Cassandra Dev 2: Cassandra入门(续) - Cassandra Cluster
5. Cassandra CLI
一般数据库服务器都会提供一个Command Line 客户端操作界面,如Mysql、Oracle等,当然The Cassandra Distributed database 也提供了一个CLI客户端,来控制服务器,接下来简单说说Cassandra CLI。说之前先说一个常见Exception,在apache-cassandra-0.6.4\bin目录下有一个cassandra-cli.bat文件,此文件为可执行脚板,单击它会进入Cassandra CLI,但是单击是会报一个ClassNotFound的异常:
我的解决办法是在系统变量中添加Cassandra环境变量,如下:![]()
如上,变量名为CASSANDRA_HOME,变量值为Cassandra的安装目录,添加完成后点击apache-cassandra-0.6.4\bin目录下cassandra-cli.bat,进入Cassandra CLI窗口。可以通过help命令来查看帮助,如下:
通过Cassandra CLI 我们可以对Cassandra基本配置信息进行查询,也可以服务器中数据进行增、删改、查,如下查询前面4 数据模型中添加到服务器的数据: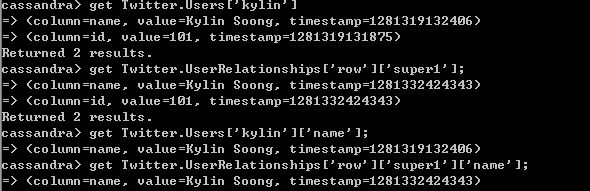
让然也可以插入数据,如下:
6 配置一个简单的Cassandra Cluster
Cassandra Cluster也叫Cassandra 集群,集群的意思就是把一堆Cassandra 结点集合在一起。为什么要进行Cassandra 集群呢?为了提高容错能力使数据能够在多个结点间自动复制;为了支持在多个数据中心之间的复制;为了以零故障时间替换错误的结点,所以Cassandra 集群是必要的;
有前面4中Cassandra 数据模型中我们已经知道,Cassandra 数据模型可以知道,Cluster是Cassandra数据模型最大的概念,它里面可以包括多个Keyspace,所以,一个集群应该有唯一的ClusterName,之所以说这句话是因为我在实验室遇到这样的问题,下面开始配置我们的集群:
我用了三台计算机(IP分别:192.168.67.118,192.168.67.167,192.168.67.185),操作系统都为Windows,在三台计算机上都安装JDK后,安装Cassandra,配置集群相当简单,只对Cassandra配置文件storage-conf.xml做一修改,以192.168.67.118上的服务器为例,说明配置文件的修改:
Step one: 确定一个唯一的ClusterName,三台计算机上名字都应该相同:
<ClusterName>Kylin PC</ClusterName>
Step two: 添加Cassandra联系结点:
<Seeds>
<Seed>192.168.67.118</Seed>
<Seed>192.168.67.137</Seed>
<Seed>192.168.67.185</Seed>
</Seeds>
Step three:修改它的监听地址:
<ListenAddress>192.168.67.118</ListenAddress>
Step four:修改Thrift远程调运控制端口:
<ThriftAddress>0.0.0.0</ThriftAddress>
0.0.0.0说明可以通过RPC控制整个Cluster;
到此192.168.67.118上Cassandra 集群配置完成,另为两台配置类似,配置完成后,我们先启动192.168.67.137,接着192.168.67.118,最后192.168.67.185。Cassandra 集群中所有结点组成一个环,下面我们先验证这一结论:
(一)Cassandra Ring
Cassandra 提供了NodeTool 工具可以帮助我们验证Cassandra Ring,进入apache-cassandra-0.6.4\bin目录,运行可以执行文件nodetool.bat,如下图所示:
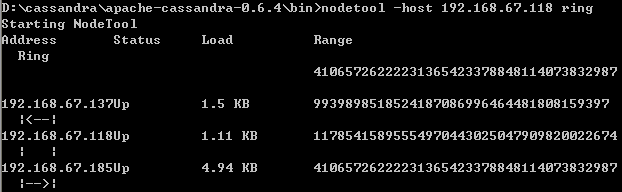
如上图显示的是我们刚才配置的一个集群。
(二)Cassandra Cluster结点间自动复制验证
测试复制之前,每个结点(三台计算机)配置文件中都必须有名为Twitter的keyspace配置信息,如下:
<Keyspace Name="Twitter"> <ColumnFamily CompareWith="UTF8Type" Name="Statuses" /> <ColumnFamily CompareWith="UTF8Type" Name="StatusAudits" /> <ColumnFamily CompareWith="UTF8Type" Name="StatusRelationships" CompareSubcolumnsWith="TimeUUIDType" ColumnType="Super" /> <ColumnFamily CompareWith="UTF8Type" Name="Users" /> <ColumnFamily CompareWith="UTF8Type" Name="UserRelationships" ColumnType="Super" /> <ReplicaPlacementStrategy>org.apache.cassandra.locator.RackUnawareStrategy</ReplicaPlacementStrategy> <ReplicationFactor>1</ReplicationFactor> <EndPointSnitch>org.apache.cassandra.locator.EndPointSnitch</EndPointSnitch> </Keyspace>
向192.168.67.118上Twitter中Users中添加一行如下图:
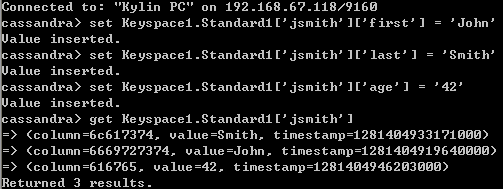
上图显示添加完并访问,及访问结果;
通过Cassandra CLI连接到192.168.67.185,访问刚才添加数据,显示结果如下:

通过Cassandra CLI连接到192.168.67.137,访问刚才添加数据,显示结果如下:
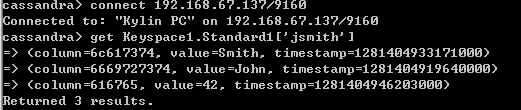
如上为对Cassandra Cluster结点间自动复制验证。此验证也说明了Cassandra的分散性,Cassandra集群中的每个Node都是相同的,没有网络瓶颈,没有单个结点的失败;
(三)Cassandra Token
每个结点需要指定一个唯一的Token,用来确定数据的第一个副本存储在那个结点。Token还决定了每个节点存储的数据的分布范围,每个节点保存的数据的key在(前一个节点Token,本节点Token]的半开半闭区间内,所有的节点形成一个首尾相接的环。
Cassandra 在读写过程中,所有的key都会被org.apache.cassandra.utils.FBUtilities类中的hash()方法生成一个0至2^127的BigInteger,为什么是0至2^127之间呢?我们看一下Cassandra配置文件:
<Partitioner>org.apache.cassandra.dht.RandomPartitioner</Partitioner>
该配置决定Cassandra采取的分区方法为RandomPartitioner,是一种hash分区策略,Cassandra采用了MD5作为hash函数,其结果是128位的整数值(其中一位是符号位,Token取绝对值为结果)。
下面我们抽出org.apache.cassandra.utils.FBUtilities中hash方法做一研究:
import java.math.BigInteger;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Scanner;
public class FBUtilitiesTest {
public static byte[] hash(String type, byte[]... data){
byte[] result = null;
try {
MessageDigest messageDigest = MessageDigest.getInstance(type);
for(byte[] block : data) {
messageDigest.update(block);
result = messageDigest.digest();
}
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return result;
}
public static BigInteger hash(String data){
byte[] result = hash("MD5", data.getBytes());
BigInteger hash = new BigInteger(result);
return hash.abs();
}
public static void main(String[] args) {
String key1 = "Keyspace1.Standard1['jsmith']['first']";
String key2 = "Keyspace1.Standard1['jsmith']['last']";
String key3 = "Keyspace1.Standard1['jsmith']['age']";
System.out.println(key1 + " --> " + hash(key1));
System.out.println(key2 + " --> " + hash(key2));
System.out.println(key3 + " --> " + hash(key3));
}
}
运行代码结果可以看到之前我们用过的3个Key对应的生成BigInteger:
Keyspace1.Standard1['jsmith']['first'] --> 41517583996867145143721563973314343759 Keyspace1.Standard1['jsmith']['last'] --> 137920484341259279728204980582657924512 Keyspace1.Standard1['jsmith']['age'] --> 152603099849264011049197911814624435083
说明,关于Token,我是没有怎么完全弄清楚,等以后弄明白在做解释。
这里给几个链接,帮助学习Token:
http://www.ningoo.net/html/2010/cassandra_token.html
http://wiki.apache.org/cassandra/Operations
7. Cassandra Write
先给出一个图:
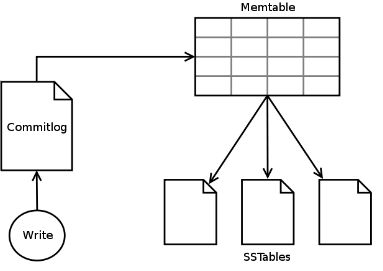
如图所示了Cassandra write data的全过程:先写日志文件Commitlog,然后数据才会写到ColumnFamily在内存中对应的Memtable,内存中Memtable达到一定条件后批量Flush到磁盘,存储为SSTable。
Commitlog
(1) 文件存放位置是在Cassandra配置文件中指定的,此文件的作用是确保异常情况下,根据持久化的SSTable和 Commitlog重构内存中Memtable内容;
(2) 当一个Commitlog文件写满后会自动新建一个Commitlog文件;
(3) 当旧的Commitlog文件文件不在需要时,这个Commitlog文件会自动清除;
Memtable
(1) 是一种memory结构,每个ColumnFamily对应一个Memtable;
(2)Memtable里内容按照key排序,这样使随机IO写编程顺序IO写,降低了大量的写操作对存储系统的压力;
(3)内存中Memtable达到一定条件后批量Flush到磁盘,存储为SSTable,下一个Memtable又需要刷新时刷新到一个新的SSTable,即每次刷新产生一个新的SSTable;
SSTable
(1)文件存放位置同样是在Cassandra配置文件中指定的;
(2) 按照key排序后(在Memtable中完成)存储key/value字符串;
(3)SSTable一旦写入就不能改变,只能读取;另为避免大量SSTable带来性能影响,定期将SSTable合并成一个SSTable,称之为Compaction,由于每个SSTable中key都排好了顺序,因此只需做一次合并顺序就可以完成任务;
(4)SSTable的data目录,如下图

如图Users为ColumnFamily名字,1为序号,Users-1-Data.db是SSTable的数据文件,存储排好顺序的key/value字符串;Users-1-Filter.db为Bloom Filter算法生成的映射文件(Bloom Filter算法:快速定位待查询key所属的SSTable),Users-1-Index.db为索引文件,保存key在数据文件中的偏移量;
8. Cassandra Read
同样,先给出一个图;
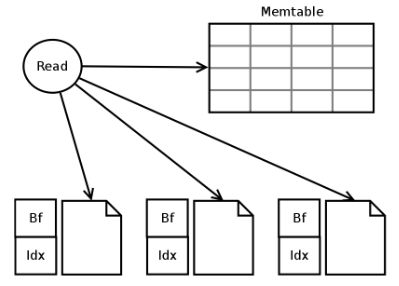
读取数据时,需要合并读取ColumnFamily对应的所有SSTable和Memtable;
Bf确定待查找key所在的SSTable;
Idx确定key在SSTable中的偏移量。