Mahout的taste推荐系统里的几种Recommender分析
Taste简介
Mahout 是apache下的一个java语言的开源大数据机器学习项目,与其他机器学习项目不同的是,它的算法多数是mapreduce方式写的,可以在hadoop上运行,并行化处理大规模数据。
协同过滤在mahout里是由一个叫taste的引擎提供的, 它提供两种模式,一种是以jar包形式嵌入到程序里在进程内运行,另外一种是MapReduce Job形式在hadoop上运行。这两种方式使用的算法是一样的,配置也类似。基本上搞明白了一种,就会另外一种了。
Taste的系统结构如下图

其中:
Perference:表示用户的喜好数据,是个三元组(userid, itemid, value),分别表示用户id, 物品id和用户对这个物品的喜好值。
DataModel:是Perference的集合,可以认为是协同过滤用到的user*item的大矩阵。DateModel可以来自db, 文件或者内存。
Similarity:相似度计算的接口,各种相似度计算算法都是继承自这个接口,具体相似度计算的方法,可以参考这篇文章:http://anylin.iteye.com/blog/1721978
Recommender: 利用Similarity找到待推荐item集合后的各种推荐策略,这是最终要暴露个使用者的推荐接口,本文将重点介绍下taste里各种recommender的实现策略,有错误之处,请多指正。
各种Recommender介绍
按照协同过滤方法的分类, taste里的recommender可以分别划到对应的分类下:
Item-based:
GenericItemBasedRecommender
GenericBooleanPrefItemBasedRecommender
KnnItemBasedRecommender
User-based:
GenericUserBasedRecommender
GenericBooleanPerfUserBasedRecommender
Model-based:
SlopeOneRecommender
SVDRecommender
TreeClusteringRecommender
ItemAverageRecommender
ItemUserAverageRecommender
每种Recommender的详细介绍如下:
GenericUserBasedRecommender
一个很简单的user-based模式的推荐器实现类,根据传入的DataModel和UserNeighborhood进行推荐。其推荐流程分成三步:
第一步,使用UserNeighborhood获取跟指定用户Ui最相似的K个用户{U1…Uk};
第二步,{U1…Uk}喜欢的item集合中排除掉Ui喜欢的item, 得到一个item集合 {Item0...Itemm}
第三步,对{Item0...Itemm}每个itemj计算 Ui可能喜欢的程度值perf(Ui , Itemj) ,并把item按这个数值从高到低排序,把前N个item推荐给Ui。其中perf(Ui , Itemj)的计算公式如下:
![]()
其中 ![]() 是用户Ul对Itemj的喜好值。
是用户Ul对Itemj的喜好值。
GenericBooleanPerfUserBasedRecommender
继承自GenericUserBasedRecommender, 处理逻辑跟GenericUserBasedRecommender一样,只是 的计算公式变成如下公式

其中![]() 是布尔型取值,不是0就是1。
是布尔型取值,不是0就是1。
GenericItemBasedRecommender
一个简单的item-based的推荐器,根据传入的DateModel和ItemSimilarity去推荐。基于Item的相似度计算比基于User的相似度计算有个好处是,item数量较少,计算量也就少了,另外item之间的相似度比较固定,所以相似度可以事先算好,这样可以大幅提高推荐的速度。
其推荐流程可以分成三步:
第一步,获取用户Ui喜好的item集合{It1…Itm}
第一步,使用MostSimilarItemsCandidateItemsStrategy(有多种策略, 功能类似UserNeighborhood) 获取跟用户喜好集合里每个item最相似的其他Item构成集合 {Item1…Itemk};
第二步,对{Item1...Itemk}里的每个itemj计算 Ui可能喜欢的程度值perf(Ui , Itemj) ,并把item按这个数值从高到低排序,把前N个Item推荐给Ui。其中perf(Ui , Itemj)的计算公式如下:
![]()
其中![]() 是用户Ul对Iteml的喜好值。
是用户Ul对Iteml的喜好值。
GenericBooleanPrefItemBasedRecommender
继承自GenericItemBasedRecommender, 处理逻辑跟GenericItemBasedRecommender一样,只是 的计算公式变成如下公式
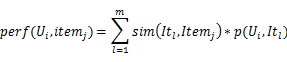
其中![]() 是布尔型取值,不是0就是1。
是布尔型取值,不是0就是1。
KnnItemBasedRecommender
继承自GenericItemBasedRecommender, 处理逻辑跟GenericItemBasedRecommender一样,只是 的计算公式比较复杂,基于一篇论文提到的算法,论文地址在这里
http://public.research.att.com/~volinsky/netflix/BellKorICDM07.pdf。根据论文介绍,该算法对数据进行了一些预处理,同时改进了邻居选取策略,再不怎么增加计算量的情况下,可以较大幅度提高推荐准确度。
ItemAverageRecommender
这是一个提供给实验用的推荐类,简单但计算快速,推荐结果可能会不够好。它预测一个用户对一个未知item的喜好值是所有用户对这个item喜好值的平均值,预测公式如下。
![]()
ItemUserAverageRecommender
在ItemAverageRecommender的基础上,考虑了用户喜好的平均值和全局所有喜好的平均值进行调整,它的预测公式如下:
![]()
其中 ![]() 是所有用户对Itemj喜好的平均值,
是所有用户对Itemj喜好的平均值, ![]() 是用户Ul所有喜好的平均值,
是用户Ul所有喜好的平均值,![]() 是全局所有喜好值的平均值。
是全局所有喜好值的平均值。
RandomRecommender
随机推荐item, 除了测试性能的时候有用外,没太大用处。
SlopeOneRecommender
基于Slopeone算法的推荐器,Slopeone算法适用于用户对item的打分是具体数值的情况。Slopeone算法不同于前面提到的基于相似度的算法,他计算简单快速,对新用户推荐效果不错,数据更新和扩展性都很不错,预测能达到和基于相似度的算法差不多的效果,很适合在实际项目中使用。
基本原理:
用户 对itema打分 对itemb打分
X 3 4
Y 2 4
Z 4 ?
用户Z对itemb的打分可能是多少呢? Slope one算法认为:所有用户对事物A对itemb的打分平均差值是:((3 - 4) + (2 - 4)) / 2 = -1.5,也就是说人们对itemb的打分一般比事物A的打分要高1.5,于是Slope one算法就猜测Z对itemb的打分是4 + 1.5 = 5.5
当然在实际应用中,用户不止X,Y 两个,跟itemb相关的item也不止A一个,所以slopeone的预测公式如下:
![]()
其中![]() 表示与, 用户Ui打过分的除itemj之外所有其他item集合,
表示与, 用户Ui打过分的除itemj之外所有其他item集合, ![]() 表示用户Ui对 itemk的打分。
表示用户Ui对 itemk的打分。![]() 表示除Ui外所有其他用户对itemk和itemj打分差值的平均值。
表示除Ui外所有其他用户对itemk和itemj打分差值的平均值。
![]()
其中![]() 表示除Ui外其他所有用户的集合。
表示除Ui外其他所有用户的集合。
SVDRecommender
基于SVD矩阵分解技术的推荐器,暂时没有研究, 具体可以参考这个文档。
https://cwiki.apache.org/confluence/display/MAHOUT/Collaborative+Filtering+with+ALS-WR
TreeClusteringRecommender
利用聚类方法的推荐器,暂时没有研究。