个过程为catchup。
省略一些截止超时的管理,一个current读算法步骤如下:
1.本地查询:查询本地副本的Coordinator,判定当前副本的Entity Group是最新的
2.查找位置:确定最高的可能已提交的日志位置,然后选择一个己经将这个日志位置生效的副本
a.(Local read) 如果步骤1发现本地副本是最新的,那么从本地副本中读取最高的被接受(accepted)的日志位置和时间戳。
b.(Majority read)如果本地副本不是最新的(或者步骤1或步骤2a超时),那么从一个多数派副本中发现最大的日志位置,然后选取一个读取。我们选取一个最可靠的或者最新的副本,不一定总是是本地副本
3.追赶:当一个副本选中之后,按照下面的步骤追赶到已知的日志位置:
a.对于被选中的不知道共识值的副本中的每一个日志位置,从另外一个副本中读取值。对于任何一个没有已知已提交的值的日志位置,发起一个没有操作的写操作。Paxos将会驱动多数副本在一个值上打成共识-----可能是none-op的写操作或者是之前提议的写操作
b.顺序地将所有没有生效的日志位置生效成共识的值,并将副本的状态变为到分布式共识状态(应该是Coordinator的状态更新)
如果失败,在另外一个副本上重试。
4.验证:如果本地副本被选中并且之前没有最新,发送一个验证消息到coordinator断定(entity group,replica)能够反馈(reflects)所有提交的写操作。不要等待回应----如果请求失败,下一个读操作会重试。
5.查询数据:从选中的副本中使用日志位置所有的时间戳读取数据。如果选中的副本不可用,选取另外一个副本重新开始执行追赶,然后从它那里读取。一个大的读取结果有可能从多个副本中透明地读取并且组装返回
注意在实际使用中 1和2a通常是并行执行的。
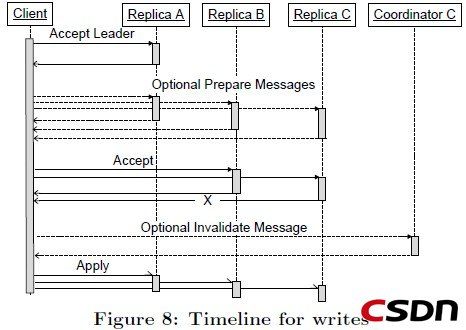
在完整的读操作算法执行后,Megastore发现了下一个没有使用的日志位置,最后一个写操作的时间戳,还有下一个leader副本。在提交时刻,所有更新的状态都变为打包的(packaged)和提议(proposed),并且包含一个时间戳和下一个leader 候选人,做为下一个日志位置的共识值。如果这个值赢得了分布式共识,那么这个值将会在所有完整的副本中生效。否则整个事务将会终止并且必需重新从读阶段开始。
就像上面所描述的,Coordinators跟踪Entity Groups在它们的副本中是否最新。如果一个写操作没有被一个副本接受,我们必需将这个Entity Group的键从这个副本的Coordinator中移除。这个步骤叫做invalidation(失效)。在一个写操作被认为提交的并且准备生效,所有副本必需已经接受或者让这个Entity Group在它们coordinator上失效。
写算法的步骤如下:
1.接受Leader:请求Leader接受值做为0号提议的值。如果成功。跳到第三步
2.准备:在所有副本上执行Paxos Prepare阶段,使用一个关于当前log位置更高的提议号。将值替换成拥有最高提议号的那个值。[Replace the value being written withthe highest-numbered proposal discovered, if any]
3.接受:请求余下的副本接受这个值。如果多数副本失败,转到第二步。
4.失效:将没有接受值的副本coordinator失效掉。错误处理将在接下来描述
5.生效:将更新在尽可能多的副本上生效。如果选择的值不同于原始提议的,返回冲突错误[?]
Coordinator进程在每一个数据中心运行并且只保持其本地副本的状态。在上述的写入算法中,每一个完整的副本必需接受或者让其coordinator失效,所以这个可能会出现任何单个副本失效就会引起不可用。在实际使用中这个不是一个寻常的问题。Coordinator是一个简单的进程,没有其他额外的依赖并且没有持久存储,所以它表现得比一个BigTable服务器更高的稳定性。然而,网络和主机失败仍然能够让coordinator不可用。
Megastore使用了Chubby锁服务:Coordinators在启动的时候从远程数据中心获取指定的Chubby locks。为了处理请求,一个Coordinator必需持有其多数locks。一旦因为宕机或者网络问题导致它丢失了大部分锁,它就会恢复到一个默认保守状态----认为所有在它所能看见的Entity Groups都是失效的。随后(该Coordinator对应的)副本中的读操作必需从多数其他副本中得到日志位置直到Coordinator重新获取到锁并且Coordinator的Entries重新验证的。
写入者通过测试一个Coordinator是否丢失了它的锁从而让其在Coordinator不可用过程中得到保护:在这个场景中,一个写入者知道在恢复之前Coordinator会认为自己是失效的。
在一个数据中心活着的Coordinator突然不可用时,这个算法需要面对一个短暂(几十秒)的写停顿风险---所有的写入者必需等待Coordinator的Chubby locks过期(相当于等待一个master failover后重新启动),不同于master failover,写入和读取都能够在coordinator状态重建前继续平滑进行。
除了可用性问题,对于Coordinator的读写协议必需满足一系列的竞争条件。失效的信息总是安全的,但是生效的信息必需小心处理。在coordinator中较早的写操作生效和较晚的写操作失效之间的竞争通过带有日志位置而被保护起来。标有较高位置的失效操作总是胜过标有较低位置的生效操作。一个在位置n的失效操作和一个在位置m<n的生效操作之间的竞争常常和一个crash联系在一起。Megastore通过一个具有时间期限的数字代表Coordinator来侦测crashes:生效操作只允许在最近一次对Coordinator进行的读取操作以来时间期限数字没变化的情况下修改Coordinator的状态。
总体来说,使用Coordinator从而能够在任何数据中心进行快速的本地读取对于可用性的影响并不是完全没有的。但是实际上,以下因素能够减轻使用Coordinator所带来的问题。
1.Coordinators是比任何的BigTable 服务器更加简单进程,机会没有依赖,所以可用性更高。
2.Coordinators简单,均匀的工作负载让它们能够低成本地进行预防措施。
3.Coordinators轻量的网络传输允许使用高可用连接进行服务质量监控。
4.管理员能够在维护期或者非安全期集中地让一批Coordinators失效。对于默写信号的监测是自动的。
5.一个Chubby qunrum能够监测到大多数网络问题和节点不可用。
总结
文章总体介绍了下google megastore的实现思路,其主要解决的问题就是如何在复杂的环境下(网络问题,节点失效等等)保证数据存取服务的可用性。对于多机房,多节点,以及ACID事务支持,实时非实时读取,错误处理等等关键问题上给出了具体方案。