很好的文章,关于并发的学习。
可以到http://www.ifeve.com里去看看,
另外可以写个代码测试一下HashTable ,ConcurrentHashMap,HashMap,LinkedHashMap,Collections.synchronizedMap(map),TreeMap,
ConcurrentSkipListMap之间的性能。
测试场景:
1. 单线程写入场景
2. 单线程长时间大数据写入场景
3. 多线程(20个,100个,500个….)场景下的写入场景
4. 根据以上构造读的场景
观察以上情况下的CPU,内存使用情况,GC频率等
推荐用jmeter来测试。
对于并发的学习,可以先学习一下基础概念,
基础概念理解透了,就事半功倍了。
譬如,多线程的内存访问问题,为什么是线程安全的?
为了能够做到对共享资源的并发访问,在java里面是怎么控制的?(有空的话也可以了解一下其他语言),了解一下多线程的monitor模型
Volatile(AtomicLong,AtomicInteger等),synchronized,Lock(ReadWriteLock,ReentrantLock等)的比较,各自之间的使用场景?Lock都有哪些实现?各自差异和使用场景是怎么样的?
Condition的作用?
AbstractQueuedSynchronizer的理解,Concurrent包里面的代码实现很多场景都会用到。
了解一下CAS的实现
多线程编程模式?
另外可以关注一下RingBuffer的一些实现,怎么做到无锁状态的运行,Disruptor框架
……
ConcurrentHashMap原理解析
背景:
关于ConcurrentHashMap的实现原理,很多时候我们只是知道它采用锁分离技术,在高并发的的情况下可以保证线程安全,但具体其实现原理及实现细节却没有细细研究过,今天就针对其应用场景和原理和大家分享一下。
原理解析
java.util.concurrent.ConcurrentHashMap 是jdk1.5之后支持高并发,高吞吐量的hashmap的实现,其主要是实现map接口 和 ConcurrentMap接口,我们看下类图
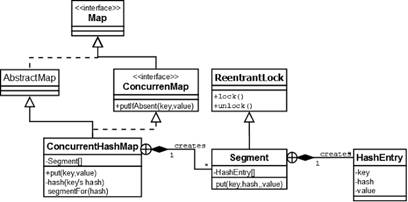
对于普通的HashMap,java是采用链式结构解决hash冲突的,
下面是一个普通的HashMap的数据结构图的表示,HashMap的通过hash算法将数据分配到一个数组内(bucket),然后每个bucket中采用链表的结构解决冲突,
我们来再看下ConcurrentHashMap的简单的数据结构的图
ConcurrentHashMap 类中包含两个静态内部类HashEntry和Segment。HashEntry用来封装映射表的 键/值对;Segment 用来充当数据划分和锁的角色,每个Segment对象守护整个散列映射表的若干个table。每个table是由若干个 HashEntry对象链接起来的链表。一个ConcurrentHashMap实例中包含由若干个Segment对象组成的数组, 因此由此可知,要想定位到一个元素需要经过两次的hash,第一次定位到segment,第二次定位到链表头部,因此hash时间要比普通的hashmap的 hash算法长。
我们看下每个segment是怎么定义的:

Segment继承了ReentrantLock,表明每个segment都可以当做一个锁。(ReentrantLock前文已经提到,不了解的话就把当做synchronized的替代者吧)这样对每个segment中的数据需要同步操作的话都是使用每个segment容器对象自身的锁来实现。只有对全局需要改变时锁定的是所有的segment。
上面的这种做法,就称之为“分离锁(lock striping)”。
下面我们来看下ConcurrentHashMap的get操作,他是不需要加锁的

下面看下Segment的get方法
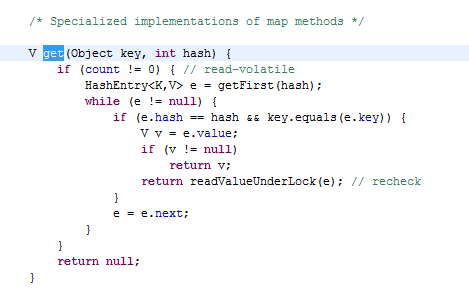
上面的代码中,一开始就对volatile变量count进行了读取比较,这个还是java5对volatile语义增强的作用,这样就可以获取变 量的可见性。所以count != 0之后,我们可以认为对应的hashtable是最新的,当然由于读取的时候没有加锁,在get的过程中,可能会有更新。当发现根据key去找元素的时候,但发现找得的key对应的value为null,这个时候可能会有其他线程正在对这个元素进行写操作,所以需要在使用锁的情况下在读取一下 value,以确保最终的值。
在ConcurrentHashMap的remove,put操作还是比较简单的,都是将remove或者put操作交给key所对应的segment去做的,所以当几个操作不在同一个segment的时候就可以并发的进行。具体代码就不在这里粘贴了,大家有兴趣可以去看下源码的实现。
总结以及注意事项
在实际的应用中,散列表一般的应用场景是:除了少数插入操作和删除操作外,绝大多数都是读取操作,而且读操作在大多数时候都是成功的。正是基于这个前提,ConcurrentHashMap 针对读操作做了大量的优化。通过 HashEntry 对象的不变性和用 volatile 型变量协调线程间的内存可见性,使得 大多数时候,读操作不需要加锁就可以正确获得值。这个特性使得 ConcurrentHashMap 的并发性能在分离锁的基础上又有了近一步的提高。
总结
ConcurrentHashMap 是一个并发散列映射表的实现,它允许完全并发的读取,并且支持给定数量的并发更新。相比于 HashTable 和用同步包装器包装的 HashMap(Collections.synchronizedMap(new HashMap())),ConcurrentHashMap 拥有更高的并发性。在 HashTable 和由同步包装器包装的 HashMap 中,使用一个全局的锁来同步不同线程间的并发访问。同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器。这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了。
在使用锁来协调多线程间并发访问的模式下,减小对锁的竞争可以有效提高并发性。有两种方式可以减小对锁的竞争:
1 减小请求 同一个锁的 频率。
2 减少持有锁的 时间。
ConcurrentHashMap 的高并发性主要来自于三个方面:
1 用分离锁实现多个线程间的更深层次的共享访问。
2 用 HashEntry 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求。
3 通过对同一个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性。
使用分离锁,减小了请求 同一个锁的频率。
通过 HashEntery 对象的不变性及对同一个 Volatile 变量的读 / 写来协调内存可见性,使得 读操作大多数时候不需要加锁就能成功获取到需要的值。由于散列映射表在实际应用中大多数操作都是成功的 读操作,所以 2 和 3 既可以减少请求同一个锁的频率,也可以有效减少持有锁的时间。
通过减小请求同一个锁的频率和尽量减少持有锁的时间 ,使得 ConcurrentHashMap 的并发性相对于 HashTable 和用同步包装器包装的 HashMap有了质的提高。
参考资料
http://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/index.html