python的xml文件操作
python中xml的操作可以使用dom库、sax库、etree库(这个是新的)、parsers库。其中dom.minidom是dom轻量级模块,这里介绍dom.minidom和etree两个模块这里以UserInfo.xml文件为例,xml
内容如下: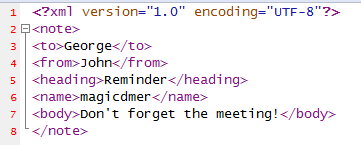
<dom.minidom>
xml解析
>>>xmldoc = minidom.parse('UserInfo.xml') #it will load a xml file,can use filename or openobject
>>>xmldoc
<xml.dom.minidom.Document instance at 010BE87C>
>>>print xmldoc.toxml() #output all xml
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<name>magicdmer</name>
<body>Don't forget the meeting!</body>
</note>
>>>node = xmldoc.firstChild
>>>print node.toxml()
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<name>magicdmer</name>
<body>Don't forget the meeting!</body>
</note>
>>>print node.firstChild.toxml() #this will display blank,because it find '\n'
>>>print node.childNodes[1].toxml()
<to>George</to>
>>>print node.childNodes[2].toxml() #it is '\n', display blank
>>>print node.childNodes[3].toxml()
<from>John</from>
>>>print node.lastChild.toxml() #it find zuihou element,it is '\n'
>>>
搜索元素
>>>from xml.dom import minidom
>>>xmldoc = minidom.parse('UserInfo.xml')
>>>FindIt = xmldoc.getElementsByTagName('name') #it return Element Object
>>>print FindIt[0].toxml()
<name>magicdmer</name>
>>>print FindIt[0].tagName
name
>>>
访问元素属性
类似<ref id="bit"><p>0</p><p>1</p></ref>
>>>from xml.dom import minidom
>>>xmldoc = minidom.parse('UserInfo.xml')
>>>FindIt = xmldoc.getElementsByTagName('ref') #it return Element Object
>>>It = FindIt[0]>>>It.attributes.keys()
[u'id']
>>>It.attributes.values()
[<xml.dom.minidom.Attr instance at 0x81d5044>]
>>>It.attributes["id"]
[<xml.dom.minidom.Attr instance at 0x81d5044>]
>>>print It.attributes["id"].name
u'id'
>>>print It.attributes["id"].value
u'bit'
<xml.etree>
>>>from xml.etree.ElementTree import ElementTree
>>>tree = ElementTree()
>>>tree.parse('UserInfo.xml')
<Element 'note' at 0x1aa060>
>>>p = tree.find('name')
>>>print p.text
magicdmer
>>>print p.tag
name
>>>