转自:http://hxraid.iteye.com/blog/647759 ,原文源代码是c++,个人改成java.另外增加一些自己理解。
全依赖“比较”操作的排序算法时间复杂度的一个下界O(N*logN)。但确实存在更快的算法。这些算法并不是不用“比较”操作,也不是想办法将比较操作的次数减少到 logN。而是利用对待排数据的某些限定性假设 ,来避免绝大多数的“比较”操作。桶排序就是这样的原理。
桶排序的基本思想
假设有一组长度为N的待排关键字序列K[1....n]。首先将这个序列划分成M个的子区间(桶) 。然后基于某种映射函数 ,将待排序列的关键字k映射到第i个桶中(即桶数组B的下标 i) ,那么该关键字k就作为B[i]中的元素(每个桶B[i]都是一组大小为N/M的序列)。接着对每个桶B[i]中的所有元素进行比较排序(可以使用快排)。然后依次枚举输出B[0]....B[M]中的全部内容即是一个有序序列。
[桶—关键字]映射函数
bindex=f(key) 其中,bindex 为桶数组B的下标(即第bindex个桶), k为待排序列的关键字。桶排序之所以能够高效,其关键在于这个映射函数,它必须做到:如果关键字k1<k2,那么f(k1)<=f(k2)。也就是说B(i)中的最小数据都要大于B(i-1)中最大数据。很显然,映射函数的确定与数据本身的特点有很大的关系,我们下面举个例子:
假如待排序列K= {49、 38 、 35、 97 、 76、 73 、 27、 49 }。这些数据全部在1—100之间。因此我们定制10个桶,然后确定映射函数f(k)=k/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序后得到如下图所示:
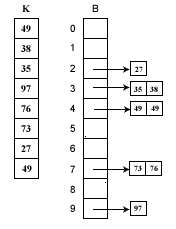
对上图只要顺序输出每个B[i]中的数据就可以得到有序序列了。
桶排序代价分析
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的f(k)值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块(桶)。然后只需要对桶中的少量数据做先进的比较排序即可。
对N个关键字进行桶排序的时间复杂度分为两个部分:
(1) 循环计算每个关键字的桶映射函数,这个时间复杂度是O(N)。
(2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,其时间复杂度为 ∑ O(Ni*logNi) 。其中Ni 为第i个桶的数据量。
很显然,第(2)部分是桶排序性能好坏的决定因素。尽量减少桶内数据的数量是提高效率的唯一办法(因为基于比较排序的最好平均时间复杂度只能达到O(N*logN)了)。因此,我们需要尽量做到下面两点:
(1) 映射函数f(k)能够将N个数据平均的分配到M个桶中,这样每个桶就有[N/M]个数据量。
(2) 尽量的增大桶的数量。极限情况下每个桶只能得到一个数据,这样就完全避开了桶内数据的“比较”排序操作。当然,做到这一点很不容易,数据量巨大的情况下,f(k)函数会使得桶集合的数量巨大,空间浪费严重。这就是一个时间代价和空间代价的权衡问题了。
对于N个待排数据,M个桶,平均每个桶[N/M]个数据的桶排序平均时间复杂度为:
O(N)+O(M*(N/M)*log(N/M))=O(N+N*(logN-logM))=O(N+N*logN-N*logM)
当N=M时,即极限情况下每个桶只有一个数据时。桶排序的最好效率能够达到O(N)。
总结: 桶排序的平均时间复杂度为线性的O(N+C),其中C=N*(logN-logM)。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。 当然桶排序的空间复杂度 为O(N+M),如果输入数据非常庞大,而桶的数量也非常多,则空间代价无疑是昂贵的。此外,桶排序是稳定的。
其实我个人还有一个感受:在查找算法中,基于比较的查找算法最好的时间复杂度也是O(logN)。比如折半查找、平衡二叉树、红黑树等。但是Hash表却有O(C)线性级别的查找效率(不冲突情况下查找效率达到O(1))。大家好好体会一下:Hash表的思想和桶排序是不是有一曲同工之妙呢?
==可参考HashMap的java实现,大概实现如下:数组+链表;数组里面放Entry,每个数组元素都是一个Entry,Entry是一个链表,链接中存放key和value,和下一个Entry和hash值。一对key,value对中,对key进行指定的hash函数(对应与bucket Sort的映射函数),放到对应的Entry中,而后加入Entry的放到链表头部(所以hashCode相同的Objcet未必相同,而后根据equals确定唯一元素,所以调用equals方法相同的对象要求必须hashCode相同),放到Entry中的数据有key,value,next Entry,hash.
==个人感觉思想是类似的,只是用途不同,场景不同。桶排序场景比较苛刻,桶的划分和数量是关键。HashTable主要用来快速查找,所以HashMap的Entry几乎是顺序无关的。还有,两者理想情况就是使hash函数和映射函数,把所有的元素尽可能的分离开来,最好就是一个桶或Entry很少数据。
桶排序在海量数据中的应用
一年的全国高考考生人数为500 万,分数使用标准分,最低100 ,最高900 ,没有小数,你把这500 万元素的数组排个序。
分析:对500W数据排序,如果基于比较的先进排序,平均比较次数为O(5000000*log5000000)≈1.112亿。但是我们发现,这些数据都有特殊的条件: 100=<score<=900。那么我们就可以考虑桶排序这样一个“投机取巧”的办法、让其在毫秒级别就完成500万排序。
方法:创建801(900-100)个桶。将每个考生的分数丢进f(score)=score-100的桶中。这个过程从头到尾遍历一遍数据只需要500W次。然后根据桶号大小依次将桶中数值输出,即可以得到一个有序的序列。而且可以很容易的得到100分有***人,501分有***人。
实际上,桶排序对数据的条件有特殊要求,如果上面的分数不是从100-900,而是从0-2亿,那么分配2亿个桶显然是不可能的。所以桶排序有其局限性,适合元素值集合并不大的情况。
源代码
import java.util.Random;
/**
*
* @author ihyperwin
*
*/
public class BucketSort {
public static int[] demoArray = new int[100];
static{
for(int i=0;i<100;i++){
Random random = new Random();
demoArray[i]=random.nextInt(99);
}
}
public static void main(String[] args) {
System.out.println("排序前:");
for(int i=0;i<100;i++){
System.out.print(demoArray[i]);
if(i!=99){
System.out.print(",");
}
}
System.out.println();
System.out.println("排序后:");
Node[] nodeArray = bucketSort(demoArray);
for(int i=0;i<nodeArray.length;i++){
if(nodeArray[i]!=null){
Node p =nodeArray[i];
while(p!=null){
if(p.key!=-1){
System.out.print(p.key+",");
}
p=p.next;
}
}
}
}
private static Node[] bucketSort(int[] demoArray) {
int n=demoArray.length;
Node[] nodeArray = new Node[10];
for(int i=0;i<nodeArray.length;i++){
nodeArray[i]=new Node(-1);
}
for(int i=0;i<n;i++){
int pos=mappingMethod(demoArray[i]);
Node p=nodeArray[pos];
Node node = new Node(demoArray[i]);
while(p.next!=null&&p.next.key<=node.key) p=p.next;
node.next=p.next;
p.next=node;
}
return nodeArray;
}
private static int mappingMethod(int i){
return i/10;
}
}
//单向链表节点
class Node{
public int key;
public Node next;
Node(int key,Node next){
this.key=key;
this.next=next;
}
Node(int key){
this.key=key;
}
}
上面源代码的桶内数据排序,我们使用了基于单链表的直接插入排序算法。可以使用基于双向链表的快排算法提高效率。