正式推荐我的一个开源项目2-自定义编译器(9.18更新更多说明)
在项目里面有时有这样的场景,我们需要一个权限表来控制权限,当满足权限表条件时,阻止用户操作并返回错误信息,表的结构类似:
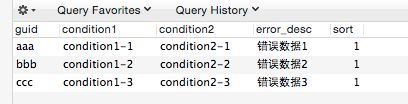
这时有一种传统方式是,我们用mybatis之类的工具,写一段sql,每次用这段sql校验权限:
SELECT * from permission_test where `condition1` = #{condition1} and `condition2` = #{condition2}
当这段sql执行结果存在时,我们就把error_desc作为错误描述信息返回,并阻止用户操作。
当结果不存在时,则表示通过测试。
另外一种方式是,我们将table编译为一段可执行代码,然后每次执行这段代码,这段代码类似:
编译结果图
9.18追加-----------------------------------------------------------
很多同学表示看的不太明白,于是我在这里说一下整体思路。
首先是编译的概念,传统意义的编译是把你的高级语言编译为机器可执行语言。如今我们这里更加宽泛的概念其实可以理解为“翻译”。也就是把一种语言翻译为另外一种更加贴近操作系统的语言。
例如本文的权限表,它是一个,但是同时可以理解为数个语句。
例如
condition1:condition1-1 condition2:condition2-1 end
在这个语句里面,每一个词都是一个token。如condtion1 condition1-1 甚至冒号。
但是如果有这么多token的话,我们的语法就会比较复杂。这就是自定义编译器的好处了,你可以任意加入我们想要的处理方式。
假如我把这段语句分析为
condition condition end
注意这样的话,语法是简单了,但第一个record和第二个record就没有任何区别了,实际上所有的record都可以看作是这一种语句。而且我就丢失了字段名称,字段值这样的信息。
所以在我们的token里面有一个data成员,我们可以把这些信息放入data中。
这就好像 3+4,在正常编译过程是3个token, 3,+,4
但是我们的词法分析器把它分析为2个token, Num, +
这个语句就变为 Num + Num
然后3和4的信息我们放到Num的成员变量中
Num(3) + Num(4)
这个权限表也类似,
condition (name:"condition1", data:"condition1-1")
condition (name:"condition2", data:"condition1-2")
end (data: "错误数据1")
我们要做的就是
1 把这个table读成我们要的数个语句(token流),这个过程称为词法分析
2 编译这个token流,编译为java代码,然后编译为可执行的class
---------------------------------------------------------------------
那么这2种方式的效率相差多大呢,楼主写了一段测试代码:

执行结果是,compiledtester的执行时间总是1ms,而sqltester的执行时间则在800ms左右。
那么,compiledtester是怎么生成的呢?本文将简单介绍这个生成机制。
本文用到了楼主的开源项目 autogrammer : http://git.oschina.net/notebook
它的jar包可以在published项目下面下载到。
本文所用主要代码可以在这里 http://www.oschina.net/code/snippet_573815_50916 看到
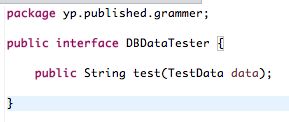
首先有一个接口类 DBDataTester 这个类里面有2种实现,一种是传统的数据库实现SqlDataTester,另外一种是编译为java代码 DBDataTesterImpl 类的实现。
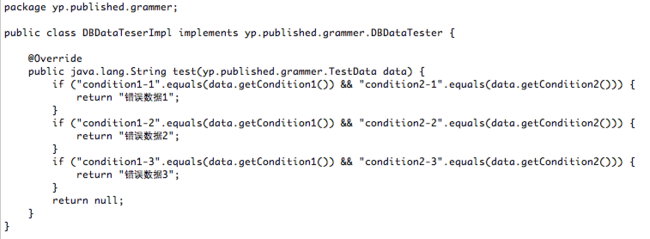
我们要做的就是根据数据库里面的数据,将数个record编译为一个类(DBDataTesterImpl),这个类实现DBDataTester接口,并且在test方法里面,实现数个if 语句进行全面校验。如编译结果图所示:
下面是主要编译代码,看不懂没关系,先看一个大概即可
主要编译代码:

我们的思路是,从数据库里面把所有的record读取出来,然后利用autogrammer提供的功能编译这些record,最终生成目标代码。
编译java代码相关的知识你可以从这篇文章里面学到:
http://www.oschina.net/code/snippet_573815_50891
我们从数据库里面读取的record可以看作如下语句:
condition (name:"condition1", data:"condition1-1")
condition (name:"condition2", data:"condition1-2")
end (data: "错误数据1")
......
第一步:autogrammer要实现自定义编译器,首先需要你定义语法。代码中文法放在 yp/published/grammer/Grammer.txt 中:
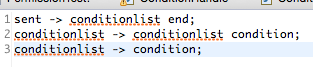
其中,第三句表示,一个condition可以规约为一个conditionlist
第二句表示,一个conditionlist 和 condition 可以规约为一个 conditionlist
这样我们的文法就支持condition的无限罗列了
第一句表示,当遇到一个end时,表明当前句子结束(类似于编程语句中的;)此时会对整个句子进行编译,生成一段代码
类似:
if ("condition1-1".equals(data.getCondition1()) && "condition2-1".equals(data.getCondition2())) {
return "错误数据1";
}
第二步:有了文法以后,我们就需要一个词法分析器,这个词法分析器可以从数据库中读取数据,然后转化为文法中所对应的token流。
词法分析器需要继承,并实现TokenReader接口
public class DBTokenReader implements TokenReader
它的关键代码在这里:


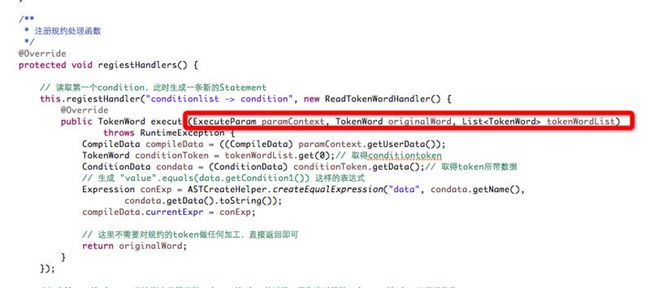
第三步,我们需要针对我们定义的语法注册处理函数
public class ConditionHandler extends DefaultExecuteHandler
注册编译最开始的初始化函数:主要初始化ExecuteParam, ExecuteParam将会贯穿整个编译过程,为我们带着整个过程中产生的数据。

注册编译结束的函数:这里利用ExecuteParam 编译最终实现类DBDataTesterImpl

注册各个规约语句的处理函数
处理函数参数中,tokenWordList为一个List<TokenWord>, 里面的成员就是 "->" 左边的值(condition),
originalWord为 "->" 右边的值(conditionlist)。每一个tokenWord都有一个Object data成员可以放入自定义对象。
paramContext则是贯穿整个编译执行的参数。
最后,当我们凑齐了 语法文件,词法分析器,以及相关handler之后,就可以进行编译过程。在主要编译代码中,我们可以看到首先我们根据语法文件生成一个StateTable,然后生成自己的TokenReader,ExecuteHandler,最终利用3者生成一个ExecuteContext并且执行编译的过程。
这里再次贴出主要编译代码:

再次贴出链接:
本文主要代码:http://www.oschina.net/code/snippet_573815_50916
编译java代码相关介绍: http://www.oschina.net/code/snippet_573815_50891
项目地址:http://git.oschina.net/notebook
其中本项目用到的是autogrammer,jar包在published项目下面。
相关项目 autospider:
http://my.oschina.net/HaFoLuoKe/blog/499980