memcached-分布式缓存服务器
Memcached在很多时候都是作为数据库前端cache使用的。
因为它比数据库少了很多SQL解析、磁盘操作等开销,而且它是使用内存来管理数据的,所以它可以提供比直接读取数据库更好的性能,在大型系统中,访问同样的数据是很频繁的,memcached可以大大降低数据库压力,使系统执行效率提升。另外,memcached也经常作为服务器之间数据共享的存储媒介,例如在SSO系统中保存系统单点登陆状态的数据就可以保存在memcached中,被多个应用共享。
memcached号称“分布式缓存”,其实他的分布式体现在客户端的实现上。它具有以下的特点:
1,协议简单
2,基于libevent的时间处理
3,内置内存存储方式
4,memcached不互通信的分布式
memcached在服务器上以进程启动,客户端通过网络通信跟其进行交互,java里的memcached实现有用mina来做网络这一块实现的。在客户端只需要调用简单的API,数据就被缓存起来了。当然了memcached由于使用的是内存缓存数据,所以重启机器必然导致数据的丢失,但是有些插件之类的,也支持将数据做一定的持久化。memcached的性能非常优秀,基本上不怎么消耗CPU资源。大部分局限在网络这一块的数据传输。
memcached的内部数据存储
默认情况下采用Slab Allocation的机制分配管理内存。采用的是slab class-chunks-chunk,已解决内存碎片的问题。把分配的空间划分成一块块不同大小的空间块组,将相同大小的快分成组。这些块的大小也是可以配置的。过大过小都不合适,需要根据自己缓存的内容大小进行权衡,通过制定Growth Factor进行控制。如下图为Slab Allocation的构造图:

memcached的数据删除算法
默认采用LRU算法,当空间不足时,会选择最近早少使用的缓存数据进行失效。
memcached的分布式算法
服务器端负责存储数据,给出数据,客户端负责分布式算法。简单的通过对应用传过来的键进行hash后,对服务器的节点数相除后,得到要保存的节点,所以数据其实是分散到很多机器上的。但是这种算法有一定的弊端,当增加缓存服务节点后,会导致缓存效果瞬间降低,导致对数据库的压力骤增,很有可能把数据库高挂掉。

所以后来提出了一致性hash的算法,来解决这个问题。
一致性哈希(Consistent Hashing)
在此我们采用了一种新的方式来解决问题,处理服务 器的选择不再仅仅依赖key的hash本身而是将服务实例(节点)的配置也进行hash运算。
- 首先求出每个服务节点的hash,并将其配置到一个0~2^32的圆环(continuum)区间上。
- 其次使 用同样的方法求出你所需要存储的key的hash,也将其配置到这个圆环(continuum)上。
- 然后从数据映射到的位置开始顺时针 查找,将数据保存到找到的第一个服务节点上。如果超过2^32仍然找不到服务节点,就会保存到第一个memcached服务节点上。
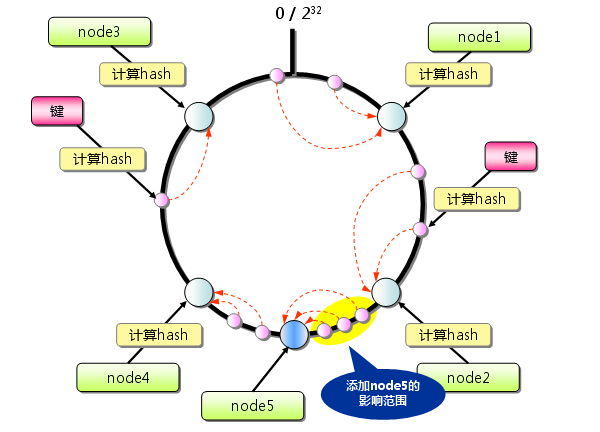
因此Consistent Hashing最大限度地抑制了键的重新分布。而且,有的Consistent Hashing的实现方
法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。
因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样
就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是,由
服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
(1 n/(n+m)) * 100
阅读了一篇日本人写的剖析文章,见附件。