pig标签传播算法和超级英雄们的社区发现
一、社区发现和标签传播算法
在一个数据集中,一部分节点构成一个小集合,这个小集合内的节点之间的连接相对非常紧密,而各个小集合之间的连接相对来说却比较稀疏。这样的小集合就叫社区。比如在同班同学中,有几个老在一起拉帮结伙,他们就构成了一个社区。现在要想办法把这群人找出来。有点像聚类
社区算法有ng剪边算法,cnm凝聚算法,谱方法等,太高深了,都不懂。标签传播算法简单,速度快,复杂度低。主要流程是这样子:一开始,每个人都持有一个标签,也就是自己,每个人都是自己。然后开始遍历集合里的节点,每个节点选择自己邻居节点中最频繁出现的标签作为自己的标签。如果邻居节点的标签有两个或者多个的个数都一样就随便选一个。比如说我有三个朋友,他们有两个都持有标签B,我就把自己的标签也换成B。这个过程是顺序的,我先来换我的标签,然后我朋友再来。遍历一次之后,有的人的标签换了,有的没换。不停的重复这个过程,结果会渐渐变稳定,稳定的时候就停止迭代。但也有可能永远停不下来,比如我持有A,我就一个朋友,他持有B。那每次迭代,我和他就互换一下标签,大家都吃了炫麦,不管迭代多少次,也就那样了。所以要设置一个迭代上限。
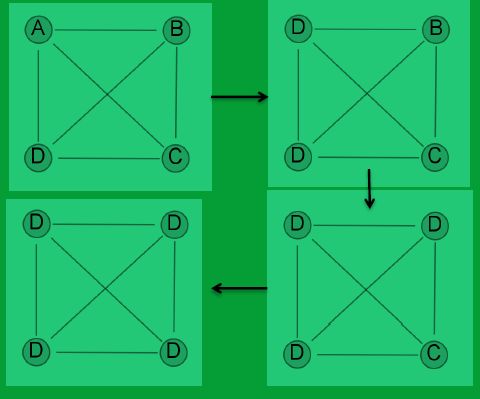
二、pig实现(不是完全实现)
定义初始文件夹,放入node文件,该文件有两列,id,label 这个文件用来表示图的节点的id和初始标签,其实初始标签就写成id就可以了,所以文件内容就是一行行id空格id。 edge放入边文件,文件有两列 id1,id2。比如id1关注了id2的微博或者回复了一下,就在改文件里放一条 id1 id2,这个文件用来表示图的边。
#lpa.pig
-- Code by James
%default NODE /home/hutao/week10/hero-social-network-Nodes.csv
%default EDGE /home/hutao/week10/hero-social-network-Edges.csv
%default OUTPUT /home/hutao/week10/node
--定义目录
-- Load Data 我的文件是空格分隔的,
node = LOAD '$NODE' USING PigStorage(' ') AS ( id:chararray, label:chararray);
edge = LOAD '$EDGE' USING PigStorage(' ') AS ( source:chararray, target:chararray);
-- Get label
label_jnd = JOIN edge BY source, node BY id USING 'REPLICATED'; -- If node table is cache-able
-- 获得 id2 ,id1 ,id1的标签
label_final = FOREACH label_jnd GENERATE edge::target AS user, edge::source AS source, node::label AS label;
-- Propagation 获得每个id的邻居标签和个数
prop_cnt = FOREACH ( GROUP label_final BY (user, label) )
GENERATE FLATTEN(group) AS (user, label), COUNT(label_final) AS cnt;
-- 对标签个数排序,取次数最多的一个
prop_grp = FOREACH ( GROUP prop_cnt BY user )
{
labels_srt = ORDER prop_cnt BY cnt DESC;
labels_top = LIMIT labels_srt 1;
GENERATE FLATTEN(labels_top);
}
-- 形成新的 id : 标签文件 这个将会在下一轮迭代中用 相当与初始时候的node文件
prop = FOREACH prop_grp GENERATE user AS user, label AS new_label;
-- Check stop criterion 统计一下指标,看是否可以停止迭代了。
check_jnd = JOIN node BY id LEFT OUTER, prop BY user;
check_prj = FOREACH check_jnd
GENERATE node::id AS id, label AS old_label, ( new_label IS NULL ? label:new_label ) AS new_label;
check_flt = FILTER check_prj BY NOT old_label MATCHES new_label;
check = FOREACH ( GROUP check_flt ALL )
{
labels_prj = check_flt.new_label;
labels_dst = DISTINCT labels_prj;
GENERATE COUNT(check_flt), COUNT(labels_dst);
}
-- Output 把新的 id:标签文件存到文件系统里,下一次迭代
out = FOREACH check_prj GENERATE id, new_label AS label;
STORE out INTO '$OUTPUT' USING PigStorage(' ');
-- 包括仍然在更换标签的节点数, 不重复的标签总数
DUMP check;
不完全实现主要是没有随机选一个的过程,然后也不能自动停下来,不过黄老师的经验是5次迭代就差不多了,再迭代个几次就ok。我用下面脚本迭代10次。用的是单机模式,毕竟就一台笔记本。第一次的时候,直接读取原始数据,第二次,node文件读上一次输出的文件。而边文件是始终都读原文件的,因为边文件就是权重嘛。pig传参这里有点坑。我用的是pig-0.12.0官网上说传参要用-param key=value ,我尝试了很多次都不行,-x local也只能放在这个位置,否则运行不了。运行后会生成一个个文件夹,里面就是最终的id:标签了。
#!/bin/bash #lpa.sh curdir=/home/hutao/week10 for i in $(seq 0 10); do j=$(($i+1)) if [ $i = 0 ]; then pig -x local -p NODE="$curdir/hero-social-network-Nodes.csv" -p OUTPUT="$curdir/node_$j" $curdir/lpa.pig > $curdir/log/$i; else pig -x local -p NODE="$curdir/node_$i" -p OUTPUT="$curdir/node_$j" $curdir/lpa.pig > $curdir/log/$i; fi done;
三、选取数据集进行实验。
这里我用的是gephi的数据集wiki.gephi.org/index.php/Datasets。 在这里,下载到了漫威漫画超级英雄的数据集。这个数据集有170000个人名在里面,有关系的,就有一条边。下载到The Marvel Social Network之后,可以用gephi打开,打开之后会有两个页签可以选择,一个是节点,一个是边。这里分别导出就得到了我运行脚本时需要的文件。另外我选的是空格分隔,pig默认的是制表符分隔。推荐大家选制表符分隔,然后把脚本改一下。因为这个数据集中很多英雄的名字是带空格的,到时候会造成Pig难以识别,而产生一对重复的数据。其实漫威的世界关非常大,绿巨人爆发的时候不小心搞死了蜘蛛侠的父母,神奇四侠隐身女和石头人的老头也和绿巨人是同事,金刚狼其实和美国队长是战友。光看神盾局特工和妇联电影什么的,完全搞不清楚啊,还好借助代码,其实可以挖掘出漫威世界关里的社区。这也是程序猿福利。
运行sh lpa.sh,然后等15分钟,就能看到结果了。由于脚本中字符串相等用的是match,所以人名中要是有点括号啥的会报错,不过不影响整体执行。另外 gephi导出的数据,第一行会是title,和数据无关,我忘记删除了。
英雄世界社区发现就完成了。还要注意的是,标签传播算法,并不会保证每次结果都一样,因为有些标签是随机选取的。不过总体的结构是差不多的。在我迭代到第10次的时候,机乎百分之90的人标签都是绿巨人,大块头也太强大了。下面选迭代到第五次的时候的结果给大家瞧瞧。我还以为x战警比较牛,毕竟他们人物多。
衡量算法结果的时候,需要用到模块度这个指标,我暂时用肉眼评估一下^-^.下面有第三次迭代的结果,看起来还比较靠谱。从综合结果来看的话,大块头天下无敌,蜘蛛侠排名第二。另外还有几个没听说过得。毕竟这个数据集有不少脏数据。

要比较两次迭代的结果可以使用下面脚本
data1 = LOAD 'week10/node_4' AS ( id, label );
data2 = LOAD 'week10/node_5' AS ( id, label );
common_jnd = JOIN data1 BY id, data2 BY id;
common_prj = FOREACH common_jnd GENERATE data1::id AS id, data1::label AS old_label,data2::label AS new_label;
check_flt = FILTER common_prj BY old_label != new_label;
check = FOREACH ( GROUP check_flt ALL )
{
labels_prj = check_flt.new_label;
labels_dst = DISTINCT labels_prj;
GENERATE COUNT(check_flt), COUNT(labels_dst);
}
store common_prj into 'week10/4vs5';
dump check;
其实在5次到第六次的迭代过程中,就没有什么标签在更换了,我迭代了10次。不过这个起因是因为脚本里面的重定向没有起作用。谁路过了可以指点我一下,shell的重定向怎么写。在第4次到第五次的时候有2138个人更换了标签。在第五次到第六次的迭代中,只有882个人的标签发生了变化,生成了71个标签,这里一共有170000个人,所以,基本可以忽略882的这个变化。
总结一下就是:绿巨人天下无敌!谁都打不过!不服可以来辩。