在嵌入式显示设备中如果有足够大的flash,我们就可以用数百KB空间来存储一个HZK16字库文件用于显示16*16汉字,免得还要自己提取字模。
HZK16字库是符合GB2312标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个.
其中一级汉字有 3755个,按声序排列,二级汉字有3008个,按偏旁部首排列.
我们在一些应用场合根本用不到这么多汉字字模, 所以在应用时就可以只提取部分字体作为己用.
HZK16字库里的16×16汉字一共需要256个点来显示, 也就是说需要32个字节才能达到显示一个普通汉字的目的.
我们知道一个GB2312汉字是由两个字节编码的,范围为0xA1A1~0xFEFE.
A1-A9为符号区, B0到F7为汉字区. 每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域).
一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的位号.
其中, 每个区记录94个汉字, 位号为该字在该区中的位置. 所以要找到"我"在hzk16库中的位置就必须得到它的区码和位码.
区码:汉字的第一个字节-0xA0 (因为汉字编码是从0xA0区开始的, 所以文件最前面就是从0xA0区开始, 要算出相对区码)
位码:汉字的第二个字节-0xA0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:
offset=(94*(区码-0xa1)+(位码-0xa1))*32
如何知道一个汉字的区码和位码呢,可以用一个小程序来计算:
#include <stdio.h>
#include <stdlib.h>
int main(void) {
unsigned char code[2] = {0};
puts("请输入一个汉字:");
gets((char*)code);
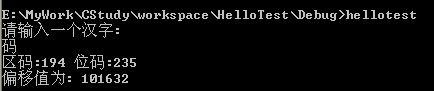
printf("区码:%d 位码:%d",code[0],code[1]);
return EXIT_SUCCESS;
}

知道区位码就可以计算出字模数据在字库文件中的绝对偏移地址:
#include <stdio.h>
#include <stdlib.h>
int main(void) {
int posi;
unsigned char code[2] = {0};
puts("请输入一个汉字:");
gets((char*)code);
printf("区码:%d 位码:%d\n",code[0],code[1]);
posi = ((code[0] - 0xa1) * 94 + code[1] - 0xa1)*32;
printf("偏移值为: %d\n", posi);
return EXIT_SUCCESS;
}
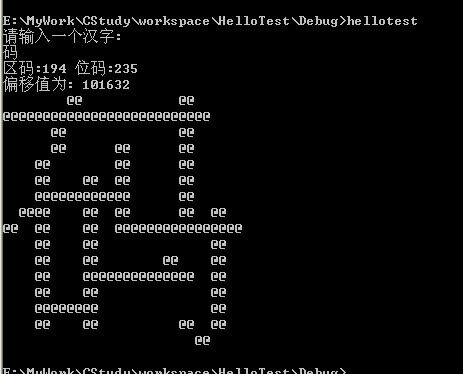
有了文件,又有了偏移量,我们就可以对文件进行读取,取出一个汉字所需要的32字节字模数据,并将该字模显示出来了:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
long int offset;
unsigned char code[2] = {0};
unsigned char buffer[32]; //存储一个汉字所用的32个字节
unsigned char i,j;
FILE *fp = NULL;
puts("请输入一个汉字:");
gets((char*)code);
printf("区码:%d 位码:%d\n", code[0], code[1]); //显示区位码
offset = ((code[0] - 0xa1) * 94 + code[1] - 0xa1) * 32; //计算绝对偏移地址
printf("偏移值为: %ld\n", offset);
fp = fopen("hzk16.dat", "rb"); //二进制只读方式打开,261KB
if (fp == NULL ) //如果打开失败
{
printf("打开字库失败\n");
return 0;
}
fseek(fp,offset,0); //根据偏移寻找到该字字模的第一个字节
for (i = 0; i < 32; ++i) { //连续读取32个字节
buffer[i] = fgetc(fp);
}
for (i = 0; i < 32; ++i) { //将32个字节顺序打印
for (j = 0; j < 8; ++j) {
if (buffer[i] & 0x80) {
printf("@@");
}else{
printf(" ");
}
buffer[i] <<= 1;
}
if (i % 2) {
printf("\n"); //如果i%2==1说明该字节是靠后的那个字节,显示完后要换行
}
}
return EXIT_SUCCESS;
}
此时,HZK16通过C代码解析出来了。但是采用这种字库毕竟有局限,如“囧”字,是无法显示出来的,很多没有收录的新字在显示时还是不得不采用字模方式:
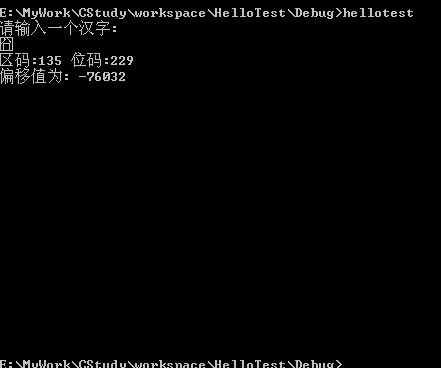
值