IEBCOMP 和 IEHLIST
IEBCOMP
IEBCOMPR 程序用于在两个数据集的逻辑记录间进行比较,这两个数据集可以是顺序
数据集、分区数据集或扩展分区数据集。它能对数据集或数据集成员的定长、变长、组块
非组块或未定义记录进行比较。但它不能对加载模块进行比较。
两个顺序数据集比较相同,是指它们含有相同数量的记录且相关记录和关键字完全相
同。而两个分区数据集或两个扩展分区数据集比较相同,则是指:
( 1 )相关成员含有相同的记录;
( 2 )注释列表在相关成员的位置相同;
( 3 )相关记录和关键字完全相同;
( 4 )相关目录和用户数据区完全相同。
对于相同的数据集必须同时满足这些条件,否则不能视其为相同数据集。
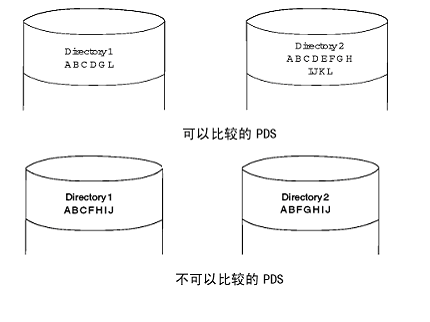
需要注意的是,对于分区数据集和扩展分区数据集,只有其中一个数据集的所有目录项
名字在另一个数据集的目录中都能找到相同的目录项名时,才能进行比较。否则是不能比较的。 如图所示:
下面是关于 IEBCOMPR 程序语句的列表:
| 语 句 |
功 能 |
| JOB |
作业开始 |
| EXEC |
定义程序名 PGM=IEBCOMPR |
| SYSPRINT DD |
指定系统输出数据集 |
| SYSUT1 DD |
定义需要比较的数据集 |
| SYSUT2 DD |
定义需要比较的数据集 |
| SYSIN DD |
定义控制数据集或 DUMMY ,控制语句可以是 COMPARE 、 EXITS 、 LABELS |
控制语句说明:
COMPARE : 定义数据集的组织结构,在 SYSIN DD 中设置控制语句时,它必须是
第一个控制语句,当输入数据集是分区数据集或扩展分区数据集时,必须设置这个语句,语句格式如下:
label COMPARE TYPROG={PS/PO}
其中 TYPROG={PS/PO} 用于指定输入数据集的组织结构, PS 表示输入数据集为顺序数据集,为缺省值; PO 表示输入数据集是分区数据集或扩展分区数据集。
EXITS : 定义用户所用的出口例程。当用户调用出口例程时,需要用该语句。当设置多
个 EXITS 时, IEBCOMPR 将只用最后一个。 EXITS 的语句格式为:
label EXITS INHDR= 例程名
,INTLR= 例程名
,ERROR= 例程名
,PRECOMP= 例程名
其中“ INHDR= 例程名”指定处理用户输入头标的例程名;“ INTLR= 例程名”指定处理
用户输入尾标的例程名;“ ERROR= 例程名”指定出错处理接收控制的例程名;
“ PRECOMP= 例程名”指定一个例程名,该例程在 IEBCOMPR 比较输入数据集之前对逻辑
记录进行处理。
LABELS : 指定是否将用户标号作为数据来处理,当设置多个 LABELS 语句时,
IEBCOMPR 程序只用最后一个, LABELS 语句的格式为:
label LABELS DATA={YES | NO | ALL| ONLY}
其中 DATA= {YES | NO | ALL| ONLY} 指明是否将用户标号作为数据处理。 DATA 的取
值如下:
YES :所有用户标号都作为数据处理,并依照返回码,将标号作为数据终止来处理,该
值为缺省值。
NO :仅将用户标号作为数据处理。
ALL :所有用户标号作为数据处理, 16 中返回码将使 IEBCOMPR 程序完成剩余用户标
号组的处理并终止作业步。
ONLY :只用用户头标作为数据处理,处理时不管是否有返回码。
例 1 . 比较两个分区数据
//DISKDISK JOB …
//STEP1 EXEC PGM=IEBCOMPR
//SYSPRINT DD SYSOUT=A
//SYSUT1 DD DSN=PDSSET1,UNIT=disk,DISP=SHR,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=2000),
// VOLUME=SER=111112
//SYSUT2 DD DSN=PDSSET2,UNIT=disk,DISP=SHR
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=2000)
//SYSIN DD *
COMPARE TYPROG= PO
/*
在上例中, SYSUT1 DD 语句定义输入数据集( PDSSET1 ),这是个组块数据集,它驻
留在磁盘卷上。 SYSUT2 DD 语句定义另一个输入数据集( PDSSET2 ),它也是个驻留在磁
盘卷上的块组数据集。 SYSIN DD 语句定义流内控制数据集,其中的控制语句表示两个输入
数据集是分区数据集。
例 2. 比较磁带上的两个顺序数据集
//TAPETAPE JOB ...
// EXEC PGM=IEBCOMPR
//SYSPRINT DD SYSOUT=A
//SYSUT1 DD DSNAME=SET1,LABEL=(2,SUL),DISP=(OLD,KEEP),
// VOL=SER=001234,DCB=(DEN=2,RECFM=FB,LRECL=80,
// BLKSIZE=2000,TRTCH=C),UNIT=tape
//SYSUT2 DD DSNAME=SET2,LABEL=(,SUL),DISP=(OLD,KEEP),
// VOL=SER=001235,DCB=(DEN=2,RECFM=FB,LRECL=80,
// BLKSIZE=2000,TRTCH=C),UNIT=tape
//SYSIN DD *
COMPARE TYPORG=PS
LABELS DATA=ONLY
/*
SYSUT1 DD 定义了一个输入数据集 SET1 。该数据集在一个有标号( labeled )的、 7 轨
磁带卷上。
SYSUT2 DD 定义了一个输入数据集 SET2 。该数据集在一个有标号( labeled )的、 7
轨磁带卷上。它是该磁带上第一个或者唯一一个数据集。
SYSINDD 后的控制语句 COMPARE TYPORG=PS 表明输入数据集是顺序数据集;
LABELS DATA=ONLY 表明用户首标( header labels )被当作数据加以比较,而磁带上的其
他标号则予以忽略。


IEHLIST
IEHLIST 程序用于系统信息列表,其中包括分区数据集目录列表、 VTOC 列表以及编目
列表等。 下面是它的应用实例:
//LIST EXEC PGM=IEHLIST
//SYSPRINT DD SYSOUT=*
//D1 DD UNIT=SYSDA,VOL=SER=PACK11,DISP=OLD
//D2 DD UNIT=SYSDA,VOL=SER=PACK12,DISP=OLD
//D3 DD UNIT=SYSDA,VOL=SER=PACK17,DISP=OLD
//SYSIN DD *
LISTCTLG VOL=SYSDA=PACK12
LISTVTOC VOL=SYSDA=PACK11,DSN=(USER.F1)
LISTPDS VOL=SYSDA=PACK17,DSN=U1.LIB
/*
注意: DD 语句中的 VOL 和 UNIT 参数的设置要与 SYSIN DD 中控制语句的相关参数一致。
IEHLIST 中 SYSIN DD 语句定义控制数据集:
IEHLIST 的控制语句:
- LISTVTOC
- LISTCTOG
- LISTPDS DSNAME=(pdsname,pdsname)
-显示格式: DUMP or FORMAT
-控制语句中的 DSNAME 不能简写成 DSN
-控制语句中的 VOL 参数格式为:
VOL=XXXXXXX=YYYYYYY ,其中 XXXXXXXXX 是 DD 语句中的 UNIT 参数指定的值,而 YYYYYYY 是 SER 参数指定的值。例如:
VOL=SYSDA=USER01 or VOL=3390=USER01


DFSORT
DFSORT 程序用于数据排序 ,下面是它的应用实例:
//STEP1 EXEC PGM=DFSORT
//SYSIN DD *
SORT FIELDS=(1,10,CH,A)
//SORTIN DD DSN=TEST.LOG,DISP=OLD
//SORTOUT DD DSN=SORT.LOG,DISP=(NEW,PASS),
// UNIT=SYSDA,SPACE=(CYL,1)
//SORTWK1 DD UNIT=SYSDA, SPACE=(CYL,1)
STEP1 语句用于调用 DFSORT 程序; SYSIN DD 语句定义控制数据集,其中控制语句
SORT FIELDS=(1,10,CH,A) 指出要排序的内容始于输入数据的第一个位置,以递增前 10 字符进行排序; SORTIN DD 语句给出用于排序的输入数据集名和状态;
SYSOUT DD 语句为排序的输出结果指定数据集;
SORTWK1 DD 语句为排序操作分配工作空间。
IEBUPDTE
Original URL: http://bluemainframe.net/2007/06/05/iebupdte/
IEBUPDATE 这个 UTILITY 最常见的用法是用来在分区数据集中创建多个 member ,或者更新这些 member 中的数据。虽然 IEBUPDATE 能够用来处理给中类型的数据,但是主要用途还是创建或者维护 JCL 的过程库或者汇编语言的宏程序库。今天,这个 UTILITY 大多用来做程序产品的发布和维护了。很少被普通 TSO 用户使用。
这里有一个很基本的例子用来往 MY.PROCLIB 中添加两个 JCL 的过程的 MEMBER 。运用 ISPF 也许能够很方便的完成这些事情,但是如果我们假设这个 JOB 已经在磁带上了,那么很显然就会比 ISPF 操作更加有效。
//OGDEN10 JOB 1,BILL,MSGCLASS=X
// EXEC PGM=IEBUPDTE
//SYSPRINT DD SYSOUT=*
//SYSUT1 DD DISP=OLD,DSN=MY.PROCLIB
//SYSUT2 DD DISP=OLD,DSN=MY.PROCLIB
//SYSIN DD DATA
./ ADD LIST=ALL,NAME=MYJOB1
//STEP1 EXEC=BILLX1
//PRINT DD SYSOUT=A
// (more JCL for MYJOB1)
//SYSUDUMP DD SYSOUT=* (last JCL for MYJOB1)
./ REPL LIST=ALL,NAME=LASTJOB
//LIST EXEC PGM=BILLLIST
// (more JCL for this procedure)
//* LAST JCL STATEMENT FOR LASTJOB
./ ENDUP
/*
对这个例子进行一下说明:
这是一个更新数据集的过程,所以 SYSUT1 和 SYSUT2 都指向了同一个数据集。如果指向不同的话,那么就会是一个先复制然后再更新的过程。
从 SYSIN DD DATA 的格式来看,输入流的前两列会有 // 表示,它并不会被 JCL 语句打断。输入流的结尾会有 /* 的标识。 IEBUPDATE 的 UTILITY 控制语句由 ./ 来引导。
一个名为 MYJOB1 的 MEMBER 被加入到 MY.PROCLIB 中。而且这个 MEMEBER 并不需要已经存在。而已经存在的 MEMBER LASTJOB 就会被新的内容替换掉。
另外, IEBUPDATE 这个 UTILITY 还能够根据控制语句中的序列号来添加或者替换相应的 MEMBER 。这也是针对 JCL 语句或者源语句中那些数字序列的所剩不多的用法。
最后我们需要再次重申 IEBUPDATE 最有代表性的用法是用作程序的发布和维护 。比方说,如果需要给客户的程序库中添加 25 个 JCL 过程,我们只需要将这 25 个过程作为一个程序包用 IEBUPDATE 导入。这样做的一个好处是由于所有的产品都使用一种源程序格式,客户就可以很方便的在使用之前进行审核。