Havok VS PhysX 漫谈物理加速世界!
Havok VS PhysX 漫谈物理加速世界!
| 第1页:物理大战新篇章 |
2008年6月,NVIDIA与AMD-ATI先后发 布了自家新一代高阶产品GT200(GeForce GTX 280/260)与RV770(Radeon HD 4850/4870),我们在惊诧于新产品的极限性能时,众多新技术引用也是玩家关注的重点,例如NVIDIA的CUDA架构,AMD-ATI的 GPGPU解决方案等。在众多的技术当中,物理加速技术由于震撼的视觉体验及两家不同的解决方案再次成为了人们关注的焦点。
![]()
NVIDIA发布的CUDA 2.0开发包中蕴含了PhysX物理加速技术,NVIDIA的意向是使用GPU通过CUDA架构来实现物理加速;而作为同时拥有CPU与GPU业务的 AMD自然会选择CPU+GPU为主导的Havok物理引擎。2007年9月Intel闪电收购Havok之后,NVIDIA与AMD-ATI的GPU物 理加速计算就显得非常尴尬,因为Intel收购Havok的目的就是使Havok引擎专注于CPU物理运算,为了对抗Intel(亦或是说 CPU),NVIDIA收购了Ageia及其PhysX引擎,使PhysX引擎专注于GPU物理运算。AMD-ATI如何选择物理加速方案在RV770之 前业界充满了猜测,因为无论是Havok还是PhysX引擎,都是竞争对手的产品,而为了AMD更加长远的Fusion计划,AMD-ATI最终选择了前 者。

物理加速技术在2006年Ageia发布物理 PhysX加速卡时被人们所关注,甚至有人笑称3D加速成就了3DFX,而物理加速将成就Ageia,但是由于Ageia采用的是PhysX硬件物理卡加 速方式,而物理卡又价格不菲,虽然Ageia也出售PhysX引擎,但是由于没有PhysX硬件加速卡支持的话效率会降低,在加上NVIDIA与AMD- ATI当时都采用了Havok引擎作为标准,因此一直没有受到游戏开发商及广大玩家的重视。而Havok引擎在很长一段时间都是致力于CPU软件加速,但 是随着Havok 4.0工具中Havok FX的发布就不一样了,Havok FX引擎是通过GPU来进行物理加速,主要针对当时的PhysX引擎。
关于GPU与CPU在做物理运算时的差距这里就不多做 介绍了,有很多这方面的文章可寻,总体来说GPU运行物理运算可以是四核CPU的十几倍到几十倍不等,比PPU有几倍到几十倍的性能提升。而我们这里主要 探讨的NVIDIA与AMD-ATI GPU加速昨天、今天与明天!
| 第2页:昨天—殊归同途的Havok FX引擎 |
Havok FX发布于2006年中,前文已经提到,Havok FX引擎是通过GPU来进行物理加速,当时的NVIDIA与AMD-ATI都不约而同的支持Havok FX引擎,首先来看NVIDIA的NVIDIA SLI Physics技术,NVIDIA是采用SLI模式的第二块显卡来进行物理加速。
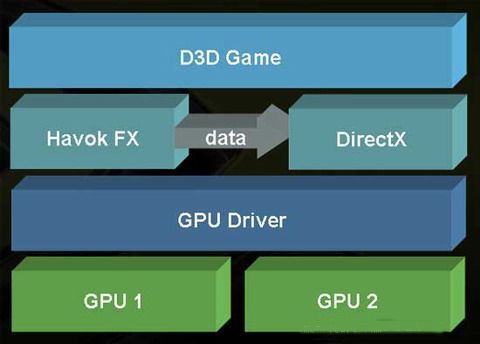
从上图中可以看出,Havok FX API通过DirectX将数据发给GPU驱动,如果游戏或者驱动不支持SLI物理,那么将不会发送物理数据,反之则交给GPU 2进行物理计算,计算结果则返回给Havok API。
与NVIDIA的物理解决方案类似,AMD-ATI同样采用Havok FX引擎,同样基于多卡互联CrossFire来实现物理加速,第二块显卡来进行GPU物理加速。
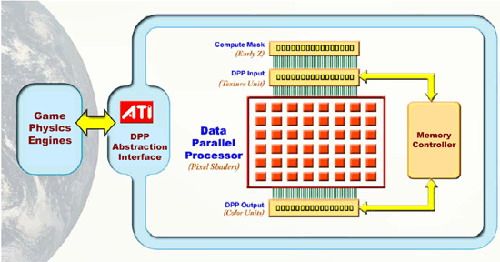
当时AMD-ATI的X1000系列GPU的设计理念是搭建智能化的芯片架构,使得芯片内部的运算灵活性增强,根据外部接口API的不同,可以实现完全不同的运算任务,并且命名为DPP(Data Parallel Processing )并行数据处理架构。
虽然同样采用了Havok FX引擎,并且都是双卡互联形式实现,但是两家的解决方案却大相径庭:NVIDIA是通过DirectX API来实现物理加速,而AMD-ATI则是通过数据并行计算架构提取(Data Parallel Processing Architecture Abstraction )直接与Havok FX引擎交换数据,让Havok FX引擎直接与GPU沟通,而不需要通过Direct3D和OpenGL API,AMD-ATI著名的Close To Metal(CTM)接口就是在这个时期提出的。简单的理解就是,AMD-ATI的实现方式是“GPGPU”通用计算的形式来做物理运算,而NVIDIA 是让显卡通过DirectX以“GPU”的工作方式在做物理加速(其实也是GPGPU应用范畴)。
至于两种方案的优劣其实讨 论起来真的没有意义,因为实际上除了NVIDIA与AMD-ATI自家演示的小DEMO与视频之外,目前支持GPU物理加速的游戏几乎没有,大部分使用到 物理加速的游戏还都是使用CPU物理加速的方式,包括我们熟知顶级大作《Crysis》、《使命召唤4:现代战争》等等……
| 第3页:今天—PhysX决战Havok FX |
当NVIDIA宣布 CUDA集成PhysX物理引擎时,很多人都会认为PhysX引擎只支持GPU物理加速技术,这也是AMD-ATI选择Havok FX引擎的主要原因。然而实际上PhysX引擎最初是只支持CPU与PPU,而不支持GPU,即使是融入CUDA之后,PhysX引擎也仍然支持CPU物 理加速。之所以给人PhysX引擎只支持GPU物理加速的错觉,是因为NVIDIA表示今后将大力发展GPU物理加速,但这并不表示PhysX引擎排斥 CPU或者CPU+GPU的解决方案。

无论是GPU还是CPU、 PPU、Cell(PS3)都可以通过HAL翻译层来实现软、固质体动力(Soft or Rigid Body Dynamics)、通用碰撞侦测(Universal Collision Detection)、有限元素分析(Finite Element Analysis)、流体动力(Fluid Dynamics)、毛发模拟(Hair Simulation)以及更先进的布料模拟(Cloth Simulation)、自然模拟(Natural Motion)等在内新颖技术。
通过CUDA通用接 口,PhysX引擎将NVIDIA GPU中的Thread Scheduler(线程管理器)模拟成Control Engine(控制引擎CE),而Streaming Processors来模拟Vector Processing Engine(矢量处理引擎,VPE),其中CE控制引擎负责任务的指派,相当于PhysX中的主管机构,而真正的物理运算任务则是由VPE矢量引擎来完 成,最后通过Data Movement Engine(数据移动引擎DME)输出。关于最新GT200物理运算的优势已经被NVIDIA吹的天花乱坠,这里就不多介绍了,感兴趣的朋友参见《NVIDIA夺面双雄 GT200全球同步首测》 一文。
而AMD-ATI则继续选 择Havok FX引擎,不过RV770系列实现物理加速的方法也已经不同于之前的CrossFire双卡解决方案,之前Radeon X1000系列是通过据并行计算架构提取直接与Havok FX引擎相连接(其实也可以通过Direct3D和OpenGL API),然而由于对抗CUDA的原因,AMD-ATI也需要自己的GPGPU规范,而AMD-ATI则选择了苹果公司力推的通用计算行业标准 OpenCL,它能与图形硬件及多核CPU相协调以提高系统的整体性能,而AMD-ATI的Havok物理加速技术就是基于CAL/Brook+的。
实质上讲无论是CTM接 口,还是现在的CAL/Beook+,AMD-ATI执行物理加速的概念都没有变,那就是GPGPU的并行能力进行物理运算,而NVIDIA方面可以真正 称的上市GPGPU物理加速还是从CUDA开始的。另外我们也注意到,之前无论NVIDIA还是AMD-ATI在展示自己物理运算时都是基于双卡技术,而 如今他们更愿意谈论单卡。
| 第4页:明天—技术与现实之间的抉择 |
那么物理加速技术的明天到 底是Havok FX引擎还是PhysX引擎的天下?我们先来看一下双方的阵营:PhysX引擎目前只有NVIDIA一家支持,有消息称AMD-ATI目前也正在与 NVIDIA商榷授权的问题,那么有可能AMD-ATI最终也支持PhysX引擎;Havok FX引擎目前已经得到AMD-ATI的支持,加上Havok的所有者Intel,目前构成了Intel+AMD-ATI对抗NVIDIA的局面。
|
物理加速阵营对比
|
||
| 支持引擎 | 加速态度 | |
|
Intel
|
Havok
|
CPU
|
|
AMD-ATI
|
Havok(PhysX引擎正在商榷)
|
CPU+GPU
|
|
NVIDIA
|
PhysX引擎
|
GPU
|
三方对于物理加速是由GPU还是由CPU执行的态度开篇已经阐明,实际上这场物理大战最终的抉择就是落在了到底是CPU加速还是GPU加速上,我们先来看一下最简单的物理加速计算过程。小熊在线www.beareyes.com.cn
无论PhysX引擎还是Havok引擎物理计算都基于以下步骤:
Integrate整合初步计算
Collide碰撞判定
Solve Collisions碰撞结果计算
在Integrate整合 初步计算阶段,进行物理对象的一些初始物理状态的初始化,包括速度、加速度等各项信息,为后面的运算做准备。Collide 碰撞判定进行一些对象之间的碰撞检测,并以对的形式进行处理(因为碰撞总是两个物体相互的),Solve Collisions碰撞结果计算阶段则是对碰撞的后处理,包括碰撞后的速度等。Solve Collisions碰撞结果计算阶段是最复杂的,那么我们可以看出物理计算是一个对并行计算非常依赖的运算。小熊在线www.beareyes.com.cn

Solve Collisions
我们看到,物理运算所需的 大量并行计算正是GPU所具备的优势,利用GPU做物理运算确实是天经地义的事,那么是不是说物理计算目前就是该由GPU来负责呢?在回答这个问题之前我 们先来看一下NVIDIA在近期发布的PhysX驱动,搭配PhysX驱动在运行3DMark Vantage CUP测试第二个场景的时候,由于GPU接替(或者说是加速)物理运算,使这个场景成绩暴增,可以看出GPU取代CPU物理加速时的决定性优势,而在 NVIDIA最新发布虚幻3物理地图演示中,我们却可以看到如下的成绩:
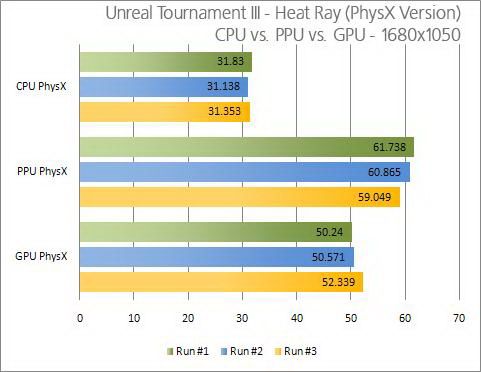
1680×1050
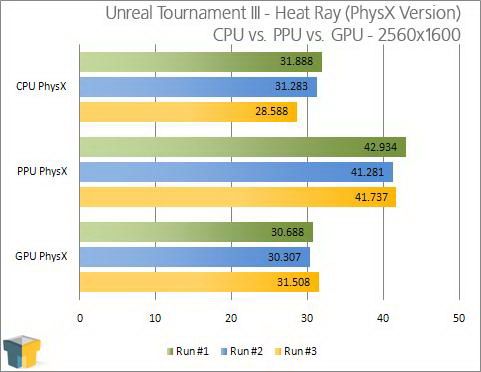
2560×1600
GPU进行物理加速在进行 很少使用到图形渲染的3DMark Vantage CPU测试第二个场景,以及较低分辨率下进行游戏时,GPU物理加速确实效果令人满意,但是随着分辨率的增加,GPU物理加速在游戏中的表现就不在我们想 象的那样完美,对比CPU加速,有些场景甚至还有成绩的下降!
这是游戏中GPU与CPU 的关系决定的,在游戏中,显卡大多数时候都是在满负荷运行,这时根本无暇分身做物理运算!那么这时CPU在做什么?游戏是非抢占型程序,也就是说如果一般 游戏不会全部榨干CPU性能,所以我们在进行游戏时经常看到CPU的占用率并非100%,如果是4核CPU而游戏又不支持多核的话,那么这时CPU的性能 就在浪费!
实际的情况已经很明 了,GPU确实非常做物理运算,但是实际情况却是GPU心有余而力不足,利用目前闲置的CPU来做物理加速似乎是最好的选择,而如果我们有两块显卡的话也 许就解决了GPU自顾不暇的问题,这是不是让你想到了当初NVIDIA及AMD-ATI都不约而同选择Havok FX物理加速的原因——一块显卡做图形渲染,一块显卡做物理加速!
今后物理的发展最终走向何方?也许会是GPU强大到做物理加速如现在的视频解码,也许是今后游戏继续榨干显卡的性能,由多核CPU闲暇来做物理计算,也许是Fusion的CPU+GPU协同操作,总之,一切皆有可能,我们拭目以待……